- The paper introduces a four-dimensional framework that organizes QE methods by injection, grounding, learning, and KG augmentation, providing systematic analysis.
- The paper contrasts traditional techniques with PLM/LLM-based methods, demonstrating improved contextual sensitivity, recall, and precision in diverse IR scenarios.
- The paper addresses open challenges such as hallucination and efficiency, and recommends robust alignment, evaluation, and fairness measures for practical implementations.
Query Expansion in the Age of Pre-trained and LLMs: A Comprehensive Survey
Introduction and Motivation
Query expansion (QE) is a foundational technique in information retrieval (IR) for mitigating vocabulary mismatch between user queries and relevant documents. The proliferation of short, ambiguous queries—especially in mobile, voice, and conversational interfaces—has exacerbated the semantic gap, while corpora have grown in scale and diversity. Traditional QE methods, including pseudo-relevance feedback (PRF), thesaurus/ontology-based expansion, and log-driven reformulation, have well-documented limitations: context insensitivity, topic drift, and poor generalization to novel or long-tail queries. The advent of pre-trained LLMs (PLMs) and LLMs has fundamentally altered the QE landscape, enabling context-aware, generative, and controllable expansion strategies that address many of these deficiencies.
Taxonomy and Framework for Query Expansion
The survey introduces a four-dimensional framework for organizing QE methods in the PLM/LLM era:
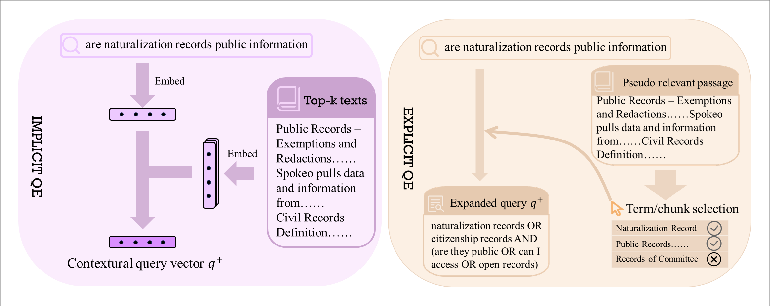
- Point of Injection: Distinguishes between implicit (embedding-level) and explicit (term/text-level) expansion.
- Grounding and Interaction: Considers the source of expansion signals (model-internal, corpus, knowledge graph) and the degree of interaction (single-pass vs. iterative).
- Learning and Alignment: Covers training regimes, including supervised fine-tuning (SFT), parameter-efficient fine-tuning (PEFT), and direct preference optimization (DPO).
- Knowledge Graph (KG) Augmentation: Explores the integration of structured knowledge for entity disambiguation and coverage.
This taxonomy enables systematic comparison and principled selection of QE techniques for diverse IR scenarios.
Traditional vs. PLM/LLM-Based Query Expansion
Traditional QE methods rely on static resources (e.g., WordNet, UMLS), corpus-wide co-occurrence statistics, or user logs. These approaches are efficient and interpretable but lack deep contextualization and struggle with ambiguity and domain adaptation. In contrast, PLM/LLM-based QE leverages parametric knowledge acquired through large-scale pretraining, enabling context-sensitive disambiguation, zero/few-shot expansion, and generative reformulation.
Key Contrasts:
- Knowledge Source: Static vs. parametric and adaptable.
- Contextual Sensitivity: Isolated terms vs. sequence-level semantics.
- Retrieval Dependence: High dependence on initial ranking vs. reduced dependence via generative expansion.
- Computational Cost: Lightweight vs. resource-intensive.
- Domain Adaptability: Domain-specific resources vs. cross-domain generalization.
- Retrieval Effectiveness: Recall–precision trade-off vs. simultaneous gains in both.
- Integration Complexity: Plug-and-play vs. infrastructure-heavy.
PLM/LLM-Driven QE Techniques
Implicit (Embedding-Based) QE
Implicit QE methods enhance the query representation in latent space without emitting new terms. Representative approaches include:
- ANCE-PRF: Refines the query vector using PRF with a dedicated encoder, yielding consistent improvements in dense retrieval.
- ColBERT-PRF: Injects discriminative token centroids from feedback documents, improving late interaction models.
- Eclipse: Reweights embedding dimensions based on positive/negative feedback, acting as a latent denoiser.
- QB-PRF: Pools over semantically equivalent query variants, robust to lexical mismatch.
- LLM-VPRF: Updates query vectors with document embeddings from LLM-based retrievers, closing the gap between small and large dense models.
These methods are computationally efficient and avoid hallucination, but their effectiveness is contingent on the quality of the initial retrieval.
Explicit (Selection-Based) QE
Explicit QE methods select salient terms or chunks from pseudo-relevant documents or curated resources:
- CEQE: Context-aware scoring using BERT in an RM3 pipeline.
- SQET: Supervised filtering of term candidates via cross-encoders.
- BERT-QE: Selects and reuses chunks as evidence for re-ranking.
- CQED: Domain-aware term selection for biomedical search, combining general and domain-specific encoders.
- PQEWC: Personalizes expansion using user history and contextual embeddings.
These approaches offer tight control over vocabulary and are amenable to domain and user constraints.
Generative and Grounded QE
Generative QE leverages LLMs to synthesize expansions, with varying degrees of grounding:
Learning and Alignment
Alignment techniques ensure that expansions are utility-driven and cost-effective:
- SoftQE: Distills LLM-generated expansions into student encoders, reducing inference cost.
- RADCoT: Retrieval-augmented distillation of chain-of-thought expansions.
- ExpandR: Alternates retriever training and preference-aligned generation.
- AQE: Aligns LLM outputs with retrieval utility via SFT and DPO.
These methods enable robust, scalable deployment of QE in production systems.
Knowledge Graph-Augmented QE
KG-augmented QE injects structured semantics for entity disambiguation and coverage:
- KGQE: Injects compact KG facts into queries, improving disambiguation.
- CL-KGQE: Combines translation, KG linking, and distributional neighbors for cross-lingual QE.
- KAR/QSKG: Leverage hybrid KG and document graphs for relational expansion, effective in semi-structured domains.
Application Domains
QE is critical across a spectrum of IR applications:
- Web Search: Event-centric and behavioral-signal-driven QE improves recall and intent alignment.
- Biomedical IR: Domain PLMs and ontology-based QE bridge lay–technical vocabulary gaps, with strong gains in precision and recall.
- E-commerce: Generative and taxonomy-aware QE normalizes user queries to catalog attributes, enhancing engagement and conversion.
- Cross-Lingual IR: Multilingual PLMs and KG-based expansion address translation and terminology divergence.
- Open-Domain QA and RAG: QE improves retrieval coverage and answer grounding, reducing hallucination in generation.
- Conversational and Code Search: QE resolves coreference, adapts to evolving intents, and bridges NL–code mismatch.
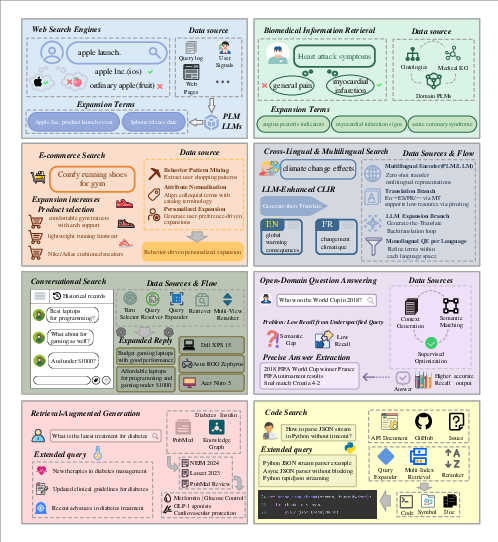
Figure 2: Application scenarios of query expansion in information retrieval, highlighting the integration of QE in web, biomedical, e-commerce, QA, and code search pipelines.
Open Challenges and Future Directions
Despite substantial progress, several challenges persist:
- Reliability on Unfamiliar/Ambiguous Queries: LLM-based QE may hallucinate or collapse onto popular senses; retrieval-augmented prompting and facet-aware diversification are promising remedies.
- Knowledge Leakage and Generalization: Temporal splits and originality diagnostics are needed to assess and mitigate pretraining leakage.
- Expansion Quality Control: Automated vetting, counterfactual checks, and human-in-the-loop editing are essential for high-stakes domains.
- Efficiency and Scalability: Distillation, PEFT, selective invocation, and caching are critical for cost-effective deployment.
- Dynamic Adaptation: Continual retrieval-augmented QE and low-shot domain transfer address evolving terminology and events.
- Evaluation: Expansion-level diagnostics and user-centric measures are required beyond end-to-end IR metrics.
- Fairness and Governance: Exposure parity, robustness audits, and privacy-preserving QE are emerging priorities.
Conclusion
This survey provides a comprehensive synthesis of query expansion in the PLM/LLM era, organizing the field along four analytical dimensions and mapping techniques to practical IR challenges. Empirical evidence demonstrates that PLM/LLM-based QE delivers consistent gains in contextual disambiguation, recall, and precision across domains, but introduces new challenges in reliability, efficiency, and governance. The path forward lies in principled integration of explicit, implicit, and hybrid QE, grounded in corpus and knowledge graph evidence, aligned with retrieval utility, and governed by robust evaluation and fairness criteria. This framework offers a blueprint for future research and deployment of QE in real-world IR systems.