- The paper introduces the KAR framework, which integrates LLMs with knowledge graphs to enhance query expansion in complex retrieval tasks.
- It employs a multi-step process including entity parsing, document retrieval, and relation propagation to incorporate both textual semantics and relational data.
- Experimental results on datasets like AMAZON, MAG, and PRIME demonstrate improved metrics such as Hit@1 and MRR, confirming the method’s robustness and scalability.
Knowledge-Aware Query Expansion with LLMs for Textual and Relational Retrieval
This paper introduces a novel method for query expansion using LLMs augmented with knowledge graphs (KGs) to improve information retrieval tasks that require both textual and relational understanding. The method, termed as Knowledge-Aware Retrieval (KAR), aims to overcome limitations of traditional query expansion techniques by incorporating structured document relations alongside semantic text similarities.
Introduction
Traditional query expansion techniques primarily focus on enhancing semantic similarities between search queries and target documents. However, they often overlook document relations which are crucial for retrieving data in real-world scenarios involving complex queries with both textual and relational elements. The proposed knowledge-aware framework integrates LLMs with KG, allowing for a richer and more nuanced query expansion that captures the necessary relational knowledge.
Methodology
The proposed framework consists of several key steps:
- Entity Parsing by LLM: An LLM extracts explicitly mentioned entities from the initial query. This process includes considering the original query itself as a pseudo entity to anchor retrieval.
- Entity Document Retrieval: For each parsed entity, the associated textual document is retrieved using a text embedding model.
- KG Relation Propagation: The method propagates relations in the knowledge graph by identifying h-hop neighbors, thus capturing the relational context of each entity.
- Document-based Relation Filtering: Utilizing document texts as KG node representations allows for more accurate filtering of query-focused relations versus the traditional entity-name-based approach.
- Knowledge-Aware Expansion: Using LLMs, the framework generates query expansions by synthesizing information from document triples constructed from filtered relations.
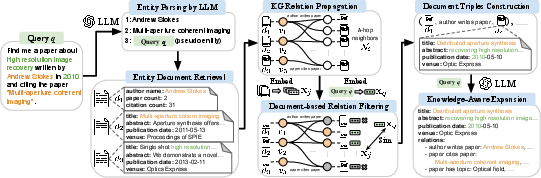
Figure 1: Overview of our knowledge-aware query expansion framework illustrated with an example academic paper search query with textual and relational requirements.
Experimental Evaluation
KAR was evaluated on three datasets from diverse domains within the STARK benchmark: product search (AMAZON), academic paper search (MAG), and precision medicine inquiries (PRIME). The method exhibited superior retrieval performance compared to traditional LLM-based and knowledge-enhanced query expansion techniques, achieving improved metrics such as Hit@1 and MRR across all datasets.
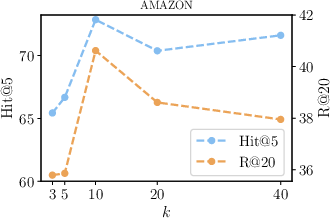
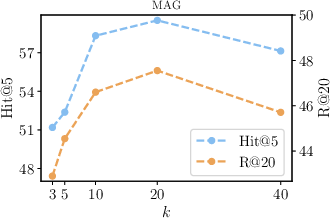
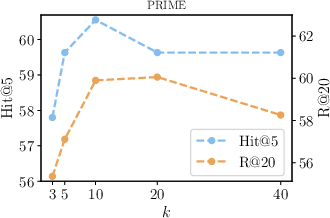
Figure 2: Influence of different values of k for filtered top-k neighbors in KAR.
Figure 3 and Figure 4 further illustrate the performance dependencies on model parameters such as top-k neighbors and the number of sampled query expansions, demonstrating the robustness and scalability of the proposed method.
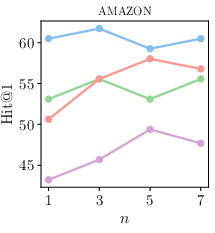
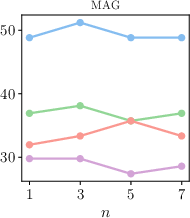
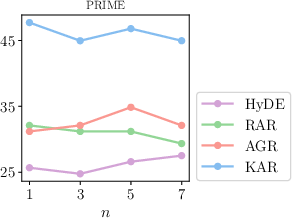
Figure 3: Influence of sampled query expansions n.
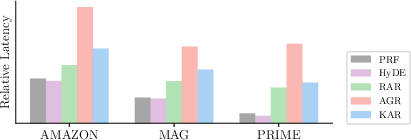
Figure 4: Latency comparison of query expansions.
Discussion
The integration of KGs into LLMs for query expansion addresses both textual and relational gaps, essential for accurate information retrieval in complex query scenarios. The zero-shot capabilities and the minimal additional latency introduced by the KAR framework make it adaptable and scalable for various real-world applications.
Conclusion
The knowledge-aware query expansion method effectively leverages the strengths of LLMs and KGs, providing enhancements for traditional information retrieval across varied datasets with semi-structured data requirements. By bridging semantic and structural gaps, KAR sets a strong foundation for future developments in AI-enhanced retrieval systems.
In summary, KAR demonstrates a promising path forward in addressing the challenging task of complex query expansions by coupling textual and relational knowledge, highlighting the potential of LLM and KG integration for future AI advancements.