- The paper presents the SEELE framework that dynamically adjusts hint length to keep rollout accuracy near 50% for optimal reinforcement learning.
- It utilizes a three-parameter logistic model via item response theory to predict and control the required hint rate in real time.
- Experimental results demonstrate significant gains over baselines on math and general reasoning tasks, highlighting improved learning efficiency and convergence.
Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding: The SEELE Framework
Introduction
The paper introduces SEELE, a supervision-aided reinforcement learning with verifiable rewards (RLVR) framework designed to optimize the reasoning capabilities of LLMs by dynamically aligning problem difficulty with model capability. The central insight is that RLVR training efficiency is maximized when the rollout accuracy is approximately 50%, a regime termed the "sweet spot." SEELE achieves this by adaptively appending hints—partial solutions—to each training instance, with hint length determined in real time via multi-round sampling and item response theory (IRT) modeling. This approach addresses the inefficiencies of static hinting and indiscriminate off-policy guidance in prior methods, enabling instance-level, capability-adaptive difficulty control.
Theoretical Foundation: RLVR Efficiency and Rollout Accuracy
The paper formalizes the relationship between RLVR training efficiency and problem difficulty, using prediction accuracy as the difficulty metric. Through a rigorous derivation, it is shown that the magnitude of loss descent in RLVR is upper bounded by a quadratic function of the rollout accuracy, aθ(x):
L(θold)−L(θold+d)≤2β1Ex∼D[aθold(x)(1−aθold(x))]
This bound is maximized when aθ(x)=0.5, indicating that both overly easy and overly difficult problems are suboptimal for learning. This result provides a principled target for difficulty adjustment during RLVR.
SEELE Framework: Multi-Round Adaptive Hinting
SEELE operationalizes this theory by augmenting each training sample with a hint whose length is adaptively determined to achieve the target rollout accuracy. The framework decomposes rollout generation into m rounds. In each round, SEELE fits a regression model to the accuracy-hint pairs collected so far, predicts the hinting rate required to reach the target accuracy, and generates rollouts accordingly.
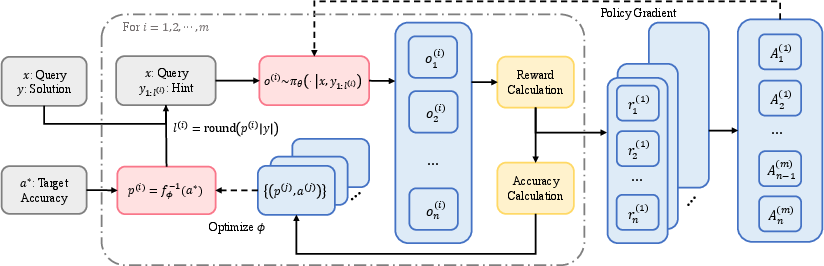
Figure 1: Overview of SEELE's multi-round adaptive hinting and rollout process, enabling instance-level difficulty control.
Hints are constructed as prefixes of annotated solutions, and the hinting rate (proportion of the full solution revealed) is dynamically adjusted per instance. The outputs from all rounds are used to update the policy model, with RLVR loss computed only on generated tokens and supervised loss imposed on hint tokens to encourage imitation.
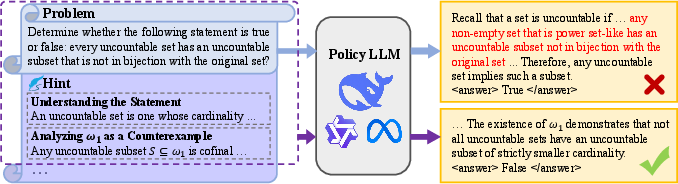
Figure 2: Direct rollout versus hinted rollout. Hints simplify the problem and guide the LLM toward correct solutions.
Rollout Accuracy Prediction via Item Response Theory
To accurately predict the required hint length for a given target accuracy, SEELE employs the three-parameter logistic (3PL) model from IRT:
fϕ(p)=b+1+e−k(p+μ)1−b
where p is the hinting rate, and ϕ={k,μ,b} are parameters fit via non-linear least squares. This model captures the S-shaped relationship between hinting rate and accuracy, with empirical validation across diverse problem instances.
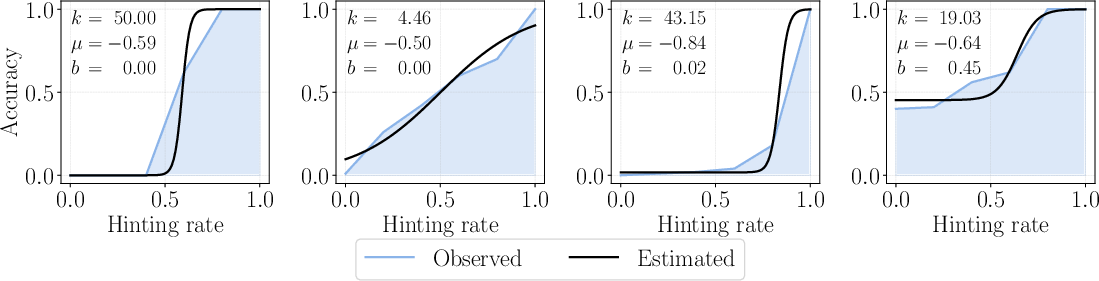
Figure 3: Representative accuracy-hint curves and 3PL fits, demonstrating the expressive power of the IRT model.
Experimental Results
SEELE is evaluated on six math reasoning and three general domain reasoning benchmarks using Qwen2.5-1.5B and Qwen2.5-3B models. Compared to GRPO, SFT, and recent supervision-aided RLVR baselines (LUFFY, UFT, Prefix-RFT), SEELE achieves substantial improvements:
- +11.8 points over GRPO and +10.5 points over SFT on math reasoning (Qwen2.5-3B)
- Consistent gains across all benchmarks and model sizes
- Superior generalization to out-of-domain tasks
The results demonstrate that dynamic, instance-level hinting yields higher learning efficiency and faster convergence than static or dataset-level hinting strategies.
Training Dynamics and Difficulty Control
SEELE maintains rollout accuracy near the target value throughout training, with rapid convergence and stable reward dynamics. Multi-round sampling enables precise difficulty control, with the 3PL model requiring only three to four samples for accurate fit.
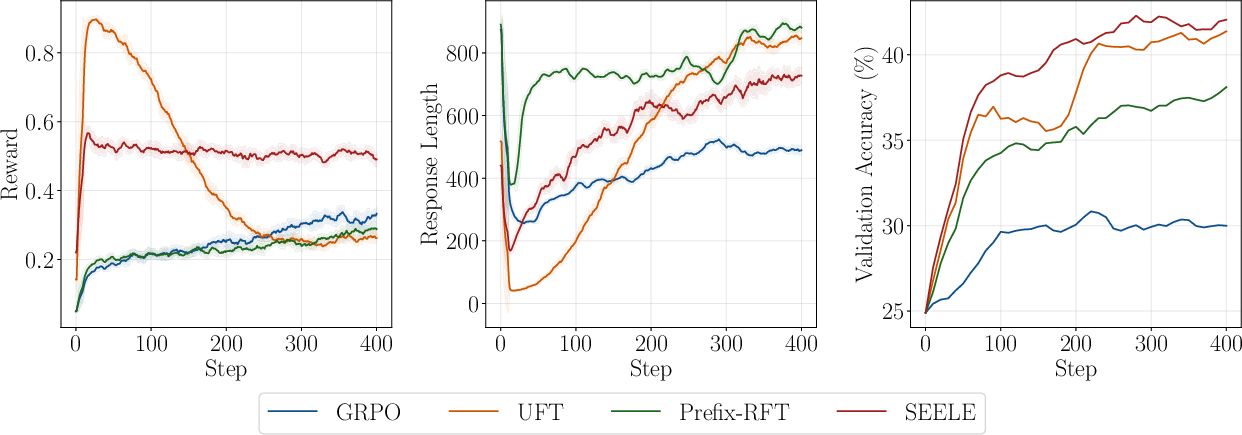
Figure 4: Training dynamics—reward, response length, and validation accuracy—comparing SEELE to baselines.
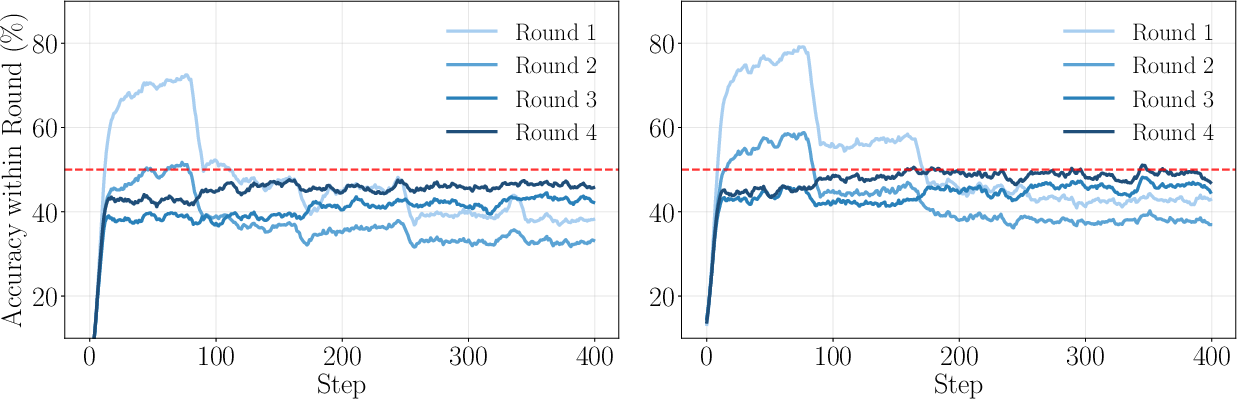
Figure 5: Rollout accuracy within each round during training, showing convergence to the targeted accuracy.
Ablation studies confirm that setting the target accuracy to 0.5 yields optimal performance, with symmetric degradation as the target deviates. The framework is robust to rollout configuration, with four rounds generally optimal for balancing regression accuracy and sample variance.
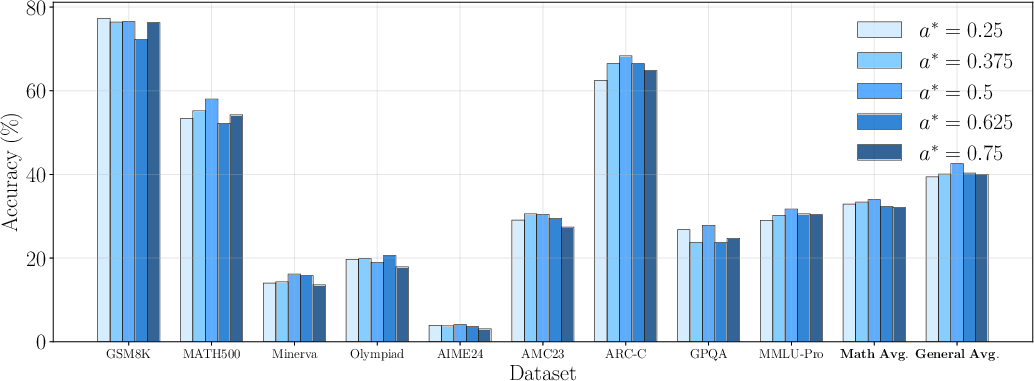
Figure 6: Performance for different target accuracy a∗, confirming the theoretical optimum at 0.5.
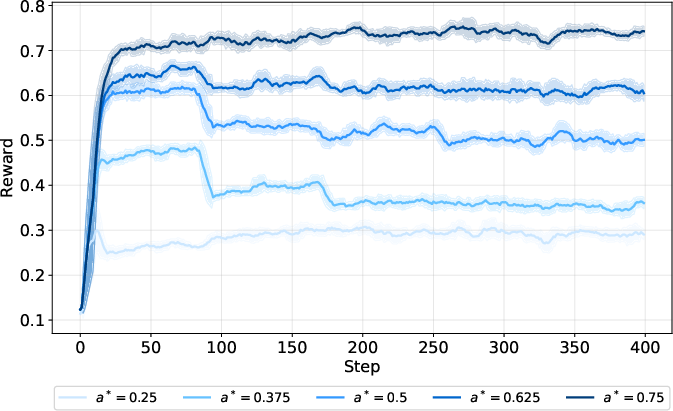
Figure 7: Reward across training steps for various target accuracy values, demonstrating precise control.
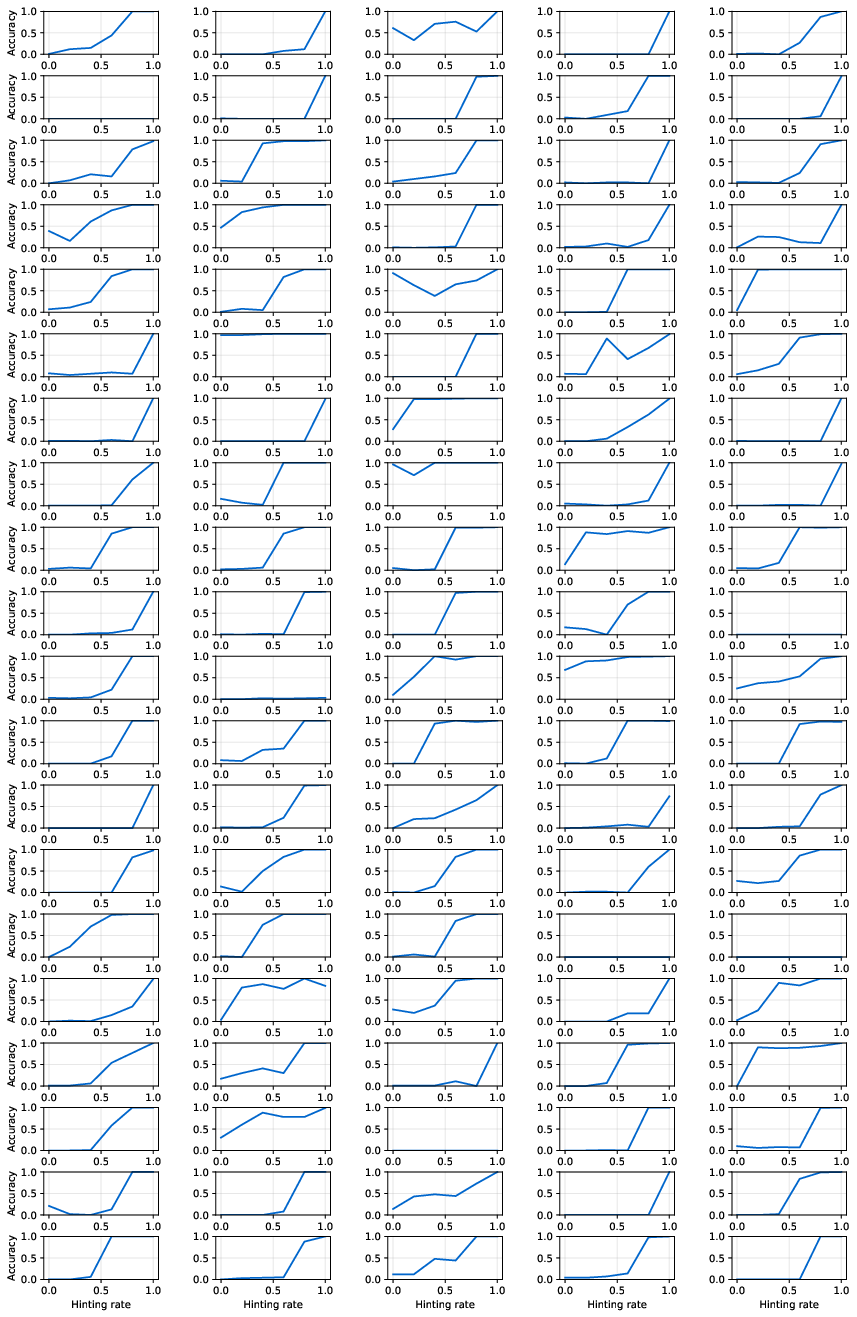
Figure 8: Accuracy versus hinting rate for 100 training examples, illustrating the S-shaped accuracy-hint relationship.
Implementation Considerations
SEELE is implemented atop GRPO with standard RLVR infrastructure, using veRL for distributed training. The multi-round hinting and IRT fitting introduce minimal computational overhead, as the 3PL model is efficiently fit via non-linear least squares (e.g., LMFIT). The framework is compatible with existing RLVR pipelines and can be integrated with other policy optimization algorithms.
Resource requirements scale with the number of rollout rounds and batch size, but the adaptive hinting mechanism ensures that each sample contributes maximally to learning, improving data efficiency. The approach is robust across model scales and domains, with particular benefits for smaller models that are more sensitive to difficulty mismatch.
Implications and Future Directions
SEELE provides a principled solution to the exploration inefficiency in RLVR for LLM reasoning, demonstrating that dynamic, instance-level difficulty adaptation is critical for efficient learning. The theoretical analysis and empirical results suggest that RLVR algorithms should target the 50% accuracy regime for maximal efficiency, and that static or dataset-level hinting is insufficient.
Practically, SEELE's framework can be extended to other domains (e.g., code generation, multimodal reasoning) and integrated with advanced RL algorithms (e.g., GSPO, VAPO). The use of IRT for difficulty modeling opens avenues for more sophisticated adaptive curricula and personalized training strategies. Future work may explore continual scaling, multi-turn agent-environment interaction, and integration with scalable oversight methods to further enhance reasoning capabilities beyond the base model.
Conclusion
SEELE advances RLVR for LLM reasoning by introducing capability-adaptive, instance-level hint scaffolding, grounded in a quantitative theory of learning efficiency. The framework achieves superior performance and data efficiency by maintaining rollout accuracy in the optimal regime, validated across diverse benchmarks and model sizes. This work establishes a foundation for principled difficulty adaptation in RL-based LLM training and highlights the importance of responsive supervision for complex reasoning tasks.

