MachineLearningLM: Continued Pretraining Language Models on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML
Abstract: LLMs possess broad world knowledge and strong general-purpose reasoning ability, yet they struggle to learn from many in-context examples on standard ML tasks, that is, to leverage many-shot demonstrations purely via in-context learning (ICL) without gradient descent. We introduce MachineLearningLM, a portable continued-pretraining framework that equips a general-purpose LLM with robust in-context ML capability while preserving its general knowledge and reasoning for broader chat workflows. Our pretraining procedure synthesizes ML tasks from millions of structural causal models (SCMs), spanning shot counts up to 1,024. We begin with a random-forest teacher, distilling tree-based decision strategies into the LLM to strengthen robustness in numerical modeling. All tasks are serialized with a token-efficient prompt, enabling 3x to 6x more examples per context window and delivering up to 50x amortized throughput via batch inference. Despite a modest setup (Qwen-2.5-7B-Instruct with LoRA rank 8), MachineLearningLM outperforms strong LLM baselines (e.g., GPT-5-mini) by an average of about 15% on out-of-distribution tabular classification across finance, physics, biology, and healthcare domains. It exhibits a striking many-shot scaling law: accuracy increases monotonically as in-context demonstrations grow from 8 to 1,024. Without any task-specific training, it attains random-forest-level accuracy across hundreds of shots. General chat capabilities, including knowledge and reasoning, are preserved: it achieves 75.4% on MMLU.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows how to teach a general-purpose LLM to “do machine learning” just by looking at examples inside its prompt—like a student learning from a worked example sheet—without changing the model’s weights. The authors call their method MachineLearningLM. It helps a model learn from many examples in a spreadsheet-like format and make accurate predictions on new rows, while still keeping its usual knowledge and reasoning skills for normal chat tasks.
What questions did the paper ask?
The paper focuses on three simple questions:
- Can we train a LLM to learn new tasks on the fly from lots of in-prompt examples (8 to 1,024), not just a few?
- Can it do this well on real-world “table” data (like spreadsheets with numbers and text) across different areas such as finance, physics, biology, and healthcare?
- Can it gain this new skill without forgetting how to be a general, helpful chatbot?
How did the researchers do it?
Think of their approach as building a better “study guide” and practice routine for the model.
1) Creating millions of practice problems
Instead of using real datasets (which could leak answers), they automatically generate millions of pretend tasks that look like real table problems. They use “structural causal models” (SCMs), which are like recipe cards that say how different columns in a table are related. This lets them safely create endless, varied practice tasks with different numbers of columns, classes, and difficulty levels.
Analogy: It’s like a video game level generator that makes countless training levels with real rules, so the player (the model) learns transferable skills.
2) Starting with a teacher (Random Forest)
At the beginning, the model imitates a traditional machine learning model called a Random Forest. Random Forests make decisions using many simple “if-then” rules from decision trees. Imitating this teacher stabilizes training so the model doesn’t get confused on hard tasks early on. After warming up, the model stops relying on the teacher and performs on its own.
Analogy: Training wheels on a bike—helpful at the start, then removed.
3) Packing more examples into the prompt
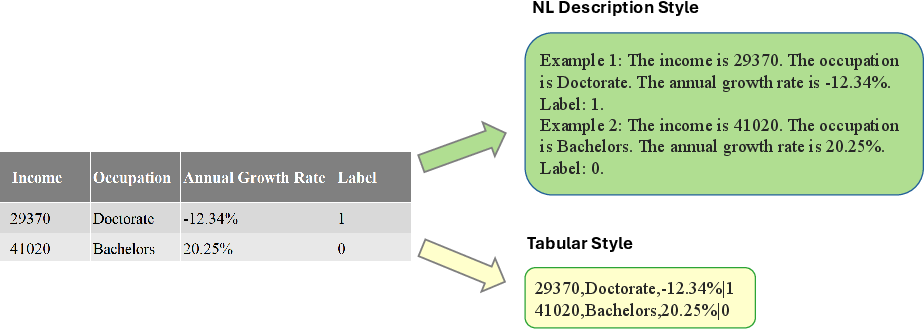
Long prompts are expensive, so they designed a compact way to show examples:
- They use table formatting (like a spreadsheet) instead of long sentences, so the same information uses fewer tokens.
- They convert numbers into neat integers from 0 to 999, which the model reads more efficiently and more accurately (no decimal-point drama).
- They predict many test rows in one go (batching), which speeds things up and makes training more stable.
Analogy: Formatting study notes so more examples fit on one page—and grading multiple questions at once.
4) Making answers stable with shuffling and voting
Models can be sensitive to the order of examples. So at test time, they shuffle the example order a few times, get predictions each time, and combine them with a confidence-weighted vote. This reduces randomness and boosts reliability.
Analogy: Asking multiple versions of yourself who studied the same material but read it in a different order, then taking the most confident, common answer.
5) Light-touch training on a small model
They start with a compact open-source model (Qwen-2.5-7B-Instruct) and add tiny “adapters” (LoRA) to continue pretraining on these synthetic tasks. This is a lightweight way to teach a new skill while preserving the model’s general knowledge.
What did they find, and why is it important?
Here are the key takeaways, explained plainly:
- More examples really help—consistently. Unlike many LLMs that stop improving after a few examples, MachineLearningLM keeps getting better as you give it more in-prompt examples (from 8 up to 1,024). This “many-shot scaling” is steady and strong.
- It performs like classic machine learning models when you give it lots of examples. With hundreds of examples in the prompt, it reaches Random-Forest-level accuracy on many tasks—without any task-specific training.
- It beats strong LLMs on table tasks. On average, it is about 15% more accurate than strong LLM baselines (including GPT-5-mini in the paper’s tests) on out-of-distribution tabular classification tasks across multiple domains.
- It understands mixed inputs. It can handle rows that include both numbers and text fields naturally, like a real spreadsheet.
- It keeps its general chat skills. Even after this extra training, it still scores well on general knowledge tests like MMLU (about 75% with 50 examples), so it’s still a good assistant.
- It’s efficient. Their prompt design fits 3–6 times more examples into the same context window and can speed up predictions by up to about 50× when batching.
Why it matters: This shows a practical way to turn a LLM into a flexible “in-prompt” data analyst that learns new tasks from examples you paste into a chat—without needing to retrain the model for each new dataset.
What could this change in the real world?
- Easier data analysis: You could paste a chunk of a spreadsheet with labeled examples and ask the model to label the rest—right in the prompt.
- Safer training: Because they use synthetic tasks for pretraining, it avoids issues like memorizing private datasets.
- Versatile assistants: The same model can chat, reason, and analyze numbers and text in tables—all in one place.
- Future directions: The same idea could extend beyond tables to other formats, like images embedded in tables or more complex multimodal inputs.
In short, MachineLearningLM is a recipe for teaching LLMs to act like practical, in-context machine learning solvers—using efficient prompts, smart warm-up with a teacher, and lots of synthetic practice—while still remaining helpful general AIs.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
This section provides a concise list of the knowledge gaps, limitations, and open questions identified in the research paper "MachineLearningLM: Continued Pretraining LLMs on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML."
Knowledge Gaps
- Pretraining Data Diversity: There is a limited discussion of how the synthetic tasks fully capture the diversity and complexity of real-world tabular datasets. An investigation into whether the synthetic tasks cover all relevant causal mechanisms and feature interactions found in real applications is missing.
- Generalization to Non-Tabular Contexts: The paper focuses on tabular data, leaving open questions about the model's adaptability and performance on non-tabular data or other data types often encountered in multimodal tasks.
Limitations
- Limited Context Length: The experiments are confined to a 131k-token context during inference, which raises questions about scalability to even longer contexts that might be required for more complex tasks or larger datasets.
- Model Size and Comparison: The use of Qwen-2.5-7B-Instruct as the baseline limits understanding of the approach's efficacy on much larger model architectures that might exhibit different scaling laws.
- Long-term Dependencies: There is insufficient exploration of the model's capacity to handle tasks with long-term dependencies due to restricted context windows in both pretraining and inference phases.
Open Questions
- Robustness Across Domains: While improvements are noted across various dataset domains, further exploration into domain-specific robustness and failure modes will help delineate the boundaries of model robustness.
- Transferability to Other Modalities: As the paper briefly mentions extending capabilities to multimodal inputs, there remains a need to test and document these extensions' viability and performance systematically.
- Impact of Correlations and Bias: It is unclear how correlations or biases in the synthetic pretraining data impact the model's ability to generalize to different real-world distributions.
Future Research Directions
- Synthetic Task Quality and Generation: Future work could focus on refining the task generation process to better mimic real-world complexities and ensure high-quality synthetic data.
- Scaling Behaviors of Larger Models: Investigating the applicability of these pretraining strategies to larger LLMs might uncover new scaling behaviors or unlock further performance gains.
- Balancing General and Task-Specific Skills: Research could explore how to better balance maintaining generalist LLM capabilities with task-specific learning, avoiding over-specialization based on pretraining data.
Practical Applications
Below are practical applications derived from the paper’s findings, methods, and innovations. They are grouped into immediate (deployable now) and longer-term (requiring further research, scaling, or engineering) opportunities.
Immediate Applications
These can be implemented today using the released model and methods (continued pretraining on synthetic SCM tasks, token‑efficient tabular encoding, integer number normalization to [0,999], sequence‑level batch predictions, and order‑robust confidence‑weighted voting).
Industry
- Spreadsheet/BI-assisted row classification without model training
- Sectors: software, analytics, SMBs, retail, finance
- Tools/workflows: an “In‑Context ClassifyRows()” function or add‑in for Excel/Google Sheets/BI tools that takes M labeled rows + N unlabeled rows and outputs labels in JSON; leverages tabular encoding and [0,999] integer normalization to fit hundreds of examples in-context; uses sequence‑level batch predictions for throughput
- Assumptions/dependencies: classification tasks (2–10 classes), context length budget (up to ~131k tokens during inference), access to model logprobs or multiple prompt permutations for confidence‑aware voting, data can be serialized into compact tabular format
- Customer support ticket routing and prioritization from mixed text + numeric metadata
- Sectors: software, customer support, IT service management
- Tools/workflows: helpdesk integration that classifies tickets into routing queues using subject/short description plus structured fields; no training cycle required—operators can add more in‑prompt examples to improve accuracy
- Assumptions/dependencies: short textual fields rather than long documents; adherence to compact tabular prompt schema; consistent label taxonomy
- Marketing churn/propensity and lead-qualification triage (prototype and light‑production)
- Sectors: marketing, CRM, sales ops
- Tools/workflows: CRM plugin that classifies leads or customers into risk/propensity buckets given tabular histories and a handful of labeled exemplars; many‑shot scaling enables quick boosts by pasting more examples
- Assumptions/dependencies: classification (not regression), moderate class counts, internal validation before customer‑impacting decisions
- Fraud/risk alert triage and case bucketing
- Sectors: finance, fintech, insurance, cybersecurity
- Tools/workflows: microservice that labels events/transactions/logs as risk buckets using M labeled alerts as in‑prompt demonstrations; confidence‑weighted voting across permutation variants to reduce order bias
- Assumptions/dependencies: on‑prem deployment preferred for sensitive data; governance approvals; tasks remain within tabular classification scope
- ETL/ELT and data engineering classification transforms
- Sectors: data platforms, data engineering
- Tools/workflows: SQL/Spark UDF that consumes chunks of rows and outputs class labels; sequence‑level batch prediction amortizes instruction overhead for cost efficiency; integrates into Airflow/DBT pipelines
- Assumptions/dependencies: stable schema; operations team accepts LLM dependency and has GPU/accelerator capacity or a managed inference service
- Manufacturing/IoT anomaly and event code triage
- Sectors: manufacturing, energy, industrial IoT
- Tools/workflows: row‑wise classification service to bucket machine events, statuses, or alarms based on sensor aggregates and categorical flags; improves as more labeled shots are supplied
- Assumptions/dependencies: primarily discrete categorization; time‑series forecasting is out of scope; on‑prem/edge inference may need model distillation or memory‑efficient serving
- Healthcare back‑office classification (non-diagnostic)
- Sectors: healthcare operations
- Tools/workflows: classify claims queues, appointment no‑show risk groups, lab flag categories (with appropriate oversight); native handling of mixed numeric and short text fields
- Assumptions/dependencies: not for clinical diagnosis; HIPAA and internal validation; on‑prem inference or private cloud; limited to tabular classification
- Security alert and log event labeling for faster SOC triage
- Sectors: cybersecurity
- Tools/workflows: SOC tool plugin that categorizes alerts using many‑shot exemplars; uses confidence‑aware self‑consistency to stabilize predictions across permutations
- Assumptions/dependencies: structured logs/features available; internal evaluation and thresholds for handoff to analysts
- Domain adaptation via continued pretraining on synthetic tasks
- Sectors: any domain with tabular classification
- Tools/workflows: generate SCM‑style synthetic tasks that mimic domain priors (e.g., healthcare codes, financial features) and perform brief LoRA‑based continued pretraining to bias the model; preserves general chat ability while improving domain fit
- Assumptions/dependencies: compute budget for continued pretraining; careful synthetic prior design; model license compatibility (Qwen‑2.5‑7B‑Instruct base)
Academia
- Label‑efficient prelabeling to bootstrap datasets
- Tools/workflows: use the model as a many‑shot in‑context labeler to pre‑annotate datasets prior to expert adjudication; straightforward integration in Jupyter/Colab with the provided prompts
- Assumptions/dependencies: classification tasks only; calibration/QA needed; balanced sampling of in‑prompt examples to avoid bias
- Benchmarking and stress testing for tabular ICL
- Tools/workflows: adopt the paper’s SCM task generator to probe model robustness to class imbalance, feature permutations, and order sensitivity; evaluate many‑shot scaling laws
- Assumptions/dependencies: access to logprobs (or at least deterministic decoding) to implement confidence‑aware voting; reproducible prompt serialization
- Teaching/education: hands‑on labs in “ML without training”
- Tools/workflows: course modules demonstrating in‑context ML on tabular data, showing effects of tokenization for numeracy, context budgeting, and self‑consistency
- Assumptions/dependencies: GPU access optional (7B can be CPU‑served slowly or quantized); datasets curated to fit context windows
Policy and Public Sector
- Rapid triage of public complaints, inspections, and permit requests
- Sectors: public administration, regulatory agencies
- Tools/workflows: internal tool that classifies cases into triage queues with in‑prompt examples curated by analysts; no model training loop or data export needed
- Assumptions/dependencies: on‑prem/private inference to protect PII; human‑in‑the‑loop oversight and auditing; local policy compliance
- Crisis dashboards that categorize field reports combining short text + structured fields
- Sectors: emergency management, humanitarian response
- Tools/workflows: ad‑hoc classifier to bucket reports or requests for resources; operators append more labeled shots as conditions evolve
- Assumptions/dependencies: reliable connectivity and compute; classification taxonomies defined; validation on representative samples
Daily Life
- Personal finance transaction categorization and budget tagging
- Tools/workflows: spreadsheet template where the user pastes a handful of labeled transactions and gets categories for the rest; improves with more shots
- Assumptions/dependencies: local or private inference recommended for financial data; category lists kept small/moderate
- Personal inbox/task labeling using metadata and short snippets
- Tools/workflows: local assistant that classifies messages/tasks into folders or priorities using a few labeled examples
- Assumptions/dependencies: short text fields; user‑maintained examples; offline/on‑device inference may require quantized models
Long‑Term Applications
These require additional research, scaling, engineering, or validation beyond the current paper (e.g., broader modalities, new objectives, regulatory-grade reliability).
Industry
- Multimodal in‑context tabular ML (images, links, embedded content in tables)
- Sectors: healthcare (imaging metadata + labs), manufacturing (images + sensor summaries), e‑commerce (product images + attributes)
- Tools/workflows: HTML‑table‑based prompts that mix image thumbnails with text/numbers; “Spreadsheet with images” classification assistants
- Assumptions/dependencies: multimodal LLM backbone; robust serialization and rendering inside long contexts; careful latency control
- In‑context regression, ranking, and time‑series extensions
- Sectors: finance, energy, supply chain, operations
- Tools/workflows: extend objectives beyond classification to regression/forecasting in context; token‑efficient encodings for sequences
- Assumptions/dependencies: new training corpora/objectives; numeracy‑first tokenization; evaluation on real‑world continuous targets
- Agentic “memory‑rich” data scientist assistants
- Sectors: analytics, enterprise software
- Tools/workflows: agents that accumulate many‑shot exemplars across sessions, manage retrieval/memory, and adapt prompts dynamically to evolving tasks
- Assumptions/dependencies: persistent memory stores; retrieval‑augmented prompting; governance for data retention
- In‑database LLM co‑processor for tabular ICL
- Sectors: data platforms, cloud warehouses
- Tools/workflows: SQL UDFs that push down in‑context ML into the database, batch predictions over partitions, and expose calibrated confidence
- Assumptions/dependencies: GPU acceleration near data; streaming long‑context support; transactionally safe retries and JSON schema guarantees
- Auditable rule‑augmented ICL via tree‑rationale distillation
- Sectors: finance, healthcare, insurance, public sector
- Tools/workflows: incorporate teacher’s rule paths/feature attributions as chain‑of‑thought rationales to improve interpretability and auditing
- Assumptions/dependencies: rationale‑augmented training (not in current paper); fidelity checks between rationales and predictions; human factors validation
- Cost‑optimized edge and on‑prem deployments
- Sectors: industrial IoT, sensitive enterprise data
- Tools/workflows: distill or quantize ICL capabilities into smaller backbones; long‑context extrapolation compatible with memory‑constrained devices
- Assumptions/dependencies: research on ICL distillation; hardware‑aware serving; stability under extended context windows
Academia
- Causal‑aware ICL and discovery
- Tools/workflows: leverage SCM‑based pretraining to induce stronger causal sensitivities; evaluate on interventions and counterfactual prompts
- Assumptions/dependencies: new benchmarks with interventional queries; objectives that penalize shortcut heuristics
- Systematic study of numeracy, tokenization, and normalization
- Tools/workflows: quantify how integer normalization vs decimal tokenization affects learning/robustness; cross‑tokenizer reproducibility studies
- Assumptions/dependencies: consistent tokenizer comparisons; standardized datasets; open evaluation harnesses
- Long‑context generalization and invariances
- Tools/workflows: measure robustness to feature and example permutations, missingness, and extremely long prompts; architectural or training fixes for order‑invariance
- Assumptions/dependencies: models with reliable >100k context; efficient self‑consistency variants not reliant on many permutations
Policy and Public Sector
- Regulatory‑grade, interpretable in‑context ML
- Tools/workflows: combine rule/rationale distillation with calibrated confidence and monitoring; standardized documentation for procurement and audits
- Assumptions/dependencies: validated calibration, fairness, stability under distribution shift; role‑based access and logging
- Privacy‑preserving, on‑device ICL for sensitive programs
- Tools/workflows: offline inference for PII‑heavy tasks (benefits adjudication triage, health operations), with ephemeral prompts and local storage
- Assumptions/dependencies: efficient local serving; stringent data governance; repeatable evaluations for policy sign‑off
Daily Life
- On‑device personal data classifiers that learn preferences in context
- Tools/workflows: local assistants that adapt to a user’s examples for budgeting, task sorting, or small home inventories—no cloud needed
- Assumptions/dependencies: compact models with long‑context support; simple UIs for adding examples and reviewing confidence
- No‑code “teach by example” apps
- Tools/workflows: consumer apps where users drag‑and‑drop a CSV, label a handful of rows, and get many‑shot classifications with instant feedback
- Assumptions/dependencies: careful UX around error handling and ambiguity; transparent confidence and easy correction loops
Notes on feasibility across applications
- Scope: The method is demonstrated for tabular binary/multiclass classification (2–10 classes). Claims beyond classification (regression, long text, time series) are prospective.
- Context length and cost: Many‑shot gains depend on fitting large M within context; integer normalization and tabular encoding help, but serving infrastructure must support long contexts and batch predictions.
- Reliability: Order‑robust, confidence‑aware voting needs either logprobs or multiple permutations; closed APIs without logprobs may limit confidence‑weighted aggregation.
- Governance: For regulated uses, prospective interpretability via rule‑rationale distillation and calibration will be important; human‑in‑the‑loop recommended.
- Data handling: While “no training” reduces data retention risks, prompts still carry sensitive data; on‑prem/private inference is advised for PII.
Collections
Sign up for free to add this paper to one or more collections.

