More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
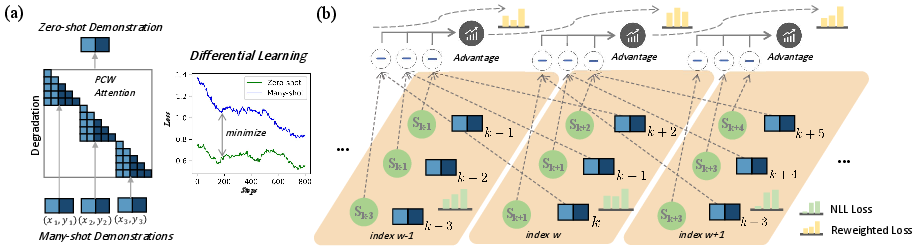
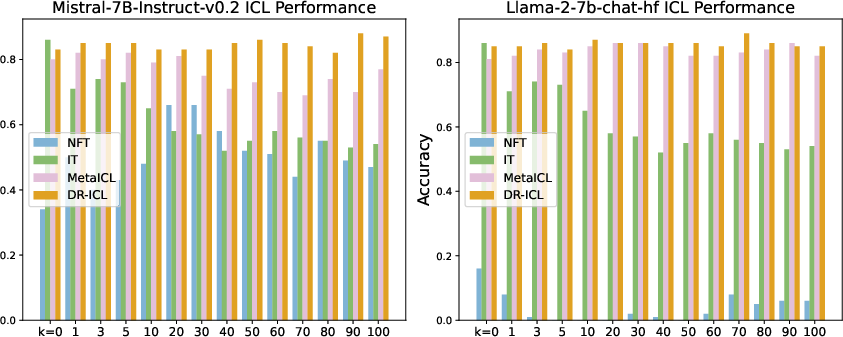
Abstract: LLMs excel at few-shot in-context learning (ICL) without requiring parameter updates. However, as ICL demonstrations increase from a few to many, performance tends to plateau and eventually decline. We identify two primary causes for this trend: the suboptimal negative log-likelihood (NLL) optimization objective and the incremental data noise. To address these issues, we introduce \textit{DrICL}, a novel optimization method that enhances model performance through \textit{Differentiated} and \textit{Reweighting} objectives. Globally, DrICL utilizes differentiated learning to optimize the NLL objective, ensuring that many-shot performance surpasses zero-shot levels. Locally, it dynamically adjusts the weighting of many-shot demonstrations by leveraging cumulative advantages inspired by reinforcement learning, thereby mitigating the impact of noisy data. Recognizing the lack of multi-task datasets with diverse many-shot distributions, we develop the \textit{Many-Shot ICL Benchmark} (ICL-50)-a large-scale benchmark of 50 tasks that cover shot numbers from 1 to 350 within sequences of up to 8,000 tokens-for both fine-tuning and evaluation purposes. Experimental results demonstrate that LLMs enhanced with DrICL achieve significant improvements in many-shot setups across various tasks, including both in-domain and out-of-domain scenarios. We release the code and dataset hoping to facilitate further research in many-shot ICL\footnote{https://github.com/xiaoqzhwhu/DrICL}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage DR-ICL (Differentiated Learning + advantage-based Reweighting) and/or the MICLB benchmark today, together with likely tools/workflows and key feasibility considerations.
- Customer support assistants that remain stable with many prior examples
- Sectors: software, telecom, retail
- What to do: Fine-tune an existing LLM (e.g., Llama-2-7b, Mistral-7B) with DR-ICL on resolved tickets and their solutions to keep accuracy from degrading as more in-context examples are added.
- Tools/workflows: DR-ICL LoRA adapters, nightly/weekly fine-tunes; integrate with retrieval so prompts include hundreds of similar past cases; monitor k-shot performance drift in CI.
- Assumptions/dependencies: Access to model weights and fine-tuning infra; token limits (often 8k–32k); data privacy controls; demonstration quality varies and must be curated.
- E-commerce search, retrieval, and ranking improvements
- Sectors: e-commerce, media platforms
- What to do: Use DR-ICL-fine-tuned models to improve retrieval and reranking on click/purchase logs (paper reports gains on EcomRetrieval, VideoRetrieval, and cMedQA ranking).
- Tools/workflows: Advantage-weighted reranking module on top of vector search; batch training with window size W≈10 and sampling size S≈1; evaluation using P@k/R@k/NDCG.
- Assumptions/dependencies: Offline compute for training; bias/noise in behavioral logs; careful hyperparameter tuning (e.g., α≈0.2–0.4, γ≈11) to avoid zero-shot regressions.
- Long-document and multi-example summarization that does not degrade with more demonstrations
- Sectors: media, legal ops, market research
- What to do: Fine-tune summarizers with DR-ICL to keep performance stable or improve as prompt contains many exemplars (paper shows improvements on XSUM/CNN).
- Tools/workflows: Summarization microservice that samples windows of exemplars; D3/ROUGE/BLEU dashboards; reweighting to suppress noisy summaries as demonstrations scale.
- Assumptions/dependencies: Sufficient context length; summarization style consistency; content licensing.
- Many-shot QA/classification/clustering robustness for internal knowledge bases
- Sectors: enterprise IT, consulting, internal legal/ops
- What to do: Apply DR-ICL to enterprise QA on wikis, FAQs, and policy documents; keep classification and clustering consistent as hundreds of exemplars are used.
- Tools/workflows: RAG pipeline with advantage-based demonstration weighting; k-by-k evaluation harness to ensure no plateau or decline; MICLB-inspired tests.
- Assumptions/dependencies: Controlled vocabulary/domain shift; guardrails for sensitive content; prompt budgeting.
- Coding assistants trained to perform well with large exemplar pools
- Sectors: software engineering, DevOps
- What to do: Fine-tune on many repository-specific examples so code suggestions stay accurate as the prompt includes many code snippets/tests.
- Tools/workflows: IDE plugin backed by DR-ICL LoRA; reweighting windows over exemplars from recent commits; evaluation by test pass rate and review acceptance.
- Assumptions/dependencies: Repository access and IP constraints; secure training environments; context length vs latency trade-offs.
- Education: stable tutoring with many worked examples
- Sectors: EdTech
- What to do: Fine-tune tutoring models with DR-ICL on problem-solution pairs so performance does not degrade as more examples are shown in context.
- Tools/workflows: Curriculum builder that adaptively picks past solutions; monitor accuracy across k-shots (e.g., 1–100); students’ learning analytics.
- Assumptions/dependencies: Age-appropriate content; alignment for pedagogy and safety; device constraints in classrooms.
- Healthcare literature triage and retrieval (non-diagnostic)
- Sectors: healthcare, pharma R&D
- What to do: Apply DR-ICL to literature retrieval/reranking and non-clinical summarization where many examples are beneficial but often noisy.
- Tools/workflows: Advantage-weighted reranking of abstracts; long-context summarization of systematic reviews with many exemplars; audit trails.
- Assumptions/dependencies: Strict non-diagnostic use; HIPAA/GDPR compliance; domain-specific evaluation; careful prompt safety.
- MLOps: swap plain NLL with DR-ICL in fine-tuning pipelines
- Sectors: AI platform teams
- What to do: Incorporate the differentiated objective and advantage-based reweighting into existing instruction-tuning jobs to improve many-shot stability.
- Tools/workflows: Training hooks for computing many-shot vs zero-shot losses; windowed sampling and cumulative advantage; k-shot dashboards and alarms.
- Assumptions/dependencies: Training code access; compute budget; regression testing for zero-shot tasks (α controls trade-off).
- Benchmarking and procurement readiness using MICLB
- Sectors: industry, academia, public sector
- What to do: Use the MICLB benchmark (7 task families, 50 datasets, up to ~8k tokens) to certify “many-shot robustness” across QA, reasoning, retrieval, clustering, classification, summarization, reranking.
- Tools/workflows: Evaluation harnesses; “many-shot stress tests” at k∈[1,350]; reports for model selection and vendor comparisons.
- Assumptions/dependencies: Compute to run long-context tests; task distribution fit vs your domain; potential need to extend to multilingual or domain-specific variants.
- Inference-time demonstration selection inspired by advantage reweighting
- Sectors: any LLM deployment using ICL
- What to do: Even without retraining, implement a heuristic that scores candidate demonstrations using a small validation window and upweights exemplars with larger incremental gains.
- Tools/workflows: “Advantage-weighted sampler” that measures loss deltas over a small dev set; integrates with RAG to pick exemplars per query.
- Assumptions/dependencies: Additional inference compute for scoring; surrogate metrics if ground truth isn’t available; less effective than full DR-ICL training but low-friction.
- Personal knowledge management and email drafting at scale
- Sectors: daily life, productivity
- What to do: Use DR-ICL-tuned models (or advantage-weighted selection) to write emails or notes using many prior personal examples without quality loss.
- Tools/workflows: Desktop/mobile assistant that samples similar drafts, applies windowing to avoid noisy exemplars, and maintains style consistency.
- Assumptions/dependencies: Privacy and local/secure fine-tunes; small-device constraints; personal data consent.
Long-Term Applications
Below are high-impact prospects that likely require additional research, scaling, or safeguards (e.g., longer contexts, safety validation, regulation).
- High-stakes decision support with many-shot evidence
- Sectors: healthcare (clinical support), legal, finance
- What it enables: Use many past patient cases or legal precedents/filings as demonstrations without the usual performance collapse seen at high k.
- Potential tools/workflows: Clinician-in-the-loop assistants; legal research copilots that keep performance stable across hundreds of citations; finance copilots analyzing years of filings/transcripts.
- Assumptions/dependencies: Rigorous validation and monitoring; explainability; regulatory approvals; stronger safety/alignment; protected data handling.
- Ultra-long-context applications (100k to 1M tokens) with stable many-shot scaling
- Sectors: enterprise content management, government archives, scientific discovery
- What it enables: Processing books/corpora/repositories where hundreds or thousands of exemplars are useful for few-shot adaptation.
- Potential tools/workflows: Streaming context managers that window and reweight exemplars; “many-shot aware” memory systems; hybrid fine-tune + inference-time weighting.
- Assumptions/dependencies: Availability of ultra-long-context models; memory/latency optimizations; new evaluation protocols beyond 8k tokens.
- Continual and online learning via windowed advantage feedback
- Sectors: SaaS platforms, recommendation systems, customer success, cybersecurity
- What it enables: Systems that adapt to new demonstrations over time, using DR-ICL windows to mitigate drift and noise in evolving data.
- Potential tools/workflows: Online fine-tuning with rolling windows; concept-drift detectors; advantage-based data schedulers.
- Assumptions/dependencies: Stability-plasticity trade-offs; preventing catastrophic forgetting; robust guardrails for live updates.
- Pretraining/foundation-model regimes that bake in many-shot robustness
- Sectors: AI labs, model vendors
- What it enables: Integrate differentiated objectives and reweighting during continued pretraining/instruction-tuning so many-shot ICL becomes a first-class capability.
- Potential tools/workflows: Bilevel optimization pipelines combining DR-ICL with RLHF/DPO; curriculum design for k-shot scaling; massive-scale MICLB-style corpora.
- Assumptions/dependencies: Large-scale compute; careful interplay with alignment methods; new scaling laws and theory for many-shot behavior.
- Automated demonstration curation platforms
- Sectors: data tooling, MLOps vendors
- What it enables: Services that automatically score, select, and reweight demonstrations using advantage signals, reducing human curation costs for many-shot ICL.
- Potential tools/workflows: “DemoScore” services; exemplar banks with quality/novelty/noise tags; policy-based selection for domains and tasks.
- Assumptions/dependencies: Access to representative validation tasks; governance for IP and privacy; robust measures when ground truth is sparse.
- Cross-lingual, domain-specific, and multimodal many-shot ICL
- Sectors: global enterprises, media, robotics
- What it enables: Extend DR-ICL to multilingual datasets, domain-specific corpora (e.g., engineering logs), and multimodal demonstrations (text+code+images+trajectories).
- Potential tools/workflows: Multimodal many-shot tutors; robotics skill libraries with advantage-weighted trajectory selection; multilingual MICLB variants.
- Assumptions/dependencies: Suitable multimodal backbones; task- and modality-specific losses; new benchmarks for cross-lingual/multimodal many-shot.
- Policy, standards, and certification for “many-shot robustness”
- Sectors: public sector, regulators, enterprise procurement
- What it enables: Procurement/evaluation standards that stress-test LLMs at high k and long contexts to prevent silent performance regressions.
- Potential tools/workflows: MICLB-derived government/industry benchmark suites; certification programs; reporting templates for k-shot variance and noise sensitivity.
- Assumptions/dependencies: Community and vendor buy-in; extensions to safety/fairness testing at long context; continuous updates as models evolve.
- Energy, manufacturing, and IoT fault analysis with long sequences
- Sectors: energy, industrial automation
- What it enables: Robust analysis over many prior incidents/logs where adding more exemplars historically adds noise; DR-ICL keeps performance stable.
- Potential tools/workflows: Many-shot diagnostic copilots; maintenance playbooks built from long histories; windowed advantage weighting for event sequences.
- Assumptions/dependencies: Domain-accurate annotations; integration with time-series and multimodal data; operational safety constraints.
- Large-scale educational content generation and auto-curricula
- Sectors: education, corporate training
- What it enables: Generate and adapt courses using thousands of exemplar problems/solutions while preserving quality.
- Potential tools/workflows: Curriculum designers with demonstrated stability across k; personalized learning paths leveraging advantage-weighted examples.
- Assumptions/dependencies: Pedagogical oversight; bias and fairness audits; student privacy and consent.
Notes on Feasibility and Deployment
- Model access: DR-ICL requires fine-tuning; you need weights (open-source or enterprise-licensed) and training code integration.
- Context limits: MICLB experiments use sequences up to ~8k tokens; benefits likely extend to longer contexts but depend on the base model’s window and memory efficiency.
- Hyperparameters: α controls many-shot vs zero-shot trade-off (e.g., 0.2–0.4 in paper); γ≈11 stabilizes advantage scaling; window size W≈10 and sampling size S≈1 worked well in tests.
- Compute and latency: Training costs increase; inference costs rise with larger contexts. Use reweighting to constrain effective demonstration sets without quality loss.
- Data quality and domain shift: DR-ICL mitigates noise via advantage-based reweighting but still benefits from curated demonstrations; monitor k-shot variance as a health signal.
- Safety, privacy, and compliance: High-stakes sectors require alignment, audits, and possibly human-in-the-loop review; ensure HIPAA/GDPR and IP compliance where applicable.
- Interplay with RLHF/DPO: When stacking DR-ICL with alignment methods, validate that zero-shot/few-shot capabilities remain acceptable; adjust α and training schedule accordingly.
Collections
Sign up for free to add this paper to one or more collections.

