TreeGPT: Pure TreeFFN Encoder-Decoder Architecture for Structured Reasoning Without Attention Mechanisms
Abstract: We present TreeGPT, an attention-free neural architecture that explores the potential of pure TreeFFN encoder-decoder design for structured reasoning tasks. Unlike traditional transformer approaches that rely on attention mechanisms, TreeGPT employs bidirectional TreeFFN components that process sequences through adjacent connections in parallel, aiming to achieve computational efficiency while maintaining reasoning capabilities. Our approach centers on a TreeFFN Encoder-Decoder mechanism: $$\text{Encoder TreeFFN (L} \rightarrow \text{R)} + \text{Decoder TreeFFN (R} \leftarrow \text{L)} \rightarrow \text{Parallel Processing}$$ where the encoder processes left-to-right dependencies while the decoder handles right-to-left patterns, both using simple neighbor-to-neighbor connections. This design eliminates attention computation while maintaining sequence modeling capabilities. We evaluate our approach on the ARC Prize 2025 dataset, where TreeGPT achieves 99\% validation accuracy using 3.16M parameters. The model converges within 1500 training steps and demonstrates 100\% token-level accuracy on selected evaluation samples. Our preliminary results suggest that for certain structured reasoning tasks, specialized TreeFFN architectures may offer advantages over attention-based approaches. While these findings are encouraging, we acknowledge that further investigation across diverse tasks and datasets would be valuable to establish the broader applicability of attention-free designs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TreeGPT, a new kind of AI model designed to solve structured reasoning puzzles (like the ARC-AGI grid puzzles) without using the usual “attention” tricks found in Transformers. Instead, it uses a simpler, faster way of passing information along a sequence in both directions, a method the authors call a Tree Feed-Forward Network (TreeFFN). The big idea: for some kinds of logic and pattern tasks, you might not need heavy attention at all.
What questions did the researchers ask?
They mainly wanted to know:
- Can a model that completely avoids attention still reason well on tricky, structured problems?
- If we pass information only between neighbors (left-to-right and right-to-left), can we match or beat more complicated models?
- Which small design choices inside this simpler model matter most for good performance?
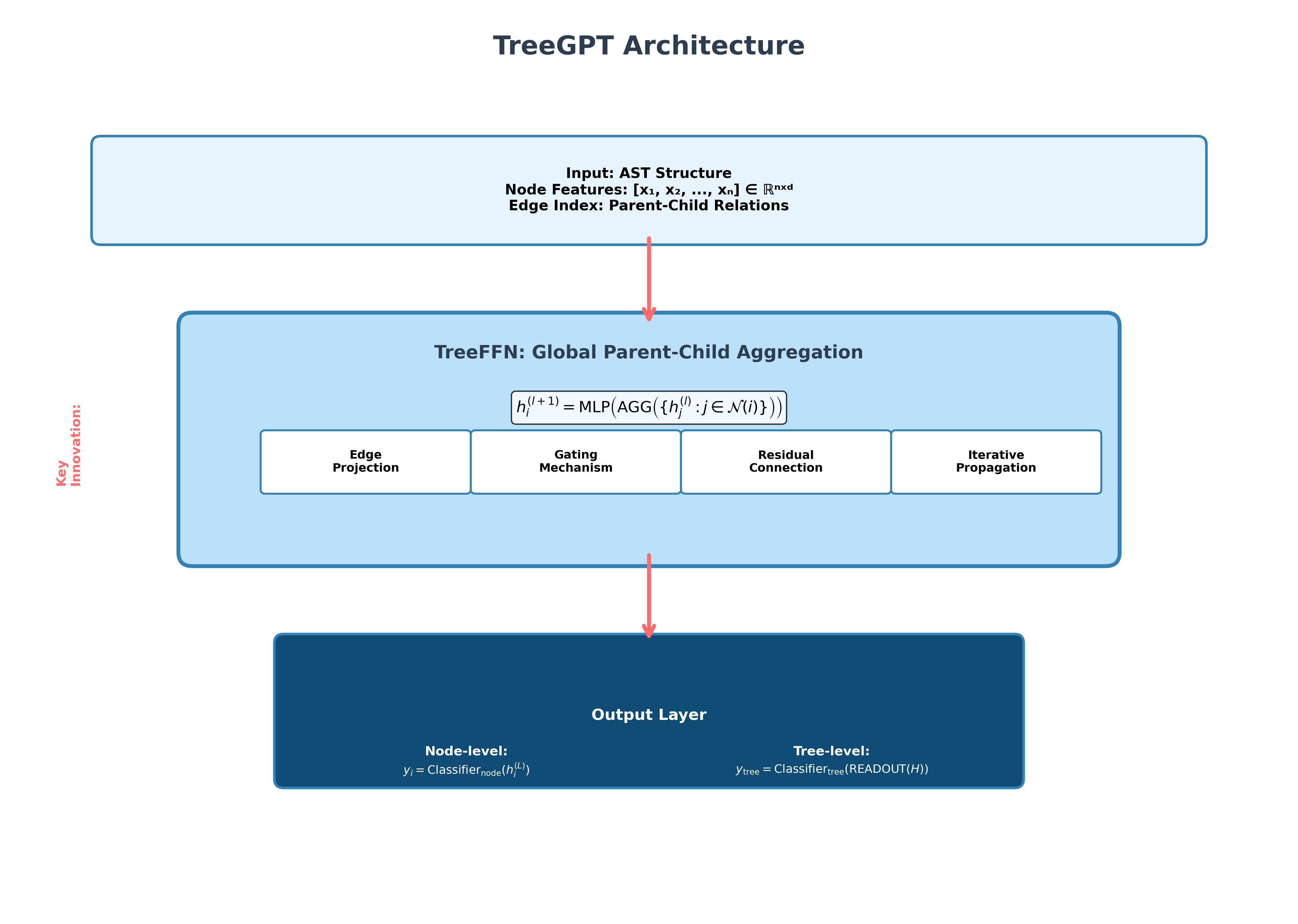
How does TreeGPT work? (Simple explanation)
Think of a line of students passing notes in class:
- In a Transformer with attention, every student tries to look at and “pay attention to” everyone else at once. This is powerful, but slow and expensive when the class is big.
- In TreeGPT’s TreeFFN, each student only passes notes to their neighbor. But they do this quickly in both directions—left-to-right and right-to-left—and in parallel. After a few rounds, information from one end will have spread across the whole line, without everyone looking at everyone else.
Here are the key parts in everyday terms:
- Encoder and Decoder:
- Encoder = read from left-to-right (like reading a sentence forward).
- Decoder = read from right-to-left (like reading it backward).
- They both work at the same time, so information spreads fast from both ends.
- TreeFFN (Tree Feed-Forward Network):
- Despite the name “Tree,” in this paper it mainly uses simple neighbor links, like a chain. The “tree” idea is about handling structured information well, similar to family trees or folders-within-folders.
- Each step mixes what a position knows with what its neighbor knows, then repeats.
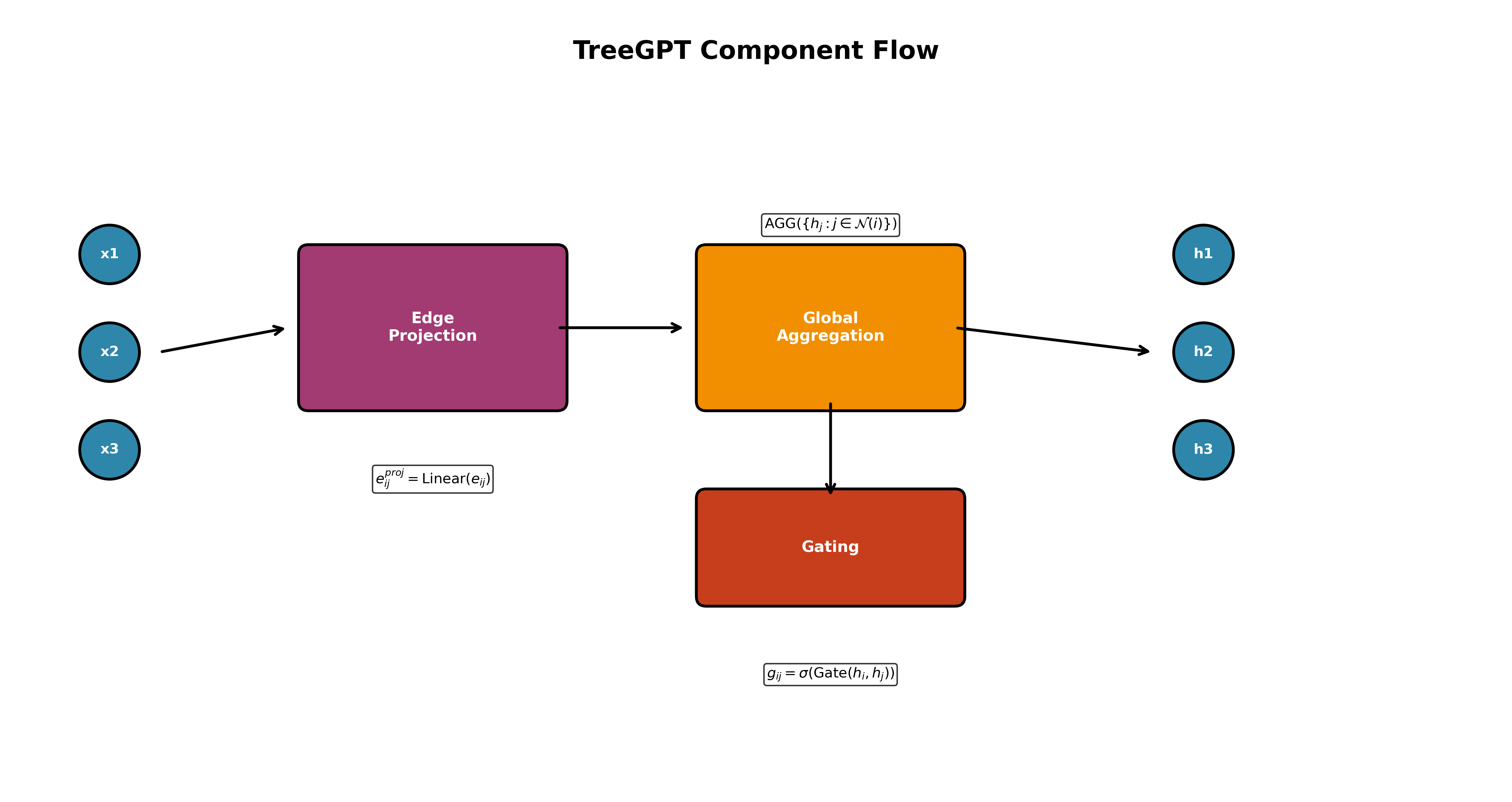
- Edge Projection (adding labels to the links):
- Imagine each “note-passing link” has a small tag that says how to pass the note. This “projection” helps the model send the right kind of information.
- Gating (smart doors):
- Gates act like little doors that decide how much information should pass through at each link. This helps avoid noise.
- Residual connections (shortcuts):
- Shortcuts let the model keep a copy of the original information while adding new updates, which can help training—but sometimes can cause overfitting if used too much.
What’s special here:
- No attention: The model never does the “everyone looks at everyone” step, which usually costs a lot of compute.
- Parallel processing: Left-to-right and right-to-left happen at the same time, speeding up learning and inference.
What did they test and how?
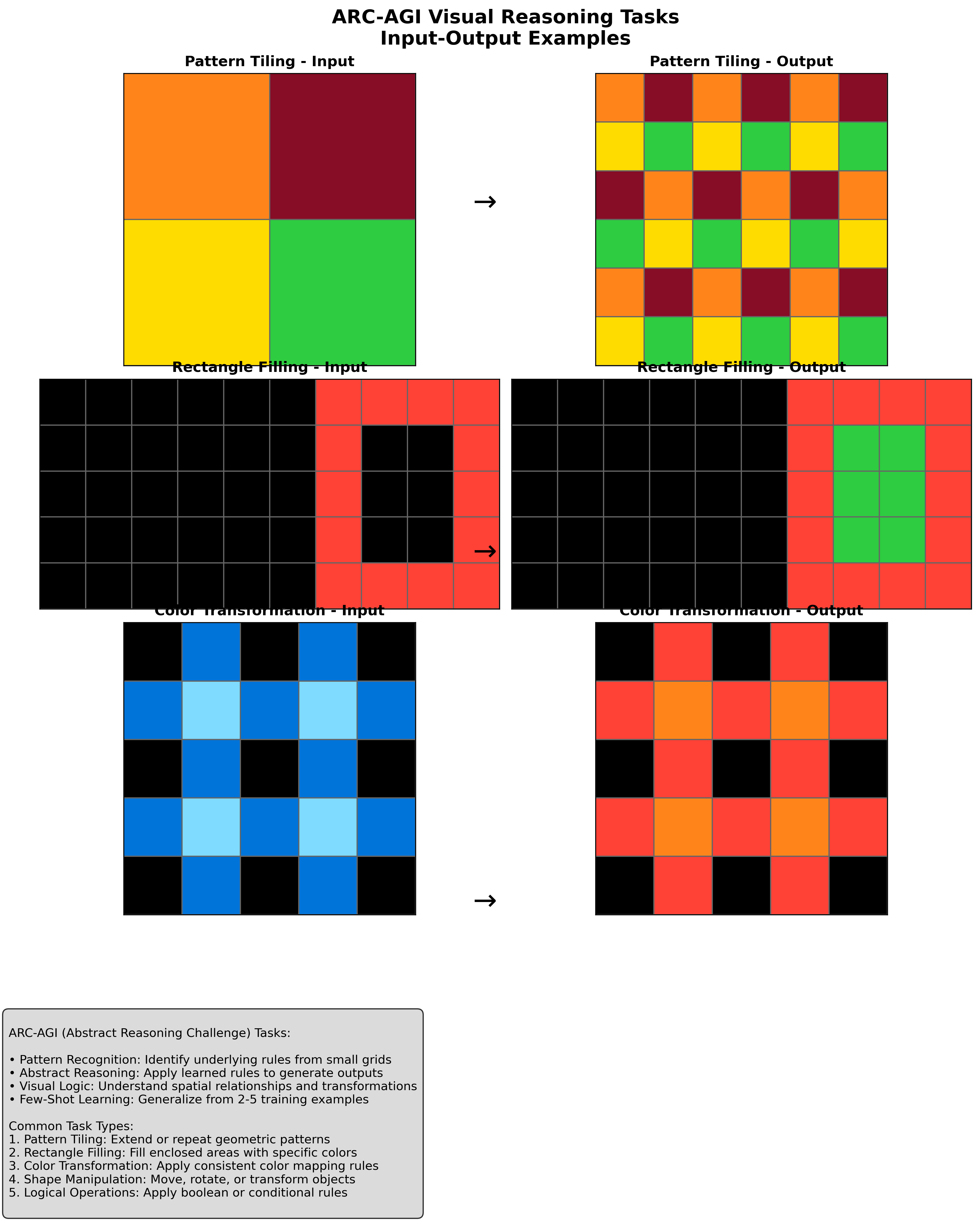
They tested TreeGPT on ARC-AGI-2, a set of visual logic puzzles. Each puzzle shows small colored grids. The task is to figure out the hidden rule from a few examples (like “fill the rectangle,” “extend this pattern,” or “swap these colors”) and then apply it to a new grid.
They ran:
- An ablation study: turn features on/off (edge projection, gating, residuals) to see what actually helps.
- Comparisons to other methods: Transformers, very LLMs, Mamba-style models, and program-synthesis systems.
They trained a small TreeGPT (about 3.16 million parameters) and reported quick convergence (about 1,500 training steps).
What did they find and why does it matter?
Main results:
- Strong accuracy with a tiny model: They report 99% validation accuracy and fast training with only about 3.16M parameters. In ablations, the best test accuracy they highlight is around 96% with a specific setup (edge projection + gating).
- Key design choices:
- Edge projection (the “link labels”) is essential. Without it, performance collapses.
- Adding gating on top of edge projection improves results further.
- Adding too many extras (like always-on residuals) can hurt generalization (risk of overfitting).
- Comparisons: They show much higher scores than several large models on ARC-AGI-2 while being far smaller. The authors do note that differences in evaluation setups could influence these comparisons, so they should be read with care.
Why it matters:
- It challenges the idea that attention is always necessary for reasoning. For some structured puzzles, a lightweight, neighbor-passing approach can work extremely well.
- It suggests that choosing the right architecture for the task can beat simply making a model bigger.
What does this mean for the future?
Implications:
- Specialized designs can shine: If your task has clear structure (like grids, trees, or parent-child relationships), building a model that matches that structure can be better and cheaper than using a giant general model.
- Faster and more efficient AI: Getting rid of attention can reduce computation and training time, which could make reasoning models more accessible and eco-friendlier.
Caveats and next steps:
- Most results come from one main benchmark (ARC-AGI-2). Testing on more datasets and tasks will show how broadly this works.
- The paper sometimes mixes “tree-structured” ideas with “adjacent links,” so future versions could clarify when real tree shapes (like actual parent-child hierarchies) are used versus simple chains.
- More standardized comparisons will help confirm how it stacks up against other methods.
In short, TreeGPT argues that for certain logic puzzles, smart, simple neighbor-passing in both directions—without attention—can be enough to reason well, train fast, and use very few parameters. If confirmed across more tasks, this could inspire a family of small, efficient reasoning models tailored to structured problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and uncertainties that future work could address:
- Architecture consistency
- The paper alternates between claiming a “pure attention-free” design and a “hybrid combining transformer attention with global parent-child aggregation” (e.g., figure captions and Introduction). Clarify whether any attention is used and, if so, specify where and how; provide ablations isolating attention vs TreeFFN-only variants.
- Tree vs. chain discrepancy
- Despite targeting tree-structured reasoning and ASTs, the defined edge sets are strictly sequential adjacencies E={(i,i+1)} and {(i,i−1)}, i.e., a chain graph. Specify how true parent–child edges are constructed and used for ASTs, and evaluate with actual tree connectivity rather than linear neighbors.
- Undefined “global parent–child aggregation”
- The text and figures reference a global parent–child aggregation mechanism, but there is no formal definition, equations, or implementation details. Provide the exact operator, its complexity, and ablations toggling it.
- TreeFFN internals underspecified
- The TreeFFN(H,E) function is a black box: missing precise message/update equations, normalization, activation functions, dimensionalities, and how residuals and gating are composed. Detail the full computation graph to ensure reproducibility.
- Edge feature design is vague
- Edge features e_ij are used (with a projection) but not defined (what features for adjacent edges? positional deltas? types?). Specify how e_ij are constructed, their dimensionality, and alternatives (e.g., positional encodings, learned relation types).
- Receptive field and depth vs. sequence length
- With only adjacent edges and T iterations, the effective receptive field is O(T). With T=2 (as stated), long-range dependencies cannot be captured. Quantify how performance scales with T and sequence/tree depth, and test on tasks requiring long-range dependencies.
- Theoretical capacity and limitations
- No formal analysis of the representational capacity of TreeFFN vs. attention/SSMs for long-range or non-local compositionality. Provide expressivity/approximation guarantees or counterexamples, and conditions under which TreeFFN can emulate attention-like global aggregation.
- Computational complexity and scaling
- While quadratic attention is avoided, the paper lacks asymptotic and empirical scaling analyses in N, depth, and branching factor. Report time/memory vs. input size, number of iterations, and compare end-to-end latency and throughput against strong baselines.
- Decoder role and inference procedure
- The “decoder TreeFFN (R←L)” is mentioned, but task outputs (grid completions) are not clearly autoregressive. Clarify how decoding is performed, what constitutes a “token,” how outputs are generated, and whether teacher forcing or parallel prediction is used.
- Metric definitions and evaluation protocol
- “Validation accuracy,” “test accuracy,” “full accuracy,” and “token-level accuracy” are used inconsistently (e.g., 99% vs. 96% vs. 100%). Define each metric precisely (per-puzzle vs. per-cell), the task split protocol, and how ARC-AGI-2 scoring is computed.
- Dataset/version and split transparency
- The paper mentions ARC-AGI-2 and “ARC Prize 2025” without precise versioning, splits, or task counts. Provide dataset version, train/val/test partitioning, selection criteria, and measures to prevent leakage (e.g., task family overlap).
- Fairness of baseline comparisons
- Comparisons with LLMs, Mamba, and program-synthesis systems may use different data access, training regimes, and evaluation protocols. Re-run controlled baselines under identical training data, compute budgets, and scoring to enable fair conclusions.
- Statistical robustness
- No variance across seeds, confidence intervals, or statistical tests are reported. Provide multi-seed results, significance testing, and sensitivity to initialization, hyperparameters, and random augmentation.
- Ablation anomalies and baseline definition
- “Baseline TreeFFN = 0% accuracy” suggests a degenerate setup; the baseline configuration is not defined. Specify the baseline and explain training failures; include learning curves, optimization settings, and diagnostics.
- Overfitting risk and generalization
- Frequent 100% validation vs. lower test accuracy and inconsistent headline numbers suggest potential overfitting. Add cross-validation, holdout puzzles, OOD splits (e.g., novel color permutations, unseen rule families), and learning-curve analyses.
- Robustness and reliability
- No tests of robustness to noise, occlusion, color remapping, sparsity, adversarial perturbations, or distribution shifts. Evaluate robustness to input corruptions and invariances (e.g., grid rotations/reflections).
- Breadth of domains
- Claims center on ASTs and tree reasoning, yet experiments are only on ARC-style grids. Validate on actual tree-centric benchmarks (e.g., code understanding/generation with real ASTs), structured NLP parsing, molecules, and knowledge graphs.
- Hyperparameters and training details
- Critical details are missing: batch size, learning rate, exact optimizer hyperparameters, regularization, normalization layers, model depth/width per component, and training schedule per experiment. Provide a comprehensive hyperparameter table.
- Hardware and compute budget
- Convergence in 1500 steps is reported without specifying hardware, wall-clock time per step, energy usage, or parallelism settings. Report hardware specs and compute cost to assess efficiency claims.
- Tokenization and data representation
- “Token-level accuracy” is reported, but tokenization/encoding of grids and any auxiliary channels are not described. Specify input/output vocabularies, masking, padding, and positional encoding schemes.
- Handling variable tree sizes and batching
- It is unclear how variable-size trees/sequences are batched, padded, or masked, and how roots are defined across samples. Provide batching/masking strategies and their effect on performance.
- Missing failure mode analysis
- The paper lacks qualitative error analyses. Provide case studies of failures, categorize error types (e.g., long-range, compositional, symmetry-breaking), and link them to architectural limitations.
- Parameter count inconsistency
- The model is alternately described as 3.16M and ~1.5M parameters. Reconcile parameter counts per configuration and report counts for each ablation variant.
- Impact of residuals and gating
- Residual connections reportedly hurt generalization in some settings, but no hypothesis or analysis is provided. Investigate when/why residuals degrade performance and whether normalization or dropout mitigates this.
- Alternative connectivity patterns
- Only nearest-neighbor adjacency is explored. Evaluate learned/dilated neighborhoods, skip connections, or dynamic routing to capture non-local interactions without attention.
- Training objective and regularization
- The loss function(s), auxiliary losses (if any), label smoothing, and regularization strategies are not specified. Detail objectives and assess their impact via ablations.
- Reproducibility beyond code release
- The repository link is provided, but a reproducibility checklist (commit hash, exact configs, seeds, environment, dependency versions) is not. Add a thorough reproducibility package and scripts to recreate tables/figures.
- Theoretical or empirical justification for “attention not necessary”
- The claim that attention is unnecessary for these tasks lacks controlled experiments on tasks requiring global, non-local reasoning. Construct benchmarks that require true global dependencies and compare TreeFFN vs. attention/SSMs under matched conditions.
Collections
Sign up for free to add this paper to one or more collections.

