- The paper demonstrates that pre-trained speech models (HuBERT, WavLM, XEUS) can effectively encode and classify animal vocalizations in bioacoustic tasks.
- It introduces linear probing combined with time-weighted averaging to leverage contextual information in lengthy animal sound recordings.
- The study highlights that robustness to noise and frequency variations is essential for adapting speech models to diverse bioacoustic applications.
Crossing the Species Divide: Transfer Learning from Speech to Animal Sounds
This paper investigates the transfer of self-supervised speech models to bioacoustic detection and classification tasks, highlighting the potential of speech-based models in bioacoustic research. The study primarily focuses on the adaptation of models like HuBERT, WavLM, and XEUS for processing animal sounds across various species and taxa.
Introduction
Self-supervised learning (SSL) has significantly enhanced speech processing through models trained on large unlabeled datasets, achieving notable performance improvements in linguistic tasks. This paper examines whether these advancements can be extended to animal vocalizations, which are less supported by extensive labeled datasets. The authors aim to understand the cross-domain transferability of pre-trained speech representations to bioacoustic tasks.
Methods
The authors employed three pre-trained SSL speech models: HuBERT, WavLM, and XEUS, to assess their ability to generate enriched representations of animal sounds. The models were evaluated on 11 bioacoustic tasks spanning various species. Linear probing and time-weighted averaging (T-WA) of representations were introduced to leverage contextual information which could be crucial for long sound samples.
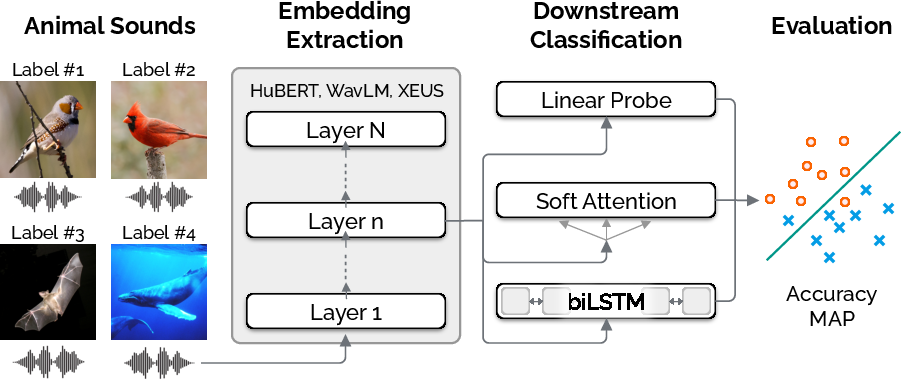
Figure 1: Workflow of the transfer learning method.
The study utilized the publicly available BEANS benchmark to extract datasets featuring tasks such as animal species classification, individual identification, and call-type detection. Evaluations were conducted using accuracy and mean average precision (mAP) metrics, ensuring compatibility with pre-trained speech models' data sample rate requirements.
Results
The results demonstrated that HuBERT, WavLM, and XEUS models are capable of encoding sufficient bioacoustic information to perform well across various animal taxa. Best performance was observed between speech model layers 3-11 for HuBERT, 4-15 for WavLM, and 2-6 for XEUS, aligning with previous research which shows superior representation capabilities in non-deep layers. Notable performance improvements were observed using time-weighted averaging, particularly in datasets with longer sound samples.
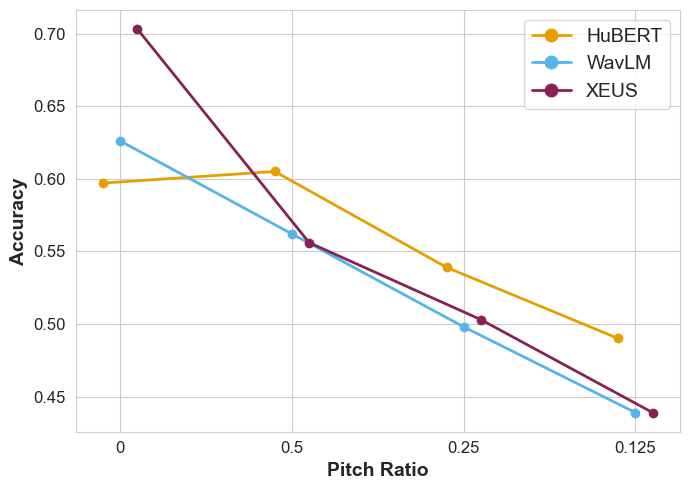
Figure 2: Performance for the Egyptian fruit bats dataset on the 10th layer with pitch shifting (T-A).
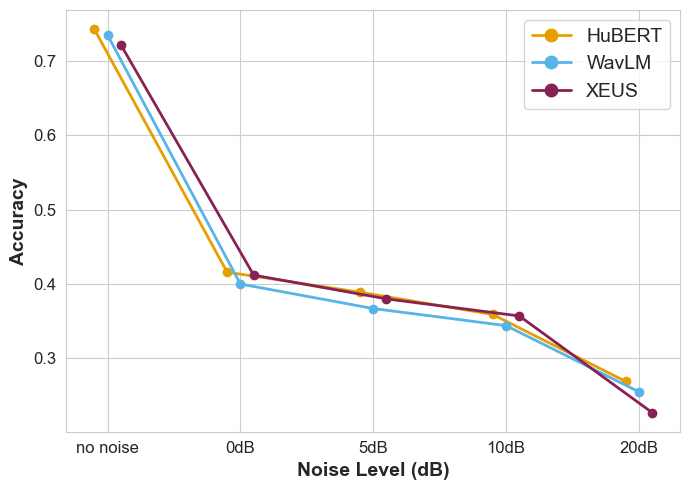
Figure 3: Performance for the Egyptian fruit bats dataset on the 10th layer with noise addition (T-A).
Discussion
The study explores four main factors impacting performance: model robustness to noise, overlapping species vocalizations, time-related representation, and frequency range variances with speech.
Model Robustness and Cross-species Transfer
Pre-training setups incorporating noise reduction strategies (WavLM and XEUS) resulted in improved robustness against low signal-to-noise ratios, common in bioacoustic data. The multilingual pre-training of XEUS further contributed to superior performance, although an assessment against simpler baseline models revealed substantial intrinsic capabilities without extensive pre-training.
Temporal Analysis
Time-wise representation was crucial, and preserving variability showed advantages in datasets featuring lengthy recordings. Linear probes efficiently extracted signal information, outperforming more complex recurrent model setups.
Frequency and Noise Impact
Shifting frequencies and managing noise levels provided deeper insights into model limitations, with observations indicating robustness across varying frequency ranges. However, extreme manipulations failed to enhance bioacoustic signal clarity beyond certain thresholds.
Conclusion
The studied speech models exhibit strong potential for bioacoustic applications, providing a competitive alternative to domain-specific models. Speech-based SSL frameworks present viable pathways for bioacoustic research, suggesting future advancements through enhanced pre-training strategies and robust data management. The utilization of foundation models shared between human speech and animal sounds could lead to significant breakthroughs in computational bioacoustics.
Overall, this paper underscores the efficiency and adaptability of speech models in bioacoustic scenarios, advocating for continued exploration into cross-domain transfer learning methodologies.