- The paper introduces app.build, a framework that employs environment scaffolding to iteratively validate and repair generated applications.
- It decomposes user prompts into sandboxed, stack-specific stages with rigorous testing, ensuring high viability and quality across different technology stacks.
- Empirical results reveal cost-effective trade-offs between open and closed LLM models, underscoring the importance of environmental engineering over model scaling.
app.build: Scaling Agentic Prompt-to-App Generation via Environment Scaffolding
Introduction
The paper introduces app.build, an open-source framework designed to address the reliability gap in LLM-driven application generation by shifting from model-centric to environment-centric paradigms. The central thesis is that production-grade agentic software engineering requires not only advanced models but also robust, structured environments that enforce deterministic validation, runtime isolation, and iterative repair. The framework operationalizes these principles through environment scaffolding (ES), which constrains agent actions, validates outputs at each stage, and orchestrates stack-specific workflows. This approach is empirically validated across multiple stacks and model backends, demonstrating substantial improvements in viability and quality of generated applications.
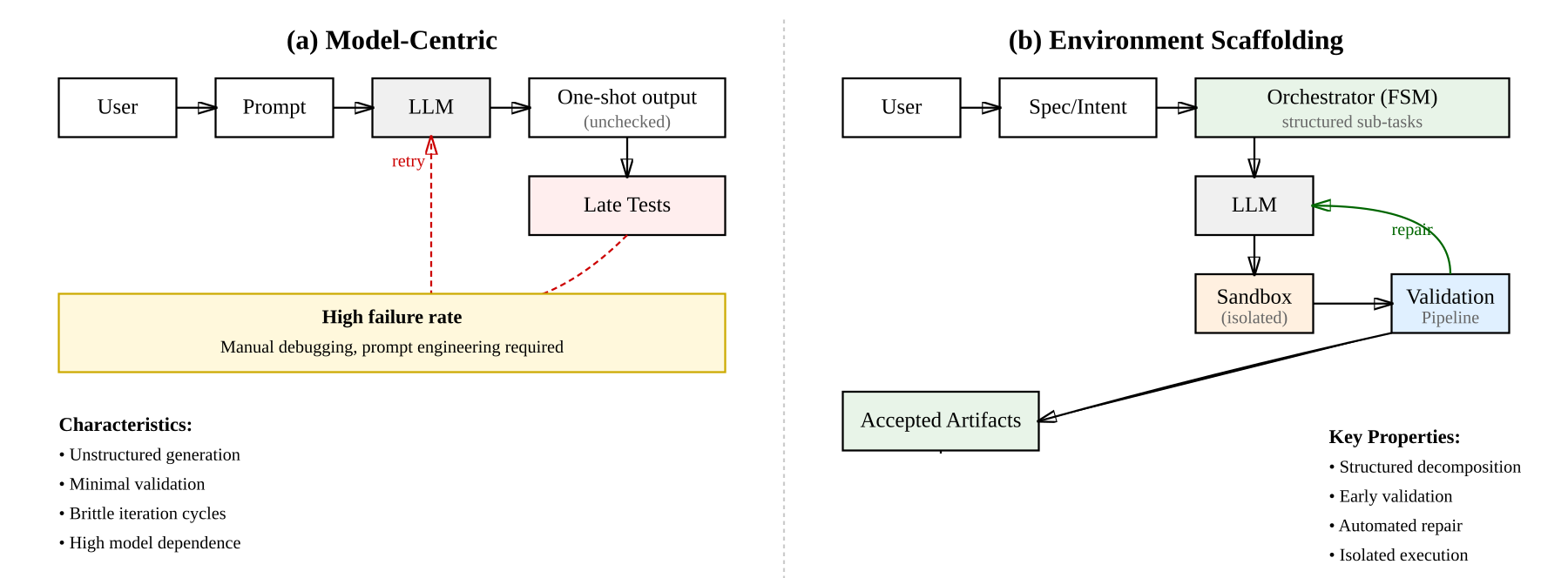
Figure 1: Environment scaffolding vs. model-centric generation. ES wraps the model with a finite, validated workflow that catches errors early and repairs them before proceeding.
Environment Scaffolding Paradigm
Environment scaffolding is formalized as an environment-first methodology for LLM-based code generation. The agent operates within a sandboxed, deterministic workflow, decomposing tasks into explicit stages (e.g., schema → API → UI), each with well-defined inputs, outputs, and acceptance criteria. Multi-layered validation is integral: linters, type-checkers, unit/smoke tests, and runtime logs are executed after every significant generation, enabling early error detection and automatic repair. Runtime isolation is achieved via containerized sandboxes, ensuring safe trial-and-error and reproducibility. The architecture is model-agnostic, allowing backend LLMs to be swapped without altering the workflow.
This paradigm contrasts sharply with model-centric approaches, which typically prompt the LLM for end-to-end solutions with minimal intermediate validation. ES enforces a guarded, iterative loop—generate, validate, repair—at each sub-task, resulting in higher reliability and observability.
app.build Architecture
The app.build agent implements ES through a central orchestrator that decomposes user specifications into stack-specific stages. Each stage is executed in an isolated sandbox, validated, and only then merged into the final artifact. The framework supports TypeScript/tRPC, PHP/Laravel, and Python/NiceGUI stacks, with stack-aware validators (e.g., ESLint, Playwright, PHPStan, pytest). Managed Postgres databases and CI/CD hooks are provisioned for full-stack integration.
The execution loop for each sub-task involves context assembly, LLM prompting, sandboxed execution, validator feedback collection, and iterative repair. This design enables parallelization and caching of environment layers, facilitating scalable agentic workflows.
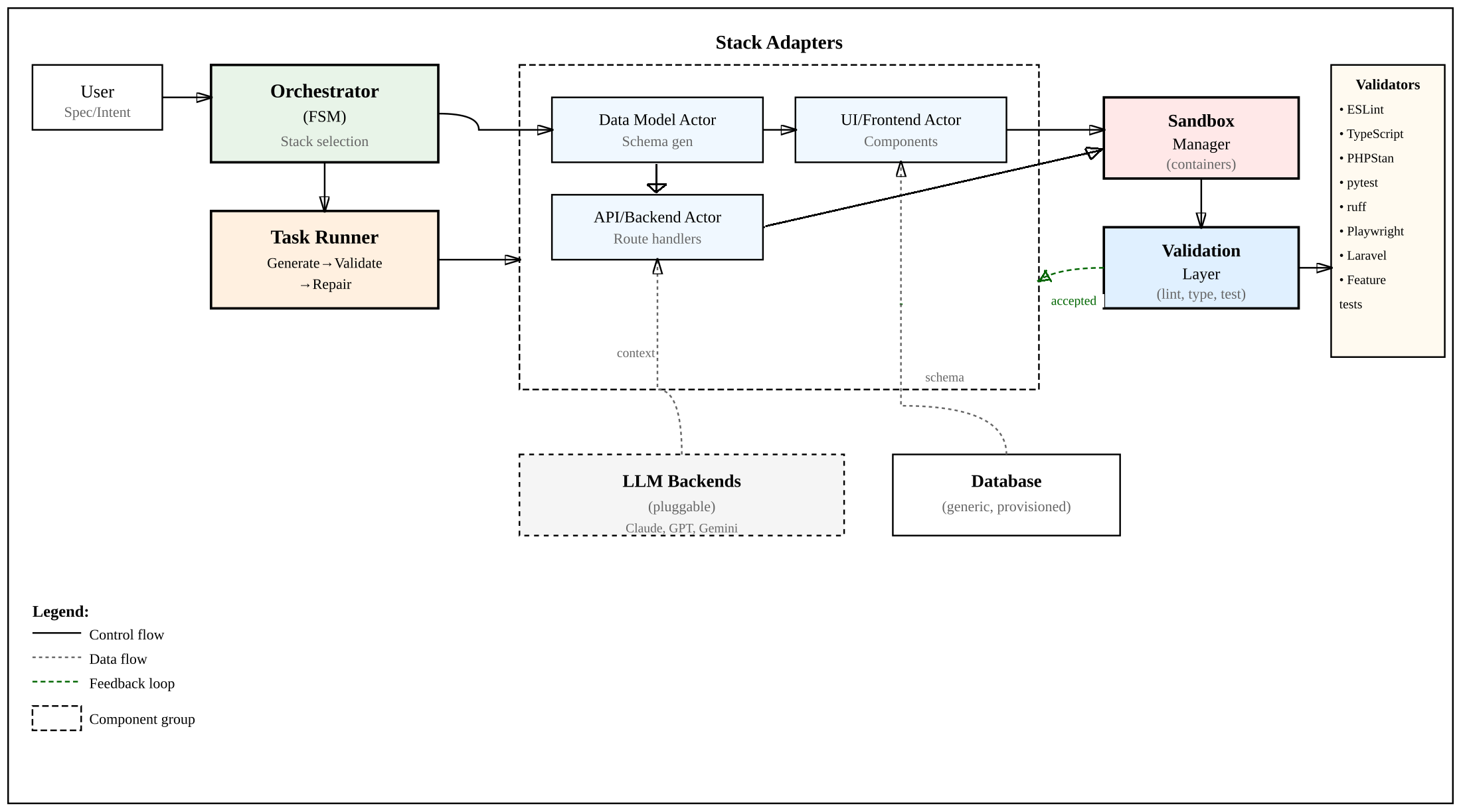
Figure 2: app.build architecture expressed through environment scaffolding. The orchestrator plans stages per stack; each sub-task runs in a sandbox, is validated, and only then merged. CI/CD and DB provisioning are integrated.
Experimental Evaluation
Dataset and Metrics
Evaluation is conducted on a dataset of 30 prompts spanning low, medium, and high complexity application scenarios. Metrics include viability rate (V), perfect quality rate (Q=10), quality distribution, validation pass rates, and model/cost comparisons. Viability is determined by passing boot and prompt correspondence checks; quality is scored on a 0–10 scale based on six standardized functional checks.
Results: Environment Scaffolding Impact
On the TypeScript/tRPC stack, 73.3% of generated applications were viable, with 30% achieving perfect quality and a mean quality score of 8.78 among viable apps. Non-viability was primarily due to failures in smoke tests or missing artifacts. Once viability criteria were met, applications exhibited consistently high quality.
Claude Sonnet 4 (closed model) achieved an 86.7% success rate at \$110.20 total cost. Qwen3-Coder-480B-A35B (open-weights) reached 70% success (80.8% relative performance) at \$12.68, and GPT OSS 120B managed 30% at \$4.55. Open models required more validation retries, with higher LLM call counts and lower healthcheck pass rates, indicating syntactic correctness but integration-level deficiencies. The 9x cost reduction for a 19% performance loss with Qwen3 represents a viable tradeoff for many production scenarios.
Ablation Studies: Validation Layer Impact
Ablation experiments reveal the following:
- Unit/Handler Tests: Removing backend tests increases viability (+6.7 pp) but degrades CRUD correctness, especially in view/edit operations.
- Linting: Disabling ESLint yields a slight quality improvement (+0.19) but mixed effects on create/view operations, suggesting some lint rules are overly restrictive.
- Playwright/E2E Tests: Removing E2E tests significantly improves viability (+16.7 pp) and quality (+0.56), indicating brittleness in current UI test suites.
Optimal validation strategy retains lightweight smoke tests and backend unit tests, refines linting rules, and replaces full E2E suites with targeted integration tests.
Failure Modes and Prompt Complexity
Failure modes cluster into boot/load failures, prompt correspondence errors, CSP/security restrictions, UI interaction defects, state/integration issues, and component misuse. Early pipeline gates catch non-viable builds, while later stages expose interaction and state consistency issues.
Prompt complexity analysis shows medium-complexity CRUD prompts yield the highest quality, while low-complexity UI prompts are not uniformly easy due to template failures. High-complexity prompts suffer lower viability due to interaction and state wiring challenges.
Implications and Future Directions
The empirical results substantiate the claim that environment scaffolding and validation layers are more critical than model scaling for production reliability. The framework demonstrates that open-weights models, when paired with robust environments, can approach closed-model performance at a fraction of the cost. This has significant implications for democratizing agentic software engineering and reducing operational expenses.
Theoretically, the work advances the field by formalizing environment scaffolding as a first-class design principle, shifting focus from model-centric to system-centric AI engineering. Practically, the open-source release and community adoption provide a reproducible foundation for benchmarking and scaling agent environments.
Future developments should address support for more complex systems, advanced integrations, and scalable human evaluation protocols. Further research into adaptive validation strategies and automated test generation could enhance robustness and generalizability.
Conclusion
The app.build framework demonstrates that reliable agentic application generation is contingent on principled environment engineering rather than solely on model improvements. Systematic environment scaffolding, multi-layered validation, and stack-specific orchestration transform probabilistic LLMs into dependable software engineering agents. Ablation studies highlight the trade-offs in validation design, supporting a pragmatic approach that balances defect detection with minimizing brittleness. The path to scalable, production-grade AI agents lies in environment-centric design, robust validation, and open, reproducible frameworks.

