- The paper introduces a novel timestamp matrix that enables precise temporal control in text-to-audio synthesis, resolving limitations in previous models.
- It employs a dual data approach by converting temporally coarse captions into detailed, timestamped annotations using both real and synthetic datasets.
- Experiments show that PicoAudio2 outperforms existing methods with improved metrics (FD, IS, MOS, and Seg-F₁), demonstrating its effectiveness in producing high-quality, temporally accurate audio.
PicoAudio2: Advancements in Text-to-Audio Generation with Temporal Control
Introduction
The paper presents PicoAudio2, a framework designed for text-to-audio (TTA) generation with enhanced temporal controllability. Unlike previous models which primarily rely on synthetic datasets, PicoAudio2 incorporates a combination of real and simulated data, improving both audio quality and flexibility in processing free-text queries. This addresses significant limitations seen with models like Make-An-Audio 2 (MAA2) and AudioComposer, which either lack fine temporal control or suffer in quality due to dataset constraints. The introduction of a timestamp matrix aligned with free-text inputs represents a notable architectural enhancement in achieving precise audio generation.
Temporally-Aligned Data Curation
The challenge in TTA models is the alignment of audio with natural language descriptions. Traditionally, datasets like AudioCaps provide audio-caption pairs without precise temporal annotations, limiting the temporal control of generated audio. PicoAudio2 tackles this by developing robust pipelines for both synthetic and real data, converting temporally coarse captions (TCC) into temporally detailed captions (TDC), hence producing temporally strong datasets.
Simulation Data
For synthetic data, AudioTime's approach is extended by mapping categorical labels to free-text via LLMs and then aligning these labels with timestamps (Section 2). The conversion from structured categories to free text enhances the flexibility and richness of the descriptions compatible with PicoAudio2's learning objectives.
Real Data
In real data processing, PicoAudio2 utilizes the Text-to-Audio Grounding (TAG) model to extract timestamps, which are further curated to avoid overlap and omissions, ensuring high-quality dataset creation. This dual approach not only bridges the gap between real and simulated dataset distributions but also enriches the model's versatility in handling natural language inputs.
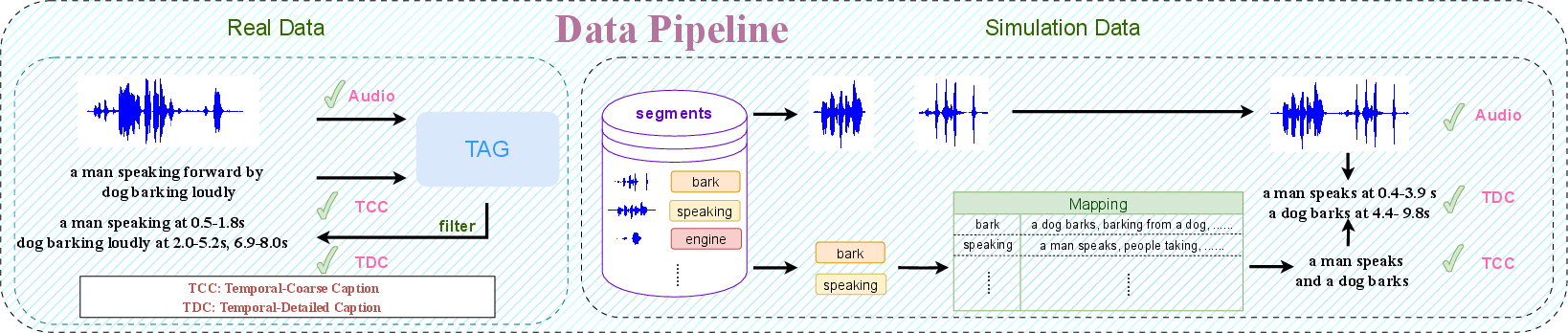
Figure 1: The data curation pipeline.
PicoAudio2 Framework
The framework is built around a Diffusion Transformer backbone, a timestamp encoder, and a VAE. A key innovation is the introduction of a timestamp matrix, which extracts detailed temporal cues from TDC, while allowing temporally weak data to be augmented strategically. By separating temporal cues from textual semantics, this design achieves effective control over event timing within generated audio, a significant improvement over prior methods that lacked this granularity.
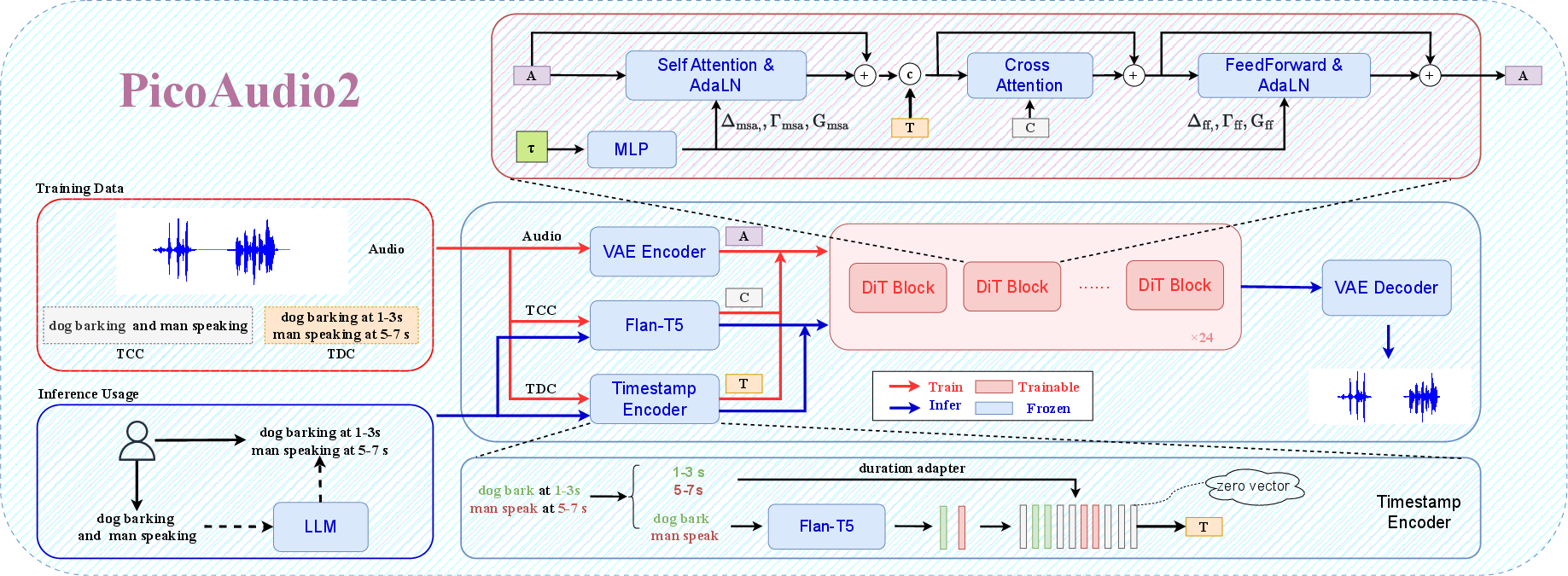
Figure 2: PicoAudio2 framework.
Experiments and Evaluation
Quantitative evaluations showcased PicoAudio2's capabilities over leading models. It delivers superior temporal accuracy and audio quality, validated through metrics like FD and IS, as well as subjective evaluations such as MOS (Section 5). The temporal controllability is notably improved due to PicoAudio2's timestamp matrix, as evidenced in Seg-F1 measurements which outperform existing benchmarks.
Results
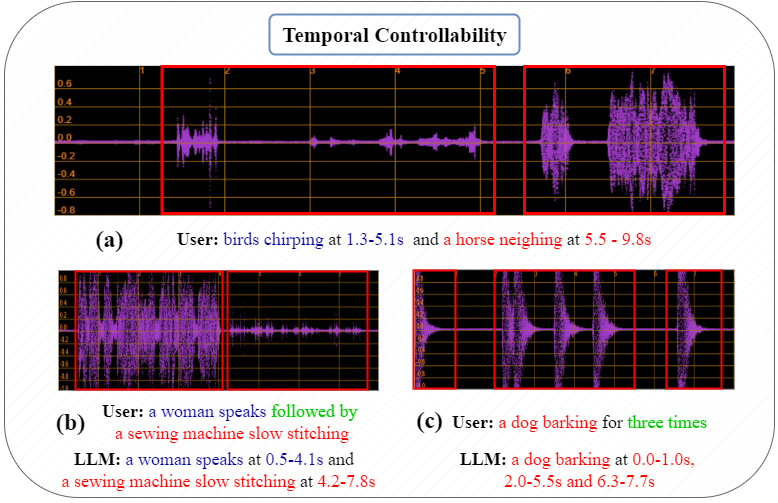
Figure 3: Temporal control transformation during inference.
Conclusion
PicoAudio2 addresses the critical issue of temporal alignment in TTA by integrating timestamped data annotations with a flexible model architecture that comprehends free-text inputs. The framework's reliance on both simulated and real datasets ensures a robust audio generation pipeline, capable of delivering enhanced audio quality and precise temporal control. The proposed methodology opens avenues for future work in improving annotations for overlapping events, thereby enhancing real-world applicability.
In conclusion, PicoAudio2 represents a significant step forward in synthesizing temporally accurate and high-quality audio outputs from natural language inputs, offering both theoretical contributions to the field and practical solutions adaptable to audio-based applications.