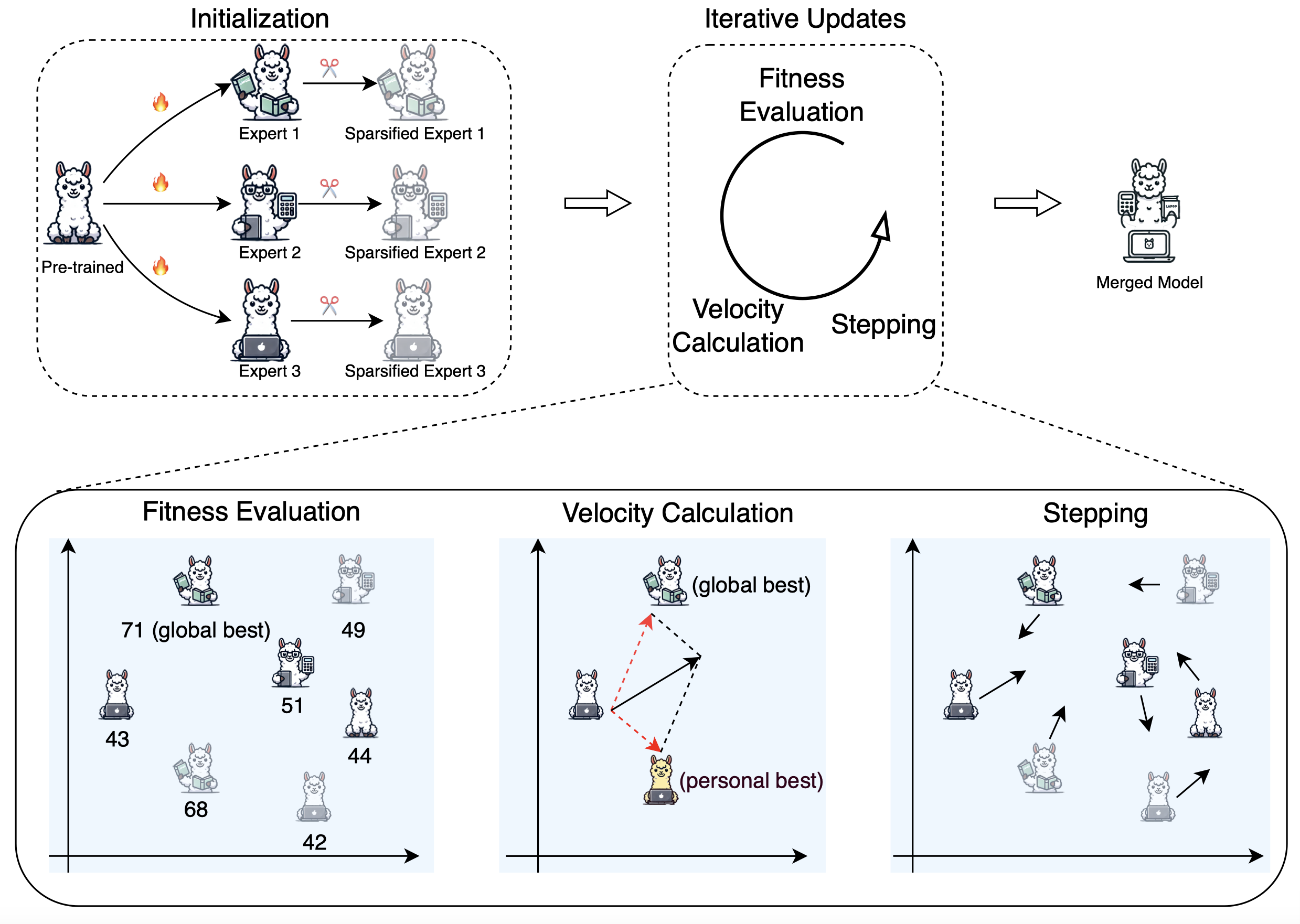
PSO-Merging: Merging Models Based on Particle Swarm Optimization
Abstract: Model merging has emerged as an efficient strategy for constructing multitask models by integrating the strengths of multiple available expert models, thereby reducing the need to fine-tune a pre-trained model for all the tasks from scratch. Existing data-independent methods struggle with performance limitations due to the lack of data-driven guidance. Data-driven approaches also face key challenges: gradient-based methods are computationally expensive, limiting their practicality for merging large expert models, whereas existing gradient-free methods often fail to achieve satisfactory results within a limited number of optimization steps. To address these limitations, this paper introduces PSO-Merging, a novel data-driven merging method based on the Particle Swarm Optimization (PSO). In this approach, we initialize the particle swarm with a pre-trained model, expert models, and sparsified expert models. We then perform multiple iterations, with the final global best particle serving as the merged model. Experimental results on different LLMs show that PSO-Merging generally outperforms baseline merging methods, offering a more efficient and scalable solution for model merging.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
- Generality across bases/architectures: No evaluation of merging experts trained on different base checkpoints or architectures (e.g., cross-family merges like Mistral + Llama, or dense + MoE). How to align incompatible parameter spaces?
- Scalability to many experts: Only up to four experts are merged; no evidence or analysis for merging dozens/hundreds of experts commonly found in real-world model zoos. What are compute/memory and performance scaling laws w.r.t. number of experts?
- Sensitivity to optimization data: Fitness uses very small labeled sets (e.g., 50 samples per GLUE task, 1:10 splits elsewhere). How does performance vary with data size, noise, domain shift, and label scarcity?
- Label-free setting: The method assumes labeled fitness for accuracy/pass@1/judged win rate. How to define robust, effective unsupervised or weakly supervised fitness functions when labels are unavailable?
- Overfitting risks: Limited exploration of overfitting to tiny optimization sets. How does the merged model generalize under distribution shift and to unseen tasks?
- Variance across seeds: PSO and sparsification are stochastic, but no multi-seed runs or confidence intervals are reported. What is the variance in outcomes and success probability?
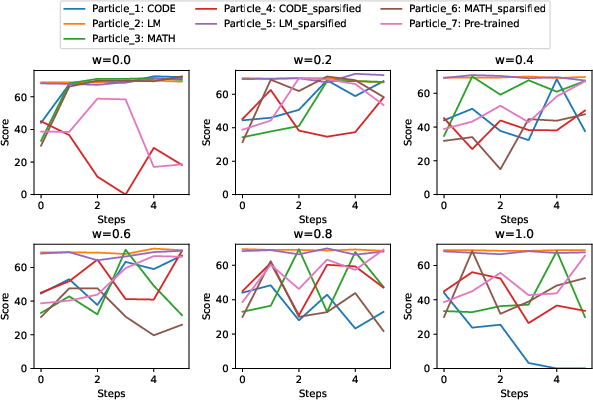
- Hyperparameter sensitivity: Only the inertia term is explored. No systematic ablation for , , number of steps , sparsification drop rate , or particle count. What are robust default settings and interactions?
- Task weighting and trade-offs: Fitness is an unweighted average across tasks. How do different task weights or multi-objective formulations (e.g., Pareto optimization) affect regressions and trade-offs?
- Constraint handling: No mechanisms to constrain updates (e.g., velocity clipping, norm bounds, convex-hull constraints). Do constraints improve stability, prevent out-of-manifold drifts, or reduce regressions?
- Per-layer/per-module search: PSO operates on full parameter vectors; no exploration of layer-wise, block-wise, or module-wise PSO (e.g., attention vs MLP), which may reduce conflicts and improve control.
- Convergence theory and schedules: No theoretical guarantees or empirical study of PSO inertia/acceleration scheduling (e.g., decaying ) commonly used in PSO to balance exploration/exploitation.
- Memory/time accounting: Reported memory numbers lack detail on storing multiple particles and velocities for 7B–13B models. What are precise wall-clock, FLOPs, and peak memory vs baselines as particle count grows?
- Implementation practicality: Storing and updating velocity tensors for billions of parameters across multiple particles is nontrivial. Are memory mapping, sharded storage, or on-the-fly recombination required, and how do they affect speed/accuracy?
- Sparsification design: Only DARE-style random sparsification with is used. How do alternative sparsifiers (magnitude, Fisher, structured, per-layer) and different values impact conflicts and accuracy?
- Initial particle composition: Limited analysis of how many and which particles (experts, sparsified experts, base) are most beneficial. What are diminishing returns and optimal portfolio construction strategies?
- Comparison breadth: No comparison against Model Swarms or other recent iterative/data-driven mergers beyond CMA-ES; gradient-based baselines are omitted for larger models. How does PSO-Merging fare under equalized resource budgets and tuned baselines?
- LoRA/adapter space merging: Only full-weight merging is studied. Can PSO search over LoRA deltas or low-rank subspaces for better efficiency, controllability, and memory use?
- Expert quality and conflict handling: No diagnostics for identifying harmful experts or task conflicts prior to merging. Can PSO be augmented with expert selection, gating, or penalization for conflict-prone experts?
- Domain/task coverage: Benchmarks are limited (GLUE, GSM8K, MBPP, AlpacaEval, SciQ). No evaluation on multilingual, long-context, code reasoning beyond MBPP, retrieval-Augmented tasks, or safety/toxicity/factuality.
- Negative side effects: No analysis of catastrophic forgetting of base capabilities, calibration, hallucination rates, or robustness (adversarial/noisy inputs) after merging.
- Alignment and safety preservation: Merging may degrade RLHF/DPO alignment properties. How to preserve refusal behavior, safety policies, and preference consistency during PSO updates?
- Evaluation noise and judge bias: AlpacaEval uses an LLM judge (Llama-3.1-70B) with potential bias/variance; no agreement checks with human raters or multiple judges. How robust are wins to judge choice and prompt variations?
- Statistical significance: No confidence intervals or statistical tests; single runs per configuration. Are observed gains statistically reliable across seeds and re-trains of experts?
- Quantization compatibility: No results for post-merge 8-bit/4-bit quantization or QAT. Does PSO-Merging preserve quantization performance and calibration?
- Licensing and provenance: Merging experts with heterogeneous licenses or data provenance may raise legal/ethical concerns. What are permissible combinations and compliance checks?
- Incremental/continual merging: How to add new experts later without revisiting earlier data or re-running from scratch? Can PSO support warm-started or streaming merging regimes?
- Runtime scaling with experts: No empirical curves of runtime/memory vs number of experts and particles. What are practical limits on commodity hardware?
- Alternative fitness objectives: Beyond task scores, can validation loss/perplexity, ensemble agreement, uncertainty proxies, or contrastive objectives serve as reliable, label-free fitness signals?
- Regularization toward base/expert: No use of regularizers (e.g., Fisher/Elastic Weight Consolidation) during PSO. Do such constraints mitigate regressions and stabilize updates?
- Geometry of weight space: No analysis linking improvements to linear-mode connectivity or low-dimensional subspaces. Can PSO operate in learned subspaces (PCA, task subspaces) to improve sample efficiency?
- Interpretability/probing: No study of how merging alters representations or neuron/module functions. Can probes explain task transfer or interference patterns induced by PSO?
- Reproducibility details: Exact seeds, hardware, dataset partitions, and trained expert checkpoints for Llama-3-8B/Mistral are not fully specified/released. Can others replicate results end-to-end?
Collections
Sign up for free to add this paper to one or more collections.

