- The paper demonstrates that gating mechanisms dynamically modulate effective learning rates through state-space coupling in RNNs.
- It uses theoretical derivations and canonical sequence simulations to show that gates induce anisotropic gradient directions and concentrated parameter updates.
- The study links gating effects with adaptive optimization strategies like Adam, suggesting hybrid approaches to enhance RNN robustness and trainability.
Introduction
The paper "Time-Scale Coupling Between States and Parameters in Recurrent Neural Networks" (2508.12121) examines how gating mechanisms within recurrent neural networks (RNNs) impact learning rate dynamics despite a fixed global learning rate during training. The authors explore the coupling between state-space time scales, controlled by gates, and parameter dynamics during gradient descent. Through theoretical derivations, simulations, and comparisons, the study reveals how gates influence optimization trajectories and connect to existing adaptive optimization strategies such as Adam.
State-Space Dynamics and Time-Scale Modeling in RNNs
Continuous to Discrete Time
RNNs' continuous-time dynamics are discretized for computational tractability. Derived state equations show how gating functions transform these dynamics, introducing adaptive neuron-specific time scales.
Gating Mechanisms
Gating functions were modeled to consider both scalar gates, affecting all neurons uniformly, and multi-dimensional gates, assigning unique time scales to individual neurons. The paper formalizes these models mathematically, transforming state equations into forms that allow gates to act as time-warps.
Gradient Descent and Time-Scale Coupling
Jacobian Matrices and Learning Dynamics
Theoretical contributions include precise derivations for Jacobian matrices, central to understanding state perturbations and their backward propagation impact on gradients. The analysis reveals that gates modulate learning rates through interaction with these Jacobian structures.
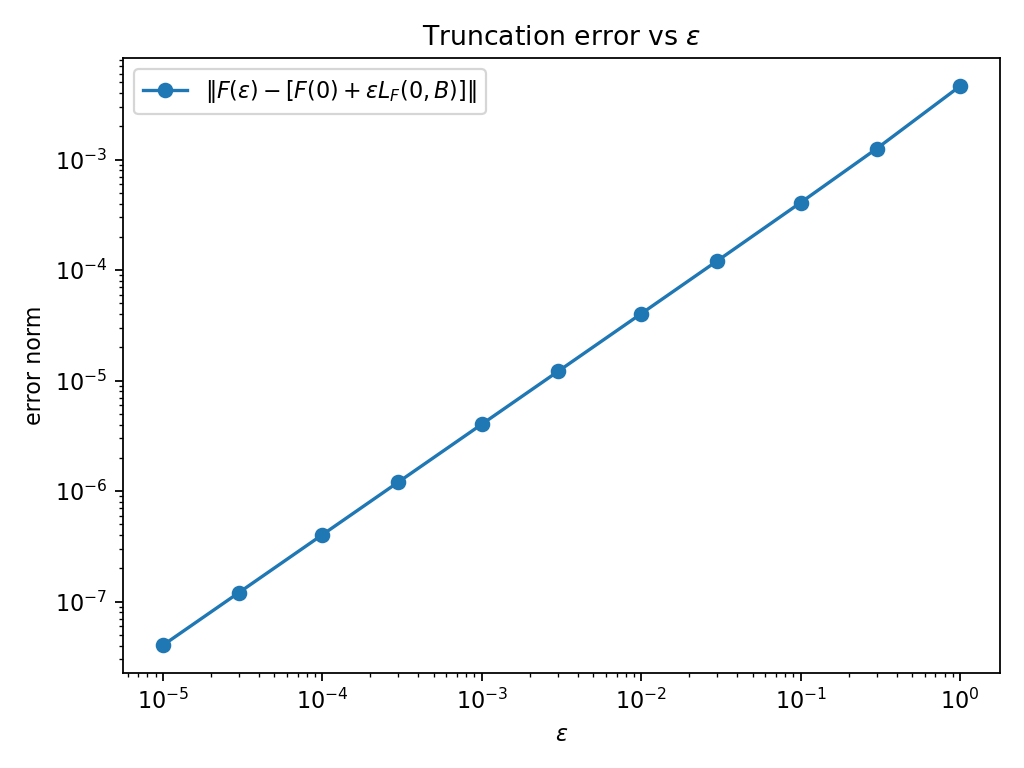
Figure 1: First-order truncation error vs.\ ε for the scalar gate case.
Effective Learning Rates
The impact of gating is shown to produce effective learning rates that differ from nominal global rates, heavily influenced by temporal dynamics embedded in state-space models.
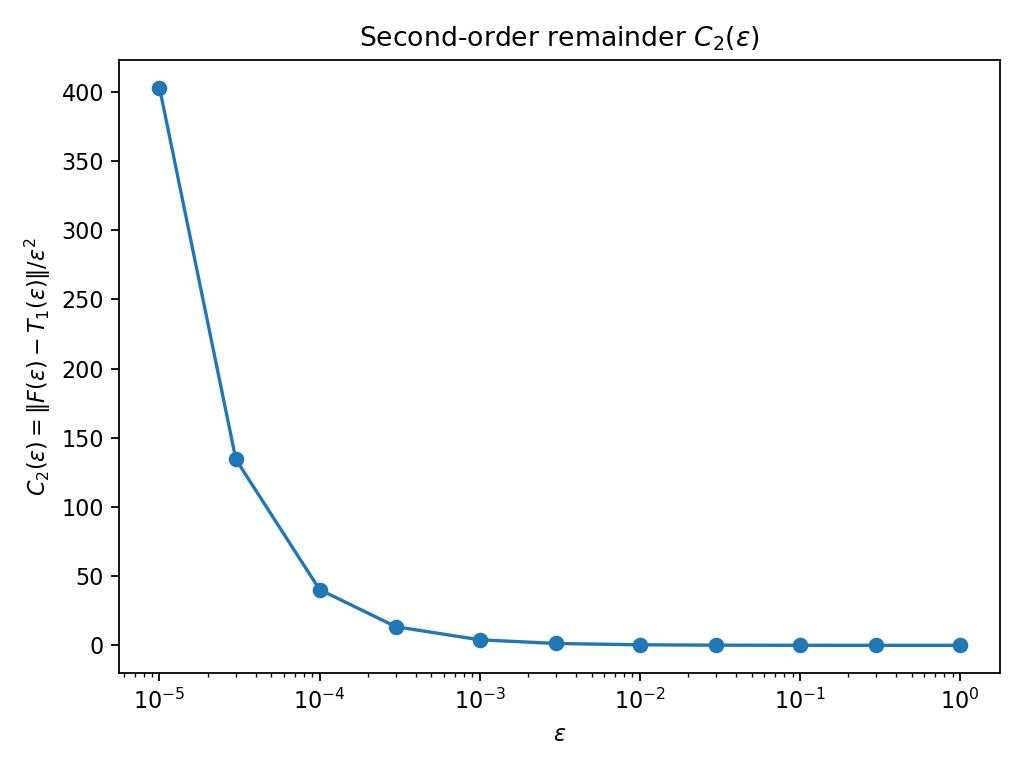
Figure 2: Second-order remainder C2(ε) for the scalar gate case.
Connections to Adaptive Optimization Methods
The authors draw parallels between gates' effects on gradient propagation and established adaptive optimization methods:
- Constant gates mimic fixed preconditioning;
- Time-varying scalar gates resemble learning rate schedules;
- Multi-gate systems emulate adaptive optimizers like Adam, with neuron-specific learning rate modulation and increased anisotropy due to perturbative contributions.
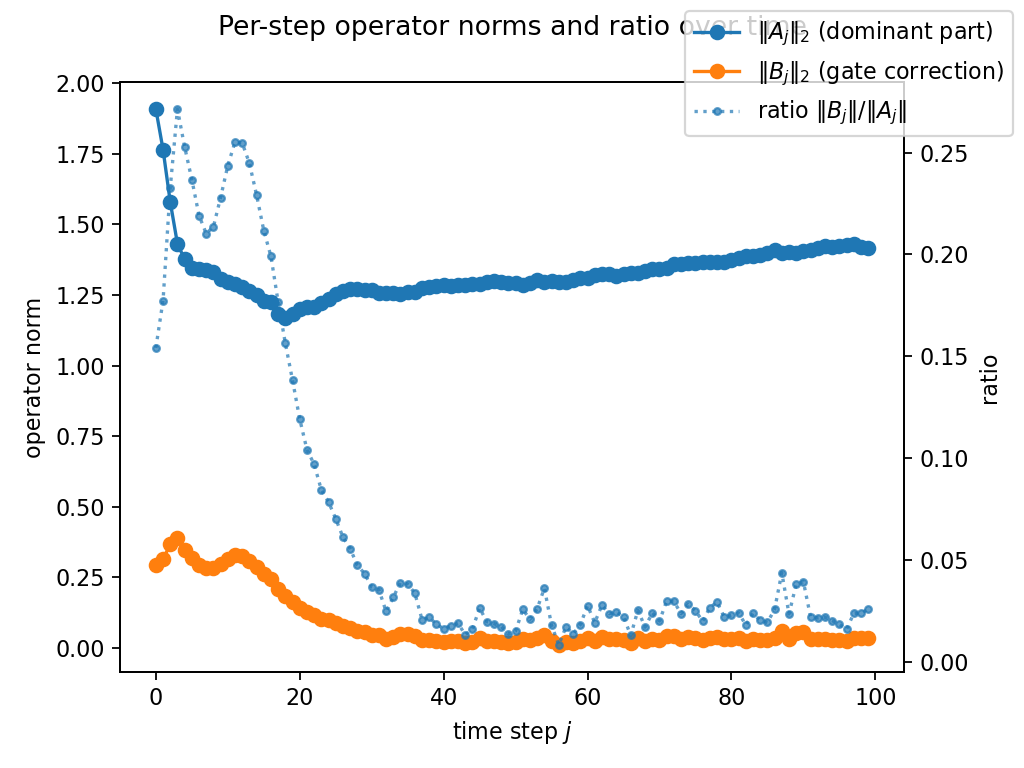
Figure 3: Per-step norms ∥Aj∥2 (dominant part), ∥Bj∥2 (gate correction), and their ratio over time for the scalar gate case.
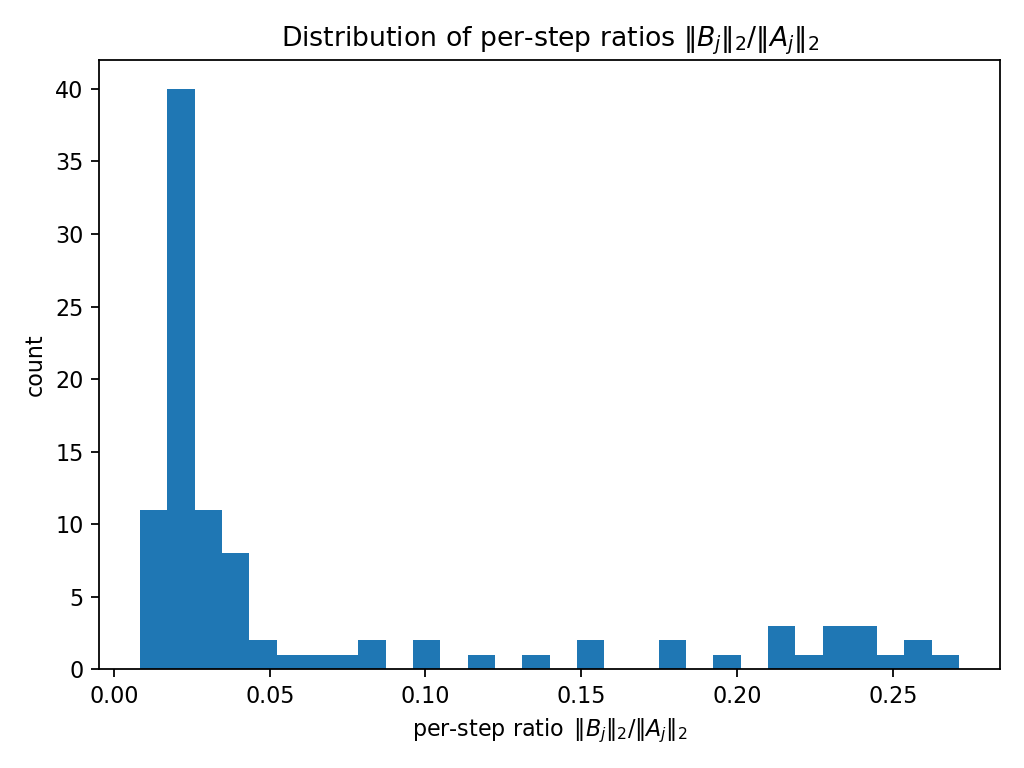
Figure 4: Distribution of per-step ratios ∥Bj∥2/∥Aj∥2 for the scalar gate case.
Empirical Validation
Simulation Results
The simulations involve canonical sequence tasks, revealing that gates induce significant gradient direction concentration. Multiple figures demonstrate empirical profiles of effective learning rates and directional concentration, with fitted models providing accurate predictions.
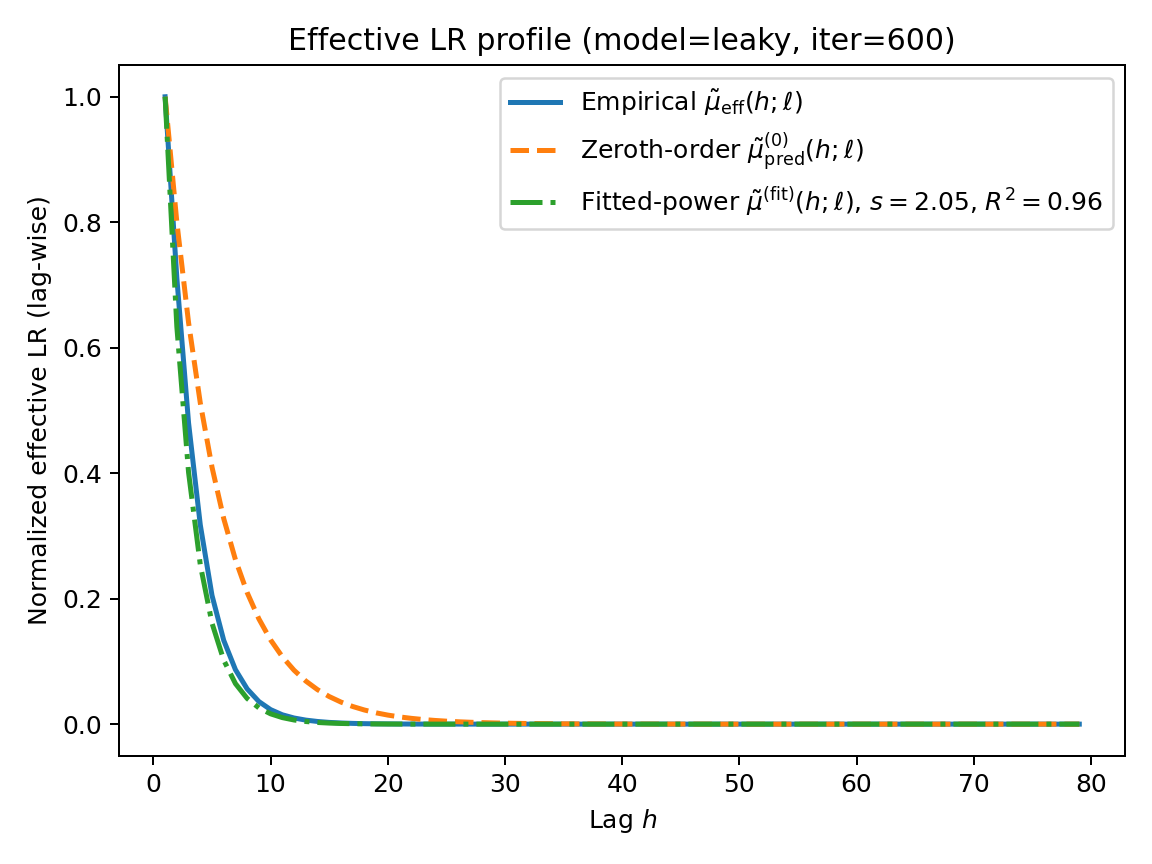
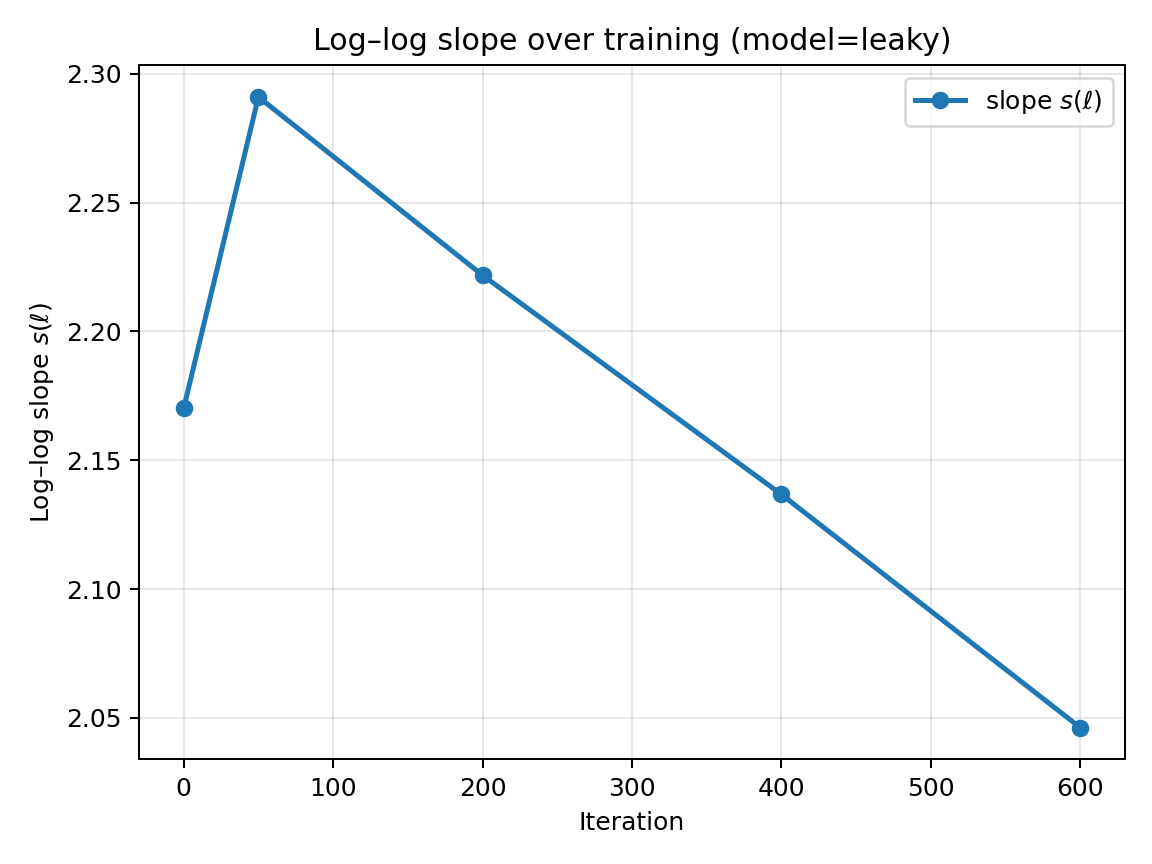
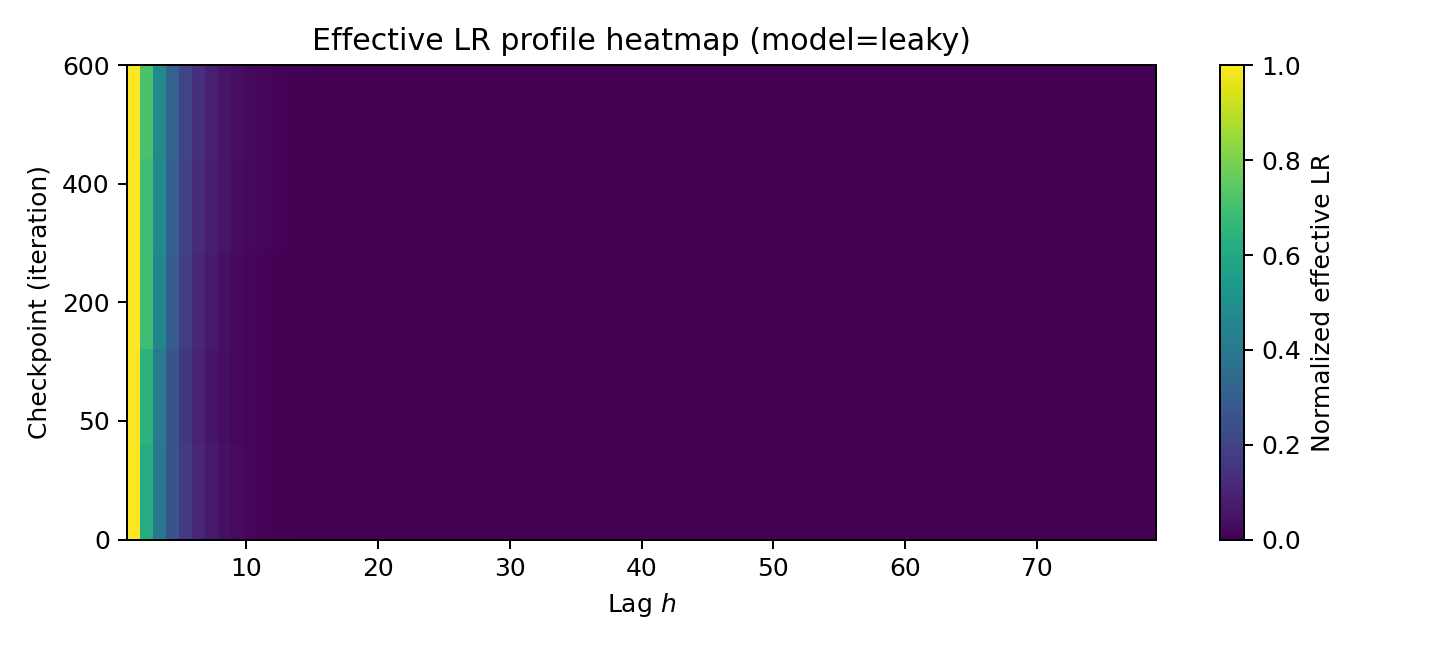
Figure 5: Leaky RNN (constant alpha): normalized effective LR profile at final checkpoint (left), slope s(ℓ) across iterations (middle), and full sensitivity heatmap St,k.
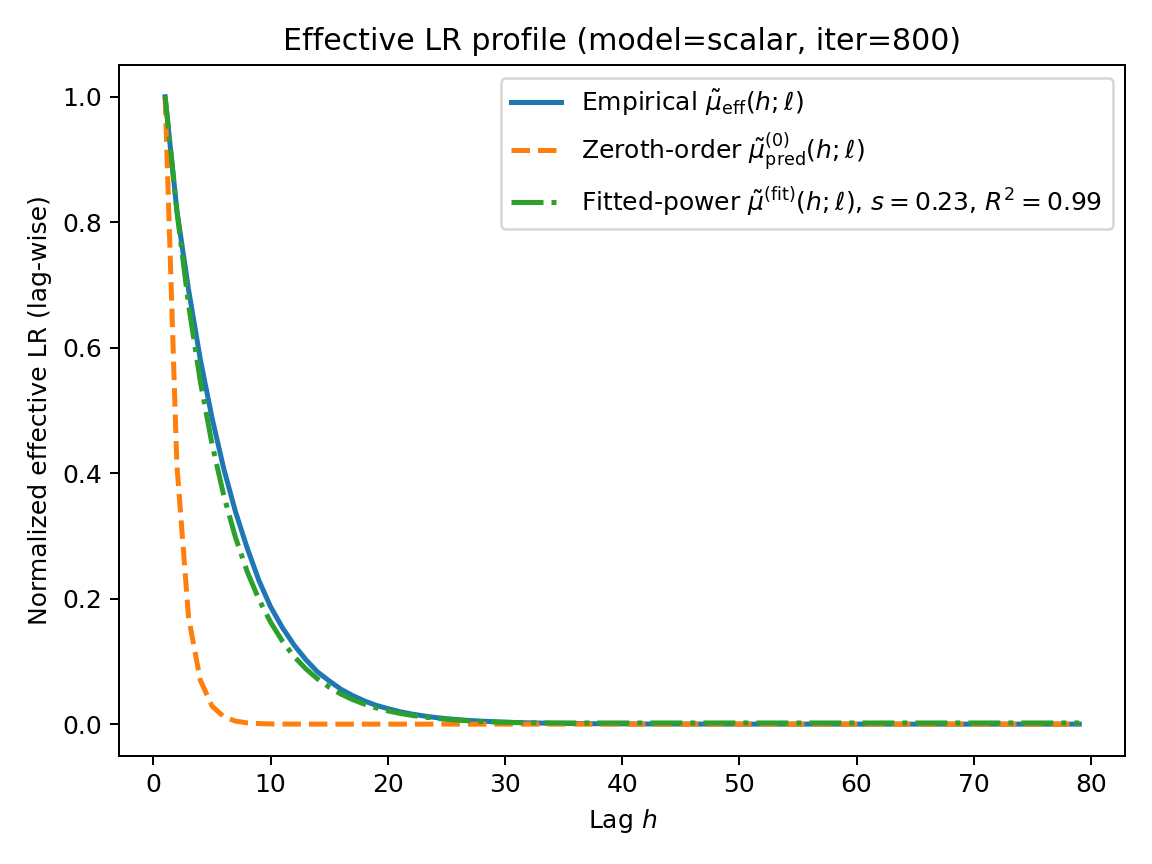
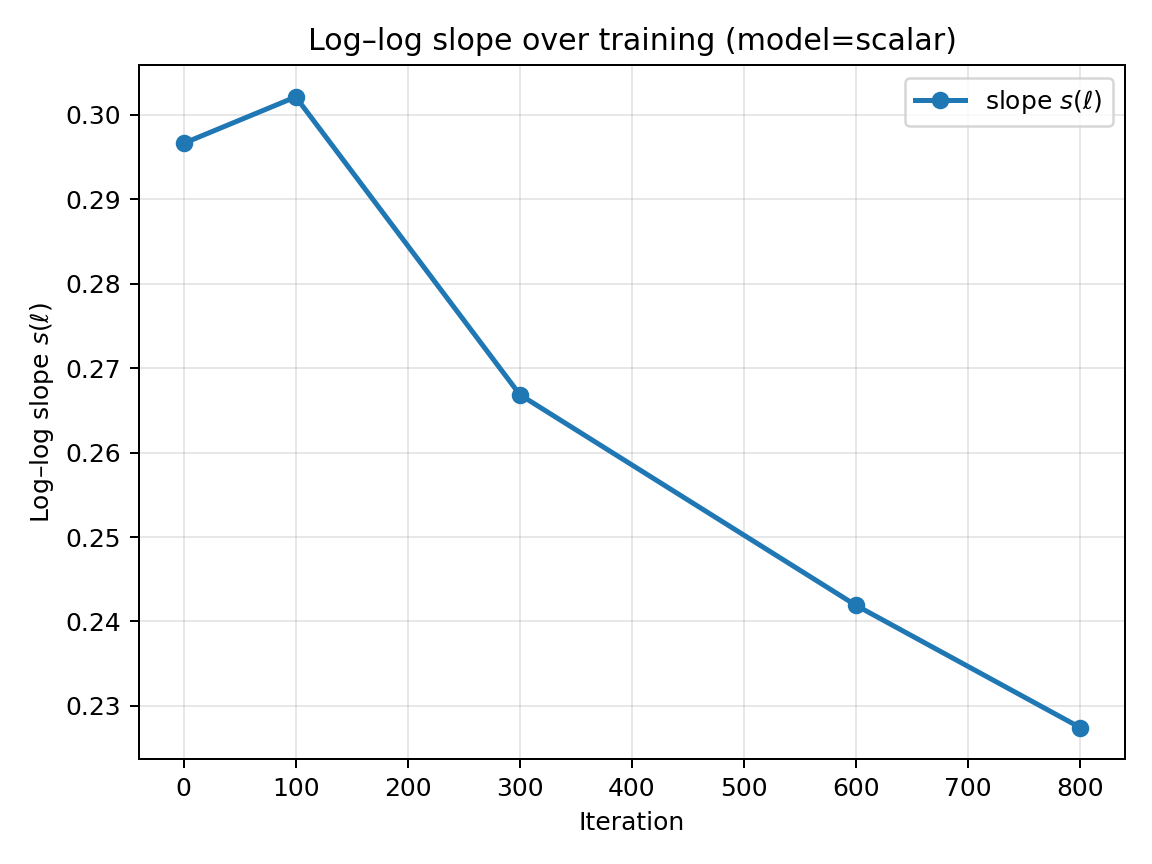
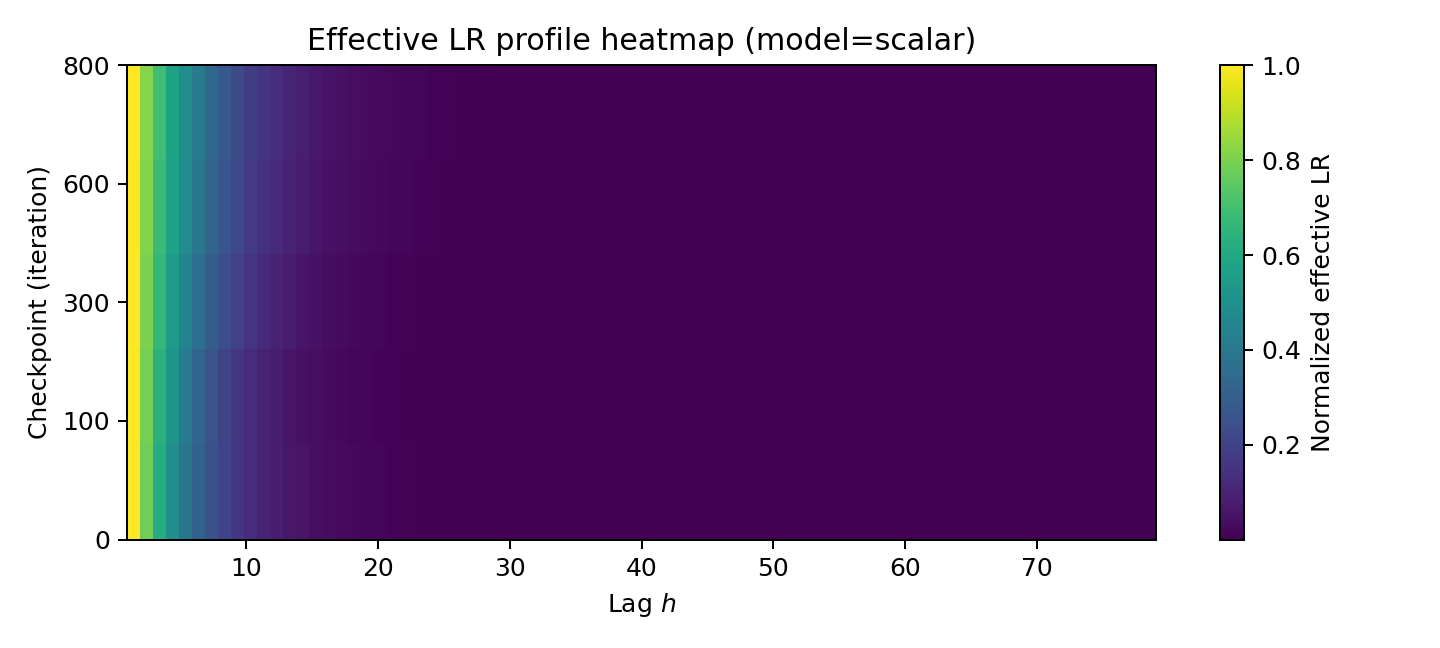
Figure 6: Scalar-gated RNN: normalized effective LR profile at final checkpoint (left), slope s(ℓ) across iterations (middle), and full sensitivity heatmap St,k.
Anisotropy and Update Dynamics
Directional anisotropy metrics confirm that gates concentrate parameter updates into low-dimensional spaces far more than optimizers like Adam, illustrating deeper structural effects.
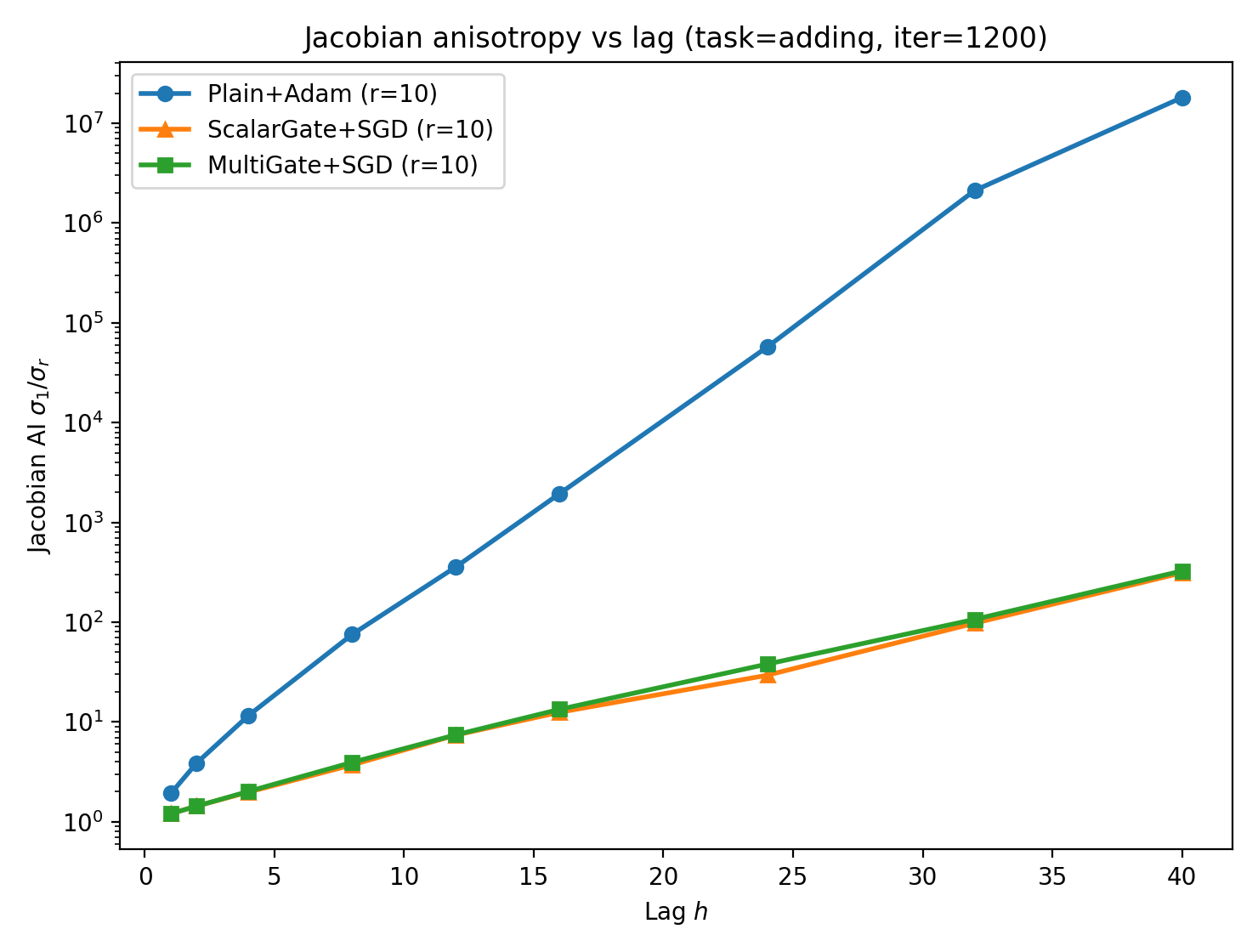
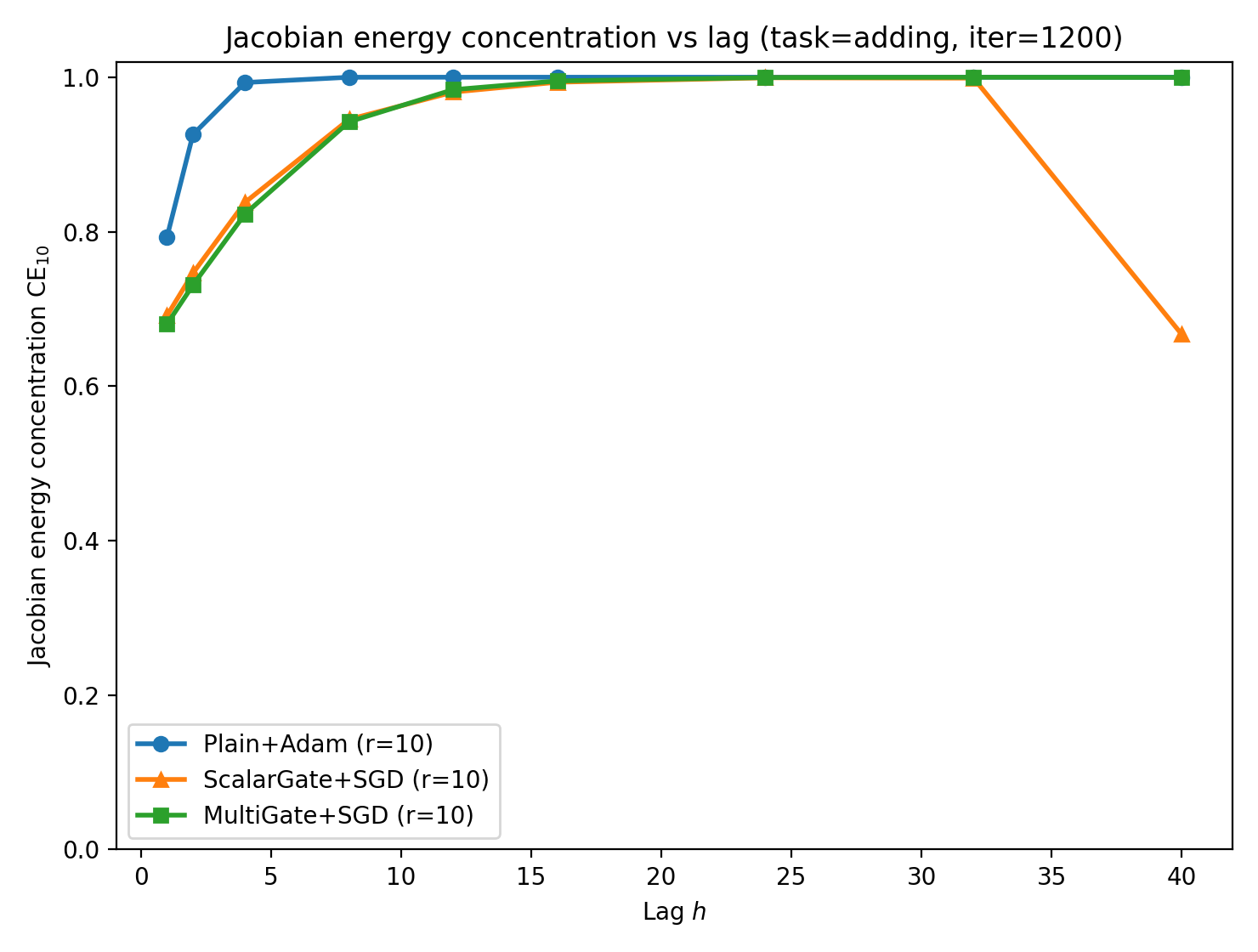
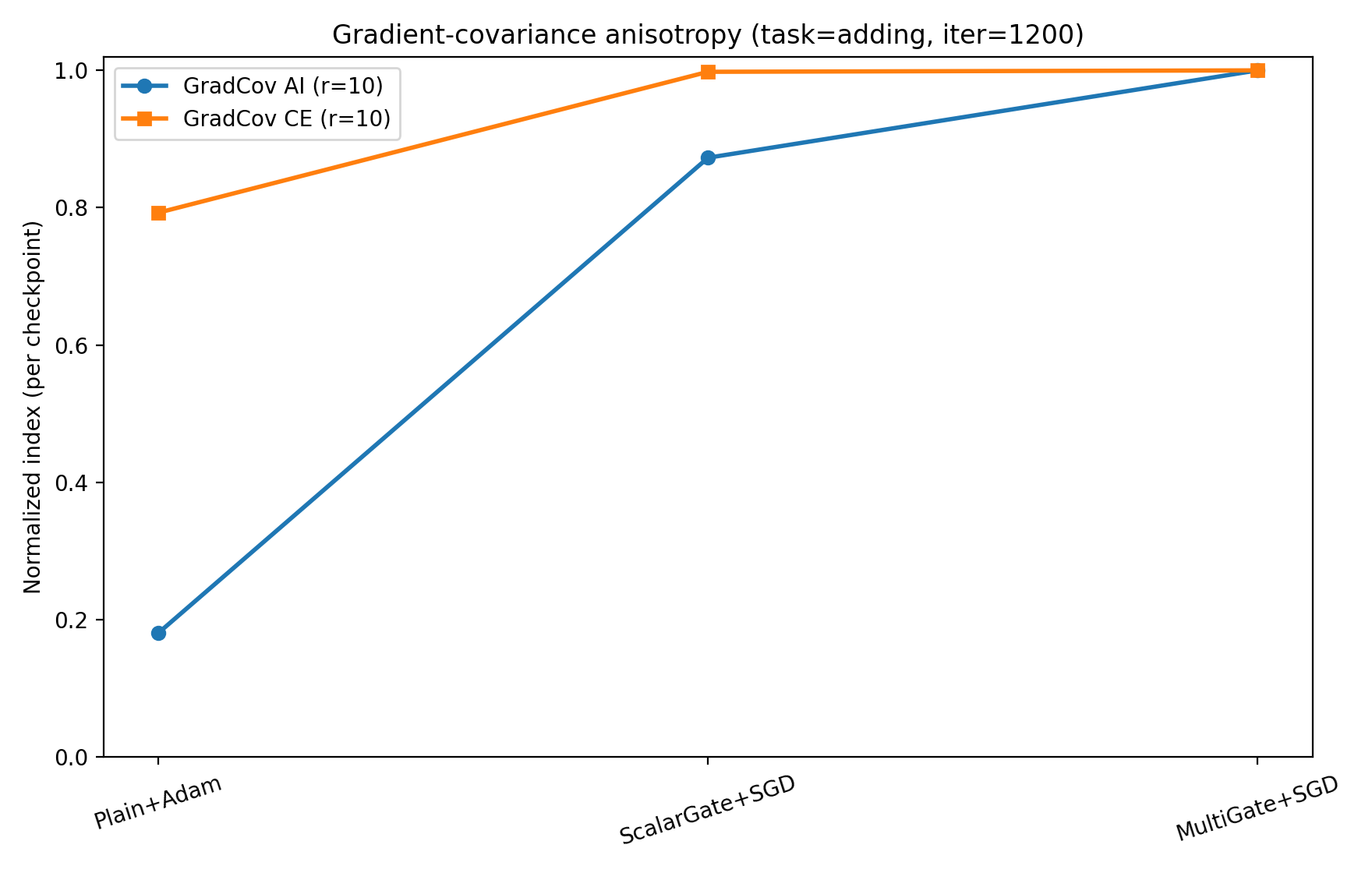
Figure 7: Adding task. Left/middle: propagation anisotropy (AI, CE) vs.\ lag. Bottom: update anisotropy from gradient covariance (higher is more concentrated).
Broader Implications
The study suggests critical interactions between architectural design and optimizer strategies. Gates fundamentally alter temporal dynamics, impacting how RNNs learn and adapt. Designing architectures with appropriate gating can optimize both learning rates and anisotropic properties, enhancing model robustness and efficiency.
Conclusion
The research provides significant insights into how gating mechanisms in RNNs act as dynamic preconditioners. This nuanced understanding lays the groundwork for developing hybrid optimization strategies that leverage both gating and adaptive algorithms to improve trainability and stability for challenging sequence modeling tasks. Future work could extend these findings to other architectures such as LSTMs and Transformers, further advancing the unified perspective on state-parameter coupling in neural networks.