- The paper introduces FutureX, a live benchmark evaluating LLM agents on future prediction tasks using an automated, multi-stage pipeline.
- It demonstrates that integrated search and reasoning capabilities yield higher accuracy, especially on challenging open-ended tasks across various domains.
- Experimental results reveal significant performance variability by difficulty tier and domain, offering actionable insights for advancing agentic AI research.
FutureX: A Live Benchmark for LLM Agents in Future Prediction
Motivation and Benchmark Design
The paper introduces FutureX, a live, large-scale benchmark for evaluating LLM agents on future prediction tasks. Unlike prior benchmarks that focus on static, closed-world tasks or simulated environments, FutureX is designed to assess agents' ability to synthesize dynamic, real-world information, reason under uncertainty, and make predictions about events whose outcomes are not yet known at prediction time. This design eliminates data contamination and logical leakage, which are persistent issues in retrospective or static benchmarks.
FutureX operates through a fully automated pipeline (with the exception of initial event database construction), supporting daily updates and continuous evaluation. The pipeline consists of four stages: event database construction, daily curation of future events, agent prediction, and answer acquisition.

Figure 1: The FutureX pipeline, showing the automated stages from event database construction to answer acquisition.
The event database is curated from 195 high-quality, frequently updated websites spanning 11 domains, including politics, economics, finance, technology, sports, and entertainment. The curation process leverages both LLM-based agents and human experts to ensure event quality and answer verifiability. Daily and weekly event curation transforms raw data into prediction tasks of varying types and difficulty, with rigorous filtering to remove trivial, harmful, or subjective events.
Figure 2: The daily curation process, illustrating event filtering and manipulation to ensure high-quality, diverse prediction tasks.
Benchmark Structure and Evaluation Protocol
FutureX features a diverse set of event types: single-choice, multi-choice, open-ended ranking, and open-ended numerical prediction. Events are stratified into four difficulty tiers—Basic, Wide Search, Deep Search, and Super Agent—corresponding to increasing requirements for planning, reasoning, and search capabilities.
The evaluation protocol is prospective: agents make predictions before event resolution, and ground-truth outcomes are collected only after the resolution date. This ensures that no agent can exploit historical leakage or retrieval contamination. The evaluation metrics are tailored to event type, including 0-1 accuracy, F1-score, partial credit for ranking overlap, and volatility-adjusted scoring for numerical predictions.
A key design choice is the one-week prediction window, balancing event diversity and evaluation latency. The pipeline is robust to missing predictions, with statistical analysis showing minimal impact on overall score variance.
Experimental Results and Analysis
FutureX evaluates 25 models across four categories: base LLMs, LLMs with search/reasoning, open-source deep research agents, and closed-source deep research agents. The benchmark weights higher-difficulty tiers more heavily in the overall score.
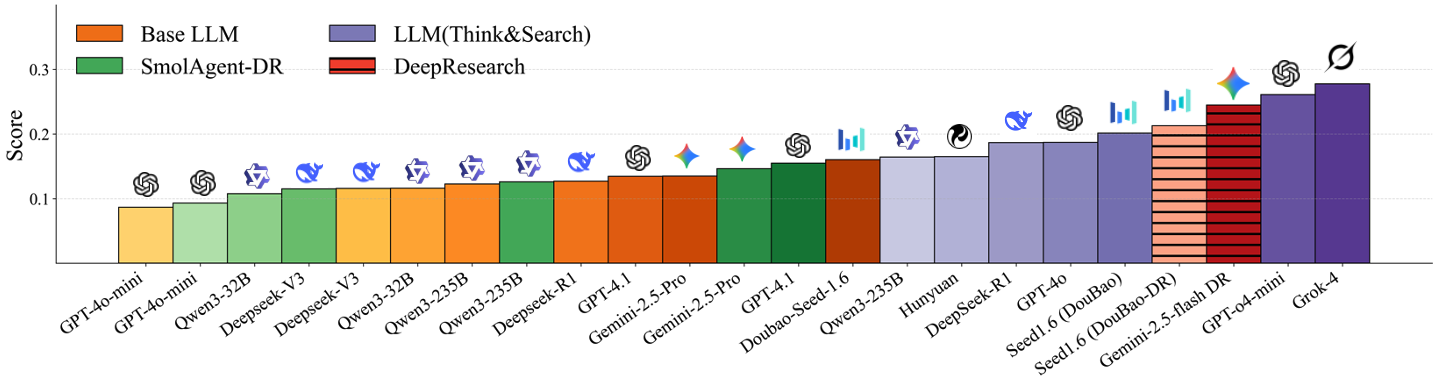
Figure 3: Overall scores on FutureX between July 20th and August 3rd, comparing 25 models across four categories.
Key Findings
- Difficulty Stratification: There is a clear, monotonic decline in model performance from Basic to Super Agent tiers, validating the benchmark's difficulty design. Most models perform well on simple single/multi-choice tasks but degrade sharply on open-ended, high-volatility events.
- Search and Tool Use: Models with integrated search and reasoning capabilities significantly outperform base LLMs on complex tasks. Grok-4 and GPT-o4-mini (Think+Search) achieve the highest scores on the most challenging events, balancing accuracy and inference speed.
- Base LLMs: DouBao-Seed1.6-Thinking demonstrates strong performance on knowledge-retrieval tasks, outperforming some agentic models on lower tiers.
- Domain Variation: Performance varies by domain; for example, GPT models excel in crypto and technology, while DouBao-Seed1.6-Thinking leads in finance and business.
- Human Comparison: Human experts consistently outperform LLM agents on most tiers, except for some multi-choice tasks where exhaustive option comparison favors models.
- Factor Analysis: Linear regression confirms that difficulty tier and domain are the most significant predictors of model performance, with top models aligning with the overall leaderboard.
Focused Case Studies
Past vs. Future Prediction
A controlled experiment comparing past-prediction (after event resolution) and future-prediction (before event resolution) demonstrates that search-augmented models like Grok-4 excel at retrieving resolved outcomes, but the gap between past and future prediction highlights the challenge of true forecasting.
Agent Planning and Search Behavior
Analysis of SmolAgent's planning memory reveals that plan comprehensiveness, source reliability, and actionable steps are strongly correlated with prediction accuracy. Models that invoke more tool calls and cite authoritative sources perform better, while excessive dialogue history introduces noise.
Real-Time and Adversarial Robustness
- Financial Forecasting: LLM agents approach, but do not surpass, professional Wall Street analysts in S&P 500 earnings and revenue prediction, with the best models achieving win rates of 33–37%.
- Fake Website Vulnerability: Most deep research agents are susceptible to adversarially crafted fake websites, except for Gemini-2.5-Pro Deep Research, which appears to leverage domain credibility signals to avoid citation.
- Real-Time Search: In time-sensitive tasks (e.g., live sports scores), GPT-o3 Deep Research demonstrates the strongest real-time retrieval, but even specialized agents do not consistently outperform general-purpose search-augmented LLMs.
Implications and Future Directions
FutureX establishes a new standard for evaluating LLM agents in dynamic, real-world settings. By eliminating data contamination and supporting continuous, automated evaluation, it enables robust measurement of agents' adaptive reasoning and information synthesis capabilities. The benchmark exposes current limitations in open-ended reasoning, real-time search, and adversarial robustness, providing actionable insights for future agent development.
Practically, FutureX can drive progress in domains where timely, accurate forecasting is critical, such as finance, policy analysis, and risk assessment. Theoretically, it motivates research into agent architectures that combine planning, search, and uncertainty modeling at scale.
Future work should extend FutureX to additional domains, incorporate more sophisticated adversarial and robustness tests, and explore longitudinal evaluation of agent improvement. As LLM agents approach human-level performance on complex, dynamic tasks, benchmarks like FutureX will be essential for tracking and guiding progress.
Conclusion
FutureX is a comprehensive, live benchmark for future prediction, uniquely positioned to evaluate LLM agents' real-world reasoning and forecasting abilities. Its design addresses longstanding methodological challenges in agent evaluation and provides a scalable platform for both research and deployment-oriented assessment. The results highlight both the promise and current limitations of LLM agents, setting a clear agenda for future advances in agentic AI.