- The paper introduces a novel approach converting domain corpora into reading comprehension texts to improve domain knowledge acquisition in LLMs.
- It combines domain-specific tasks with general instruction data, preserving zero-shot capabilities and robust question-answering performance.
- Experiments in biomedicine, finance, and law demonstrate significant performance gains over traditional fine-tuning methods.
Adapting LLMs to Domains via Reading Comprehension
Introduction
The study presents an innovative approach to address the limitations of fine-tuning LLMs on domain-specific tasks, which traditionally involve substantial computational demands or introduce challenges in effectively assimilating domain knowledge. This work investigates the dual aspects of endowing models with domain-specific knowledge and preserving their ability to perform question-answering tasks effectively. The authors propose a novel methodology that converts domain-specific corpora into enriched reading comprehension texts, facilitating both domain knowledge acquisition and robust prompting capability.
Methodology
The method developed centers on transforming raw domain-specific corpora into reading comprehension texts. This involves annotating each text with tasks relevant to its content, such as summarization, entailment, and commonsense reasoning. The tasks are designed to mimic how reading comprehension can enhance human learning, allowing the model to maintain and improve its ability to generate natural language outputs based on the learned content.
Additionally, to counteract the degeneration of prompting ability often observed with domain-adaptive pre-training, the approach incorporates general instruction data alongside domain-specific tasks. This mix is optimized for each domain, ensuring that the models can effectively generalize across different input-output patterns encountered during training.
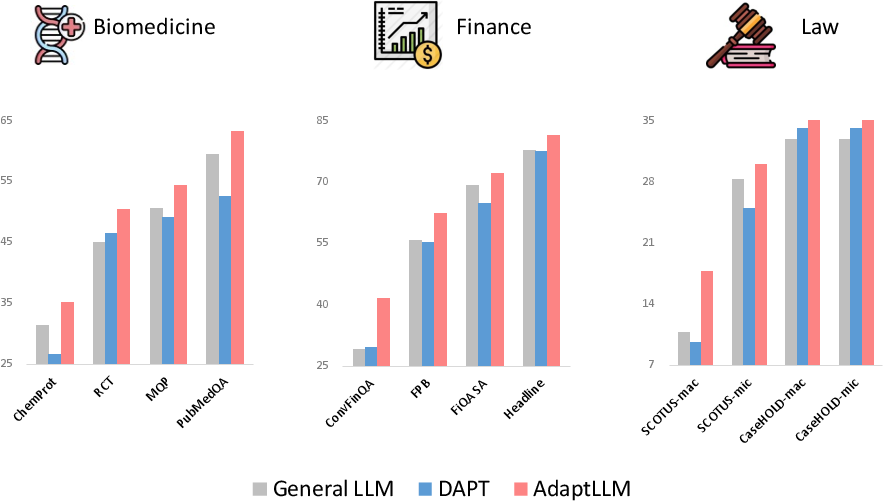
Figure 1: Domain-specific task performance in biomedicine, finance, and law.
The architecture is based on large models such as LLaMA, with further pre-training executed under specified hyper-parameters tailored for each domain. This fine-tuning aims to retain and enhance the model's zero-shot capabilities across both domain-specific and general tasks.
Domain-Specific Applications
The study explores the performance enhancements across three domains: biomedicine, finance, and law. In biomedicine, the model's capability is evaluated on datasets like PubMedQA and USMLE, where the reading comprehension approach resulted in significant improvements over models merely fine-tuned on domain-specific datasets. In finance, AdaptLLM exhibited competitive performance compared to BloombergGPT, a model trained from scratch on financial data, demonstrating computational and data efficiency. For law, AdaptLLM surpassed models like LexGPT, highlighting the efficacy of reading comprehension tasks in legal text interpretation.
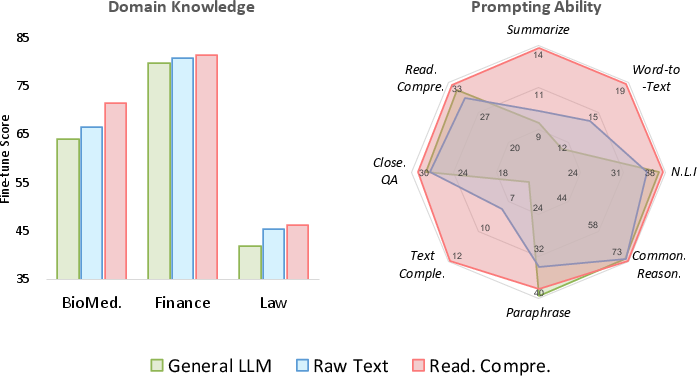
Figure 2: Fine-tuning evaluation on domain-specific tasks (left) and prompting evaluation on general tasks (right).
Ablations and Analysis
Several ablations were conducted to unravel the contributions of different task types within the reading comprehension texts. It was observed that tasks like Word-to-Text and Natural Language Inference had the most substantial impact on domain-specific performance improvements. Furthermore, a detailed examination indicated that despite the conversion into reading comprehension formats, the model's general task performance, evaluated on a variety of datasets, saw consistent improvements.
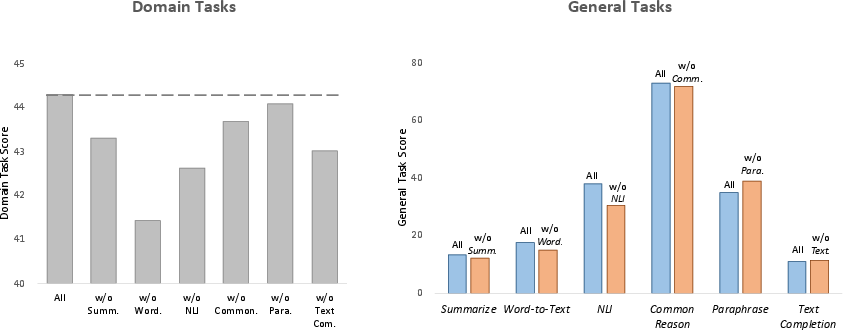
Figure 3: Prompting scores of domain-specific tasks (left) and general LLM benchmarks (right) of models trained with different comprehension tasks.
Implications and Future Work
This approach effectively illustrates a pathway to enhance LLMs with domain-specific knowledge while retaining their generalizability. By imbuing models with an enriched understanding of domain-specific texts through structured reading comprehension exercises, it opens up avenues for more cost-effective and scalable domain adaptation strategies. Future work may explore extending this methodology to other domains and further refining the comprehension task creation process to optimize learning efficiency.
Conclusion
The paper synthesizes a robust methodology that combines reading comprehension with domain-adaptive pre-training, offering a scalable solution to domain-specific LLM adaptation. It underscores the potential to enhance performance across specialized and general tasks without the prohibitive cost of training from scratch, thus contributing significantly to the field of LLM adaptation and application.

