- The paper introduces MM-DiT as a transformer-based diffusion model that replaces U-Net architectures to enhance prompt-based image editing using a unified attention mechanism.
- The methodology leverages bidirectional text-image interactions via a single attention operation, enabling precise local edits and effective noise mitigation through optimal block selection and Gaussian smoothing.
- Evaluation results demonstrate that the proposed method outperforms baselines by balancing source content preservation with accurate prompt alignment in both synthetic and real images.
Introduction
This paper examines the recent shift from traditional U-Net architectures to transformer-based diffusion models, specifically focusing on the Multimodal Diffusion Transformer (MM-DiT). The introduction of MM-DiT in models like Stable Diffusion 3 and Flux.1 marks a significant evolution in image editing capabilities, emphasizing bidirectional information flow through a unified attention mechanism. This research provides a systematic analysis of MM-DiT's attention mechanisms and proposes a robust prompt-based image editing method adaptable to diverse editing scenarios across various MM-DiT variants.
Architecture and Attention Mechanism
MM-DiT introduces a distinctive architecture compared to traditional U-Net models by employing a unified attention mechanism that accommodates input from both text and image modalities. Unlike the separate self-/cross-attention layers in U-Net, MM-DiT performs a single attention operation via concatenated input projections, facilitating bidirectional text-image interactions (Figure 1).
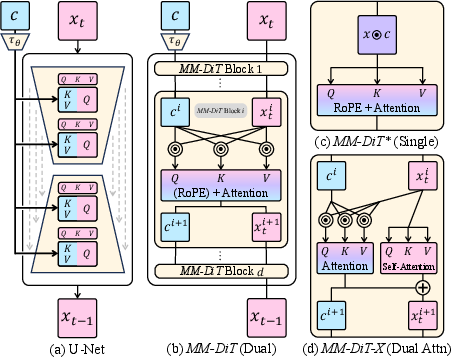
Figure 1: Attention mechanisms in diffusion architectures, showcasing MM-DiT’s integration of text and image branches for enhanced bidirectional attention.
The attention map is decomposed into four blocks: Image-to-Image (I2I), Text-to-Image (T2I), Image-to-Text (I2T), and Text-to-Text (T2T). I2I and T2T are responsible for unimodal processes, with I2I capturing spatial layouts similar to U-Net's self-attention, while T2T appears as identity matrices focusing on semantic token boundaries. Conversely, T2I and I2T blocks facilitate cross-modal interactions, crucial for precise editing, with T2I blocks particularly effective for visual masking and localization tasks.
Block-Wise Patterns and Noise Mitigation
An important insight from the analysis is the emergence of noise in attention maps proportional to model scale, necessitating strategies for clearer attention extraction. The paper advocates for selecting optimal transformer blocks that yield more precise attention maps, combined with Gaussian smoothing to enhance blending outcomes (Figure 2).
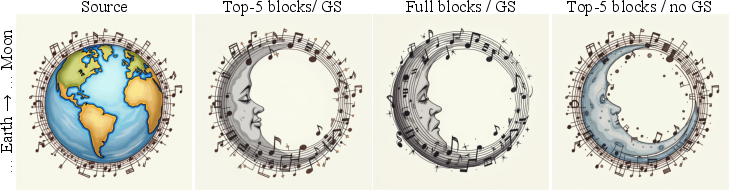
Figure 2: Local image editing using masks from selected transformer blocks, demonstrating noise reduction and boundary artifact minimization.
The research identifies specific blocks within the MM-DiT architecture that produce attention maps with high fidelity, advocating their use for local blending. This method leverages non-disruptive blocks and smoothing techniques to maintain image quality during intricate editing processes.
Editing Methodology
The paper proposes an editing method based on the MM-DiT architecture that replaces selected input projections while preserving the text region intact, thus avoiding issues of token misalignment (Figures 13 and 14). This approach uniquely maintains base image integrity while incorporating prompt-driven edits, demonstrating efficacy even with disparate prompt pairs.

Figure 3: Our real image editing method showcasing precise local edit capabilities compared to RF inversion.

Figure 4: Our method's performance relative to baselines in various editing scenarios, indicating superior preservation and desired edit balance.
Crucially, this editing technique supports both synthetic and real image modifications, reflecting robust functionalities across different input types.
Evaluation and Implications
The proposed editing method outperforms baseline approaches by effectively balancing source content preservation with target prompt alignment. Through user studies and quantitative metrics, the method demonstrates superior edit precision and content retention across multiple models and scenarios (Figure 5).
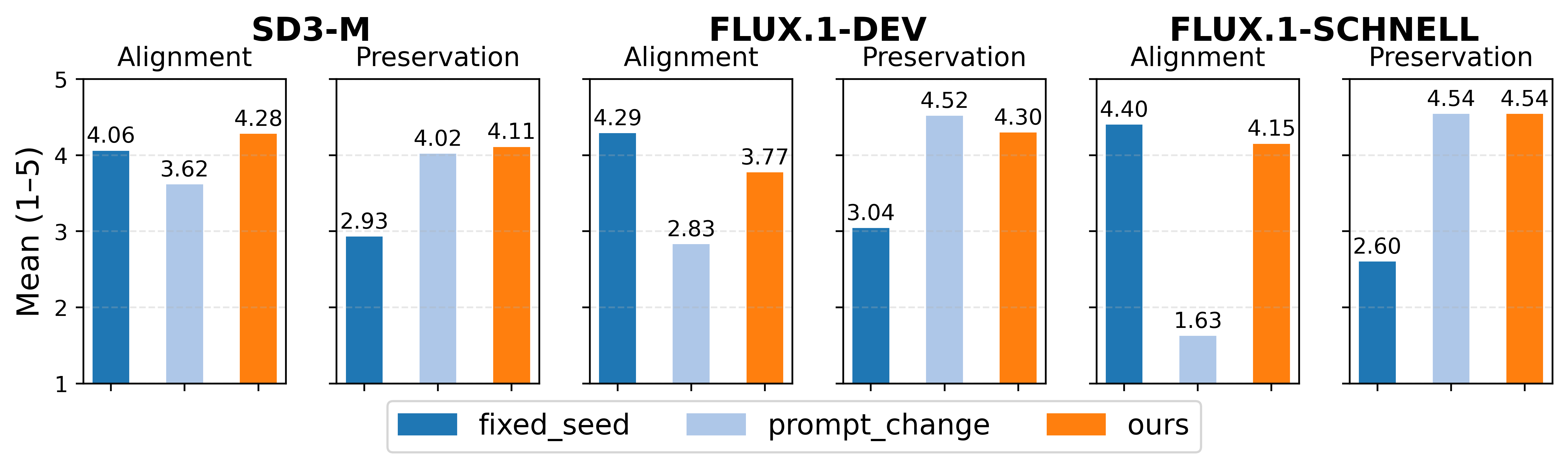
Figure 5: User study results highlight superior performance in edit quality and source integrity compared to baseline methods.
This research contributes to the understanding of MM-DiT's capabilities, suggesting future applications in complex editing tasks, real-time image modifications, and potential for integration in creative and computational design spaces.
Conclusion
The systematic analysis and application of MM-DiT's attention mechanisms provide a foundation for advanced prompt-based editing techniques. By combining architectural insights with practical editing strategies, the research bridges existing methods and emerging technologies, setting a framework for future developments in transformer-based image generation and manipulation. Future work could explore the integration of more sophisticated inversion techniques and automated attention map improvements to further enhance image editing precision and efficiency.

