Group Relative Attention Guidance for Image Editing
Abstract: Recently, image editing based on Diffusion-in-Transformer models has undergone rapid development. However, existing editing methods often lack effective control over the degree of editing, limiting their ability to achieve more customized results. To address this limitation, we investigate the MM-Attention mechanism within the DiT model and observe that the Query and Key tokens share a bias vector that is only layer-dependent. We interpret this bias as representing the model's inherent editing behavior, while the delta between each token and its corresponding bias encodes the content-specific editing signals. Based on this insight, we propose Group Relative Attention Guidance, a simple yet effective method that reweights the delta values of different tokens to modulate the focus of the model on the input image relative to the editing instruction, enabling continuous and fine-grained control over editing intensity without any tuning. Extensive experiments conducted on existing image editing frameworks demonstrate that GRAG can be integrated with as few as four lines of code, consistently enhancing editing quality. Moreover, compared to the commonly used Classifier-Free Guidance, GRAG achieves smoother and more precise control over the degree of editing. Our code will be released at https://github.com/little-misfit/GRAG-Image-Editing.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple way to better control how much an image gets changed when you edit it using modern AI image models. The method is called Group Relative Attention Guidance (GRAG). It helps you smoothly “dial” the strength of an edit so the result matches your instruction without ruining the original picture.
What questions does the paper try to answer?
- How can we balance two goals in image editing: follow the user’s instruction and keep the original image looking consistent?
- Can we give users a smooth, precise control over how strong the edit is—like turning a volume knob up or down—without retraining the model?
How did the researchers approach the problem?
Think of an AI image editor as a team that reads instructions (text) and looks at the picture (image), then decides which parts to change. Inside this team, there’s a mechanism called “attention,” which is like a spotlight that decides what to focus on at each step.
- Tokens: The picture and the text are split into small chunks called “tokens.” You can imagine tokens like tiny puzzle pieces of the image or words in the sentence.
- Query (Q) and Key (K): These are numbers the model uses to decide which tokens should pay attention to which other tokens. You can think of Query as “who’s looking” and Key as “who’s being looked at.”
- Bias vector: The researchers found that many of these Q and K numbers crowd around a shared “default direction” in each layer of the model. Imagine a magnet in the middle pulling most arrows toward it. This default direction acts like the model’s built-in editing behavior.
- Delta (difference): Each token also has its own small “twist” away from that default. This twist carries the specific meaning of your edit (for example, “make the apple red” instead of “change the background”).
The key idea of GRAG:
- Compute the average “Key” for a group of tokens (for example, tokens from the original image). That average is the group’s bias—the shared default direction.
- For each token, measure how much it differs from the bias (its delta).
- Reweight these differences with two simple knobs:
- λ (lambda) controls how much the shared default contributes.
- δ (delta) controls how strongly the token-specific differences matter.
- By turning δ up or down, you get smooth, fine control over how much the image changes according to your instruction.
You can add GRAG into existing models with just a few lines of code. It works inside the attention calculations, not in the final denoising step, so it directly controls how the model blends the instruction with the image details.
What did they find, and why does it matter?
Here are the main findings explained simply:
- There is a strong shared “default” direction in attention (the bias vector). It reflects the model’s built-in editing behavior.
- The meaningful part of your edit lives in the differences from that default (the deltas).
- If you scale these differences (especially δ), you can smoothly control editing strength—more or less change—without retraining the model.
- GRAG gives finer, more stable control than the common method called Classifier-Free Guidance (CFG), which adjusts the model later in the process and tends to be less precise.
- In tests across multiple editing models and tasks, GRAG improved the balance between “follow the instruction” and “keep the image consistent.” It often improved scores that measure image similarity and human preference.
Why it matters:
- Users get a reliable “edit strength knob” for precise control.
- You can keep important details (like textures and shapes) while making the intended changes (like color or style).
- It reduces the need to guess prompts or repeatedly run the model to get the desired effect.
What could this change in the future?
- Better editing tools: Apps could let you slide a control to adjust how “strong” the change is, from subtle tweaks to bold transformations.
- Easier workflows: Less trial-and-error and fewer repeated runs to get the perfect edit.
- Model design: Understanding the attention bias could inspire new model architectures that are naturally more controllable.
- Limitations: GRAG works best in models trained for editing. In “training-free” setups, it still helps but can be less stable because those models blend image features differently. Future work could refine GRAG for those cases.
In short, GRAG is a simple, practical way to make AI image editing more predictable and user-friendly, letting you finely tune how much an image changes to match your instruction.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future work.
- Theoretical grounding: no formal proof that the observed layer-dependent bias in Q/K embeddings causally corresponds to an “editing action”; the current evidence is empirical and correlational.
- Generality of the bias phenomenon: lack of systematic verification across diverse DiT families, training recipes, tokenizers, text encoders (CLIP vs T5 vs VLMs), and datasets to confirm how universal the shared Q/K bias is.
- Layer- and head-specific behavior: no analysis of whether bias magnitude/direction and the effectiveness of GRAG differ by attention head and layer; no per-head/per-layer scaling or selection strategy is explored.
- RoPE frequency structure: the modality separation across RoPE frequency bands is observed but not exploited; no investigation into frequency-aware or band-selective GRAG that targets relevant dimensions.
- Choice of group statistic: GRAG uses a simple mean as the group bias; no evaluation of robust alternatives (e.g., median, trimmed mean, per-head PCA/component, Mahalanobis-normalized mean) or per-token normalization to handle outliers.
- Token grouping policy: unclear best practices for how to choose the token span (i_start, i_end) for different models/tasks; no automatic or data-driven grouping (e.g., attention-based, mask-based, or semantic clustering) is proposed.
- Where to apply GRAG: not specified which layers benefit most; no study of layer selection, layerwise schedules, or progressive application across timesteps.
- Scheduling over denoising time: no analysis of timestep-dependent schedules for λ/δ; whether early/late denoising phases require different strengths remains untested.
- Parameter selection: λ and δ are tuned heuristically; no principled procedure, calibration curve, or automatic predictor (from prompt/image features) for selecting scales.
- Monotonicity and controllability metrics: “continuous control” is claimed, but no formal metric of monotonicity, smoothness, or perceptual step response is introduced; qualitative plots lack statistical tests.
- Interaction with CFG and other guidance: only compared to CFG; no comparison to contemporary attention guidance (e.g., NAG), negative-prompt strategies, or guidance-temperature/attention-scaling baselines.
- Training-free instability: observed instability in training-free pipelines is attributed to self-attention pathways, but no concrete method is provided to apply GRAG to self-attention or to decouple conflicting paths.
- Cross-attention vs self-attention: GRAG modulates cross-attention only; the role and modification of self-attention (especially in training-free T2I edits) is not explored.
- Localized/region editing: GRAG is global over selected groups; no mechanism for spatially localized control (e.g., masks, region tokens, or ROI-aware grouping) is proposed or evaluated.
- Complex edit types: limited discussion of geometric edits, pose changes, multi-object edits, large-scale scene edits, or edits requiring strong spatial transformations; robustness across these remains unknown.
- Identity preservation and safety: no targeted evaluation for human faces/identity, watermark retention, safety filters, or bias/hallucination impacts when scaling editing strength.
- Dataset coverage and user studies: evaluation focuses on PIE and EditScore; no human preference study, cross-dataset validation, or domain-diverse benchmarks (e.g., medical, artwork, UI) are included.
- Metric limitations: reliance on LPIPS/SSIM in “non-edited regions” and a single reward model (EditScore) may bias conclusions; no robustness checks across multiple reward models or segment-accuracy measures.
- Variance and reproducibility: results are reported with a fixed seed (42) without variance estimates; no sensitivity analysis over seeds, prompts, or image distributions.
- High-resolution and small-object performance: no analysis of scalability to higher resolutions or small target regions where attention dilution is severe.
- Computational overhead: although described as “four lines,” actual runtime/memory overhead and latency in interactive settings are not reported.
- Combination with training: it is unknown whether using GRAG during fine-tuning could yield models with built-in controllable knobs or improved editability; no joint training experiments.
- Applicability beyond MM-DiT: claims of generality to MM-DiT are tested; applicability to UNet-based or hybrid architectures with separate cross/self-attention is not empirically validated.
- Multi-turn and compositional editing: no study of sequential edits (edit-after-edit) or composing multiple edit instructions with independent control sliders.
- Failure modes at high scales: artifacts appear at large λ/δ in some cases; no characterization of the safe operating region or adaptive clipping/regularization strategies to prevent degeneration.
- Bias estimation consistency: the paper posits a layer-dependent, sample-agnostic bias but operationally computes a sample-dependent group mean; the relationship between these two “biases” is not reconciled.
- Attention normalization effects: the effect of GRAG on attention temperature, softmax concentration, and downstream residual pathways is not analyzed; no diagnostic of how GRAG changes attention entropy.
- Token-count sensitivity: averaging across variable-length token groups (especially text vs image tokens) may change scale; no normalization or re-weighting by token count is studied.
- Prompt length and structure: the impact of long/complex prompts, negative prompts, or multi-sentence instructions on GRAG’s stability and controllability is not examined.
- Open-source and benchmarking: code is promised but not benchmarked against standardized leaderboards with defined protocols for edit strength control, hindering fair comparisons and adoption.
Glossary
- Adaptive Layer Normalization: A conditioning-aware normalization that modulates transformer layers using external context (e.g., class labels). Example: "introduced adaptive layer normalization to enable class-conditional generation"
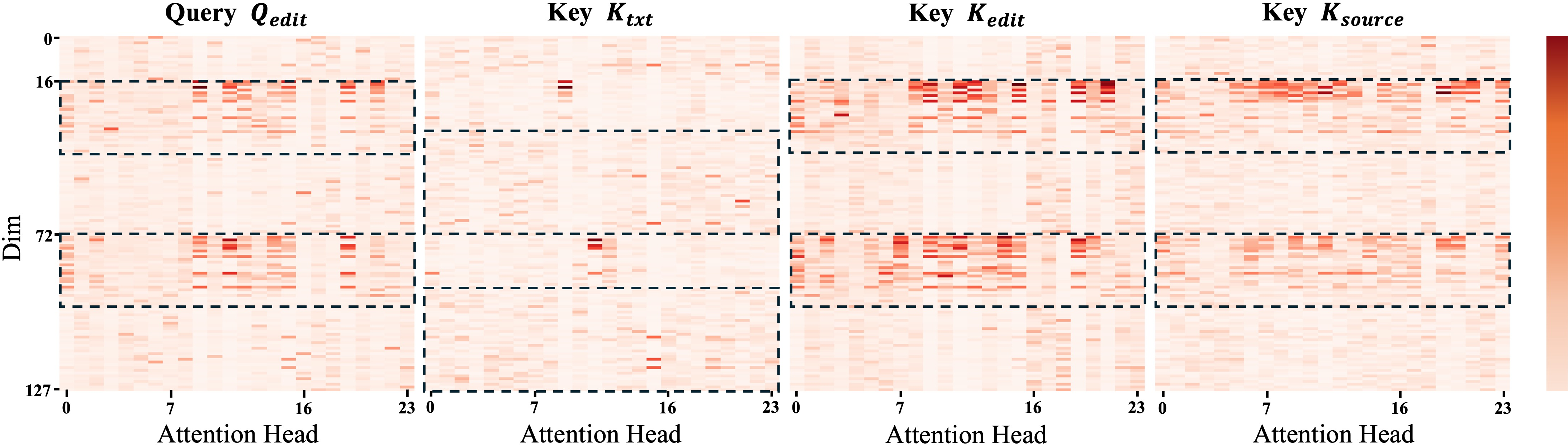
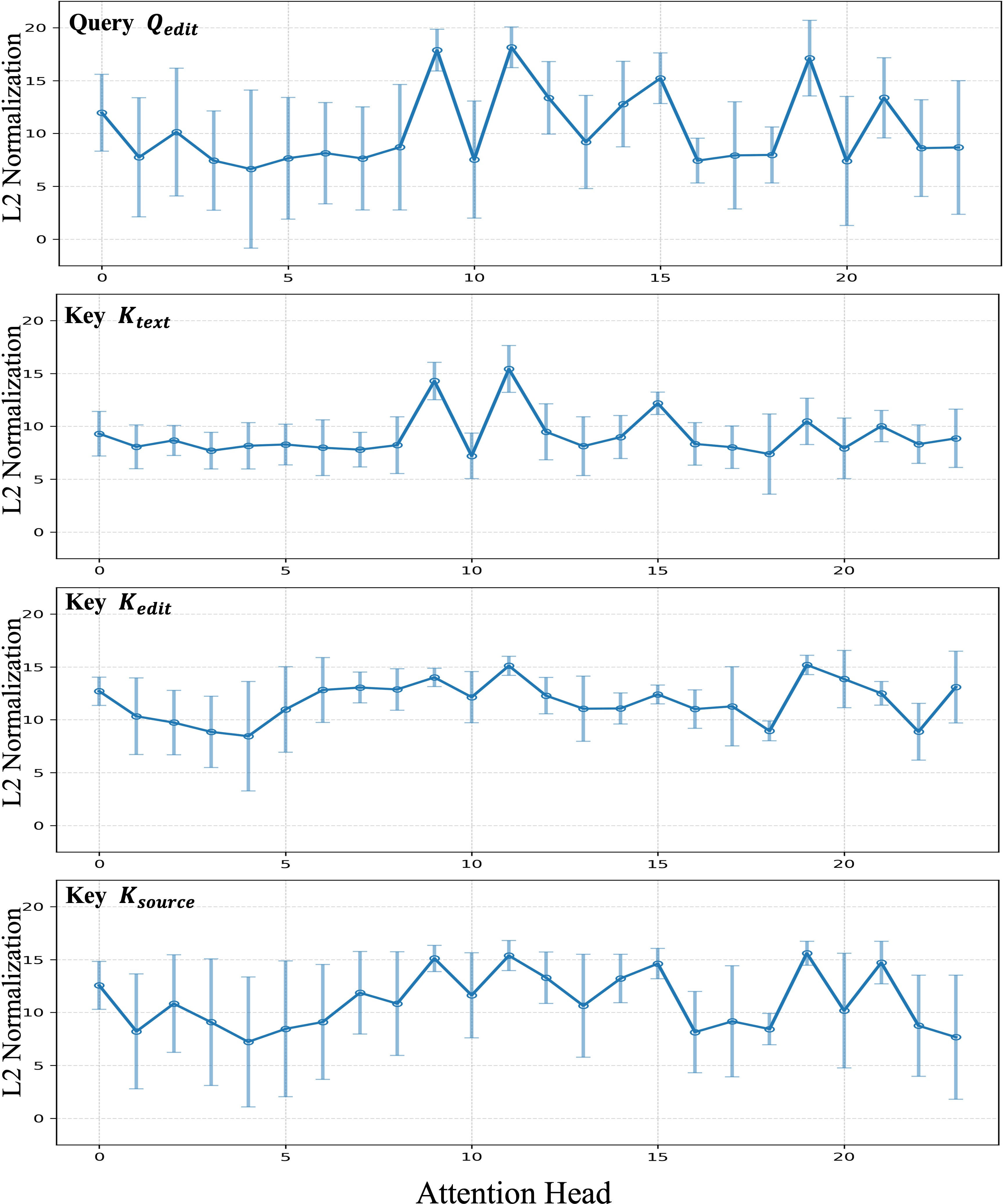
- Attention head: One of several parallel attention subspaces in multi-head attention, each computing its own attention weights. Example: "Mean vector magnitudes and standard deviations across different attention heads."
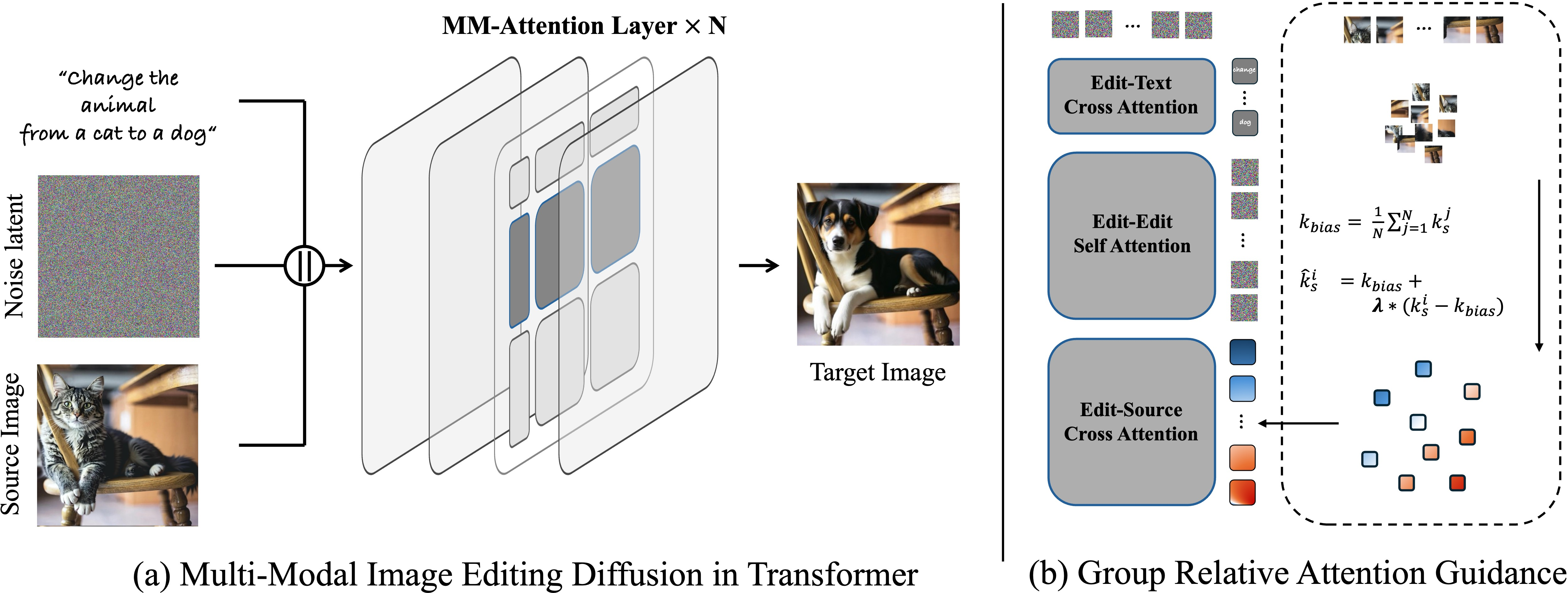
- Attention layer: The component that computes attention over tokens to integrate information. Example: "The attention layer of MM-DiT serves as the key location where editing instructions and conditional image information are fused,"
- Attention map: The matrix of attention weights indicating how queries attend to keys. Example: "The MM-Attention map corresponding to the query , where GRAG is applied."
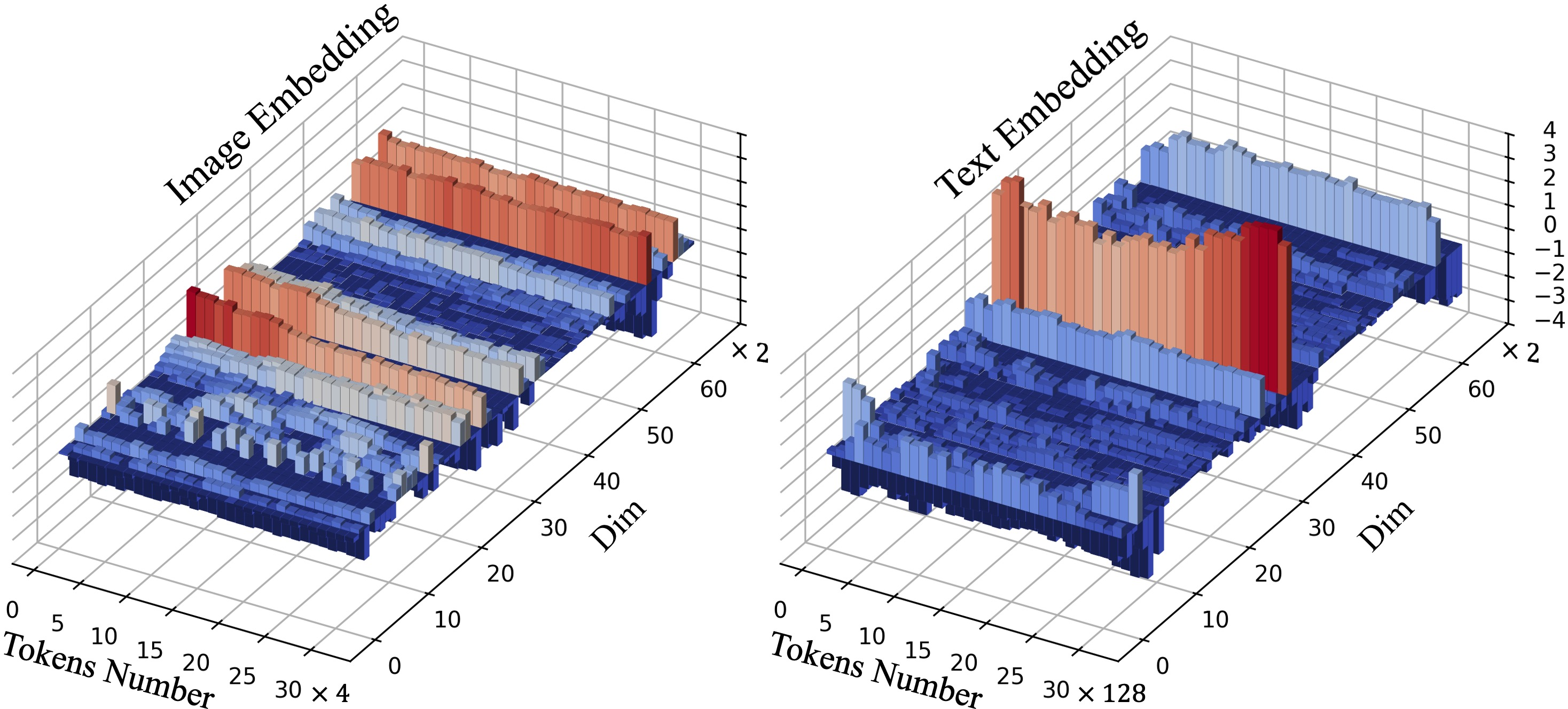
- Bias vector: A dominant shared component in embeddings that shifts token distributions and affects attention behavior. Example: "A significant bias vector exists in the embedding space."
- Classifier-Free Guidance (CFG): A sampling technique for diffusion models that steers generation by combining conditional and unconditional predictions. Example: "Compared to the commonly used Classifier-Free Guidance, GRAG achieves smoother and more precise control over the degree of editing."
- Cross-attention: Attention where queries from one sequence attend to keys/values from another sequence or modality. Example: "Unlike UNet-based models that separate cross-attention and self-attention,"
- Cross-modal attention: Attention mechanisms that connect different modalities, such as text and images. Example: "introducing a unified token space and bidirectional cross-modal attention,"
- Delta (Δ) vector: The deviation of a token embedding from its layer’s bias vector, encoding content-specific signals. Example: "a weighting coefficient is used to modulate each tokenâs vector relative to the bias,"
- Denoising: The iterative process in diffusion models that removes noise to produce images. Example: "ultimately generating high-quality visual outputs through iterative denoising."
- Diffusion-in-Transformer (DiT): A diffusion model architecture that uses transformers instead of U-Nets to generate or edit images. Example: "image editing based on Diffusion-in-Transformer (DiT) models has undergone rapid development."
- EditScore: A learned reward metric assessing editing quality, prompt adherence, and consistency. Example: "we employ the image editing reward model EditScore"
- Group Relative Attention Guidance (GRAG): The proposed method that rescales token deviations from a group bias to control editing strength continuously. Example: "we propose Group Relative Attention Guidance (GRAG)"
- Group Relative Policy Optimization (GRPO): A reinforcement learning method using group-relative baselines, inspiring GRAG’s design. Example: "inspired by the Group Relative Policy Optimization~(GRPO)~\cite{shao2024deepseekmath} strategy."
- Guidance scale: A scalar controlling the strength of a guidance mechanism during generation or editing. Example: "With a fixed guidance scale, our approach achieves a better trade-off between the editing responsiveness and image consistency,"
- Key (K): Transformer vectors representing content locations; attention weights are computed via query–key similarity. Example: "Query (Q) and Key (K) tokens share a bias vector"
- L2 normalization: Scaling vectors to unit length using the Euclidean norm. Example: "We apply normalization along the $N_{\mathrm{text}$ or $N_{\mathrm{img}$ dimension"
- Latent: A hidden representation used internally by generative models, often noisy during diffusion. Example: "inject semantic information from text into noisy latents,"
- LPIPS: A perceptual image similarity metric correlating with human judgments. Example: "we adopt LPIPS and SSIM as quantitative metrics"
- LoRA: A parameter-efficient fine-tuning technique using low-rank adapters. Example: "LoRA-based methods introduced task-specific parameter tuning for diffusion transformers."
- MM-Attention: The unified multi-modal attention mechanism in DiT that fuses text and image tokens. Example: "multi-modal attention mechanism (MM-Attention)"
- MM-DiT: A multi-modal diffusion transformer that integrates text and image tokens in a shared sequence. Example: "known as multi-modal diffusion transformers (MM-DiT)"
- ODE inversion: Recovering initial conditions by integrating an ordinary differential equation, used here for diffusion inversion. Example: "a second-order ODE inversion method"
- Prompt Following (PF): A metric estimating how well the edited output follows the input instruction. Example: "prompt following (PF)"
- Query (Q): Transformer vectors that request relevant information by attending to keys. Example: "Query (Q) and Key (K) tokens share a bias vector"
- RoPE (Rotary Position Embedding): A positional encoding that applies rotations in query/key space to encode positions. Example: "Rotary Position Embedding"
- Self-attention: Attention where tokens attend to other tokens within the same sequence. Example: "separate cross-attention and self-attention,"
- SSIM: A structural similarity index measuring perceptual image quality. Example: "we adopt LPIPS and SSIM as quantitative metrics"
- Token-wise concatenation: Combining token sequences by concatenating embeddings along the sequence axis. Example: "where denotes the token-wise concatenation of the text and image tokens."
- U-Net: An encoder–decoder CNN with skip connections, commonly used in diffusion models. Example: "U-Net backbones"
- Unified token space: A shared embedding space for text and image tokens to interact directly. Example: "introducing a unified token space and bidirectional cross-modal attention,"
- Vision–LLM (VLM): A model that jointly processes and reasons over visual and textual inputs. Example: "replaces the T5 encoder with a large vision LLM"
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings and GRAG method, which integrates into MM-DiT-based editors with minimal code changes and provides smooth, fine-grained control of editing strength.
- Sector: Creative software and media production
- Use case: “Edit strength” slider for image editors
- Workflow/Product: Add a UI control (slider or numeric parameter) mapped to GRAG’s δ (and optionally λ) in existing tools (e.g., ComfyUI node, Automatic1111 extension for DiT models, Photoshop/Krita/GIMP plugin via UXP/py scripts, Hugging Face inference endpoints)
- Assumptions/Dependencies: Requires MM-DiT architectures (e.g., FLUX/Kontext, Qwen-Edit, Step1X-Edit); token group indices must be exposed; licensing for proprietary models; tested δ-only adjustment offers best continuity and stability
- Sector: Advertising, marketing, and content production
- Use case: A/B testing creative intensity (brand-safe edits)
- Workflow/Product: Batch pipelines that sweep δ values to produce variants (e.g., subtle → strong color changes), score with EditScore or internal preference models, pick the best for campaign deployment
- Assumptions/Dependencies: Access to DiT-based editors; preference/reward models; brand compliance rules; computational resources for batch inference
- Sector: E-commerce imaging
- Use case: High-volume product edits with preservation of shape/identity (e.g., colorway changes, background cleanup, shadow consistency)
- Workflow/Product: A “consistency-first” batch-edit pipeline using GRAG with source token grouping to maintain object fidelity while following edit prompts
- Assumptions/Dependencies: Stable behavior shown to be stronger in training-based editors; masking or region selection may further improve results; model licenses and governance for large-scale use
- Sector: Social media and prosumer apps
- Use case: User-facing filters with adjustable transformation strength (style transfer, mild retouch, background tweaks)
- Workflow/Product: Mobile app integration of GRAG to replace prompt engineering with a single intensity slider; preset filters with tunable δ profiles
- Assumptions/Dependencies: Edge deployment constraints; mobile inference optimization; DiT-based mobile models or server-side APIs
- Sector: Design and digital art
- Use case: Prompt-responsive edits that preserve original composition (texture swaps, color adjustments) without re-running multiple inferences
- Workflow/Product: Creative suites with GRAG-enabled “precision edit” modes; preset workflows that bias source tokens and adjust δ for fine control
- Assumptions/Dependencies: Access to MM-DiT editors; UI/UX integration; artists’ prompt libraries
- Sector: Academic research and teaching
- Use case: Attention interpretability and guidance benchmarking
- Workflow/Product: Reproducible experiments replacing CFG with GRAG; inspecting Q/K bias vectors across layers and time steps; teaching modules demonstrating token bias and relative guidance
- Assumptions/Dependencies: Research models (Kontext, Qwen-Edit, Step1X-Edit); plotting tools for attention and embedding visualizations; datasets like PIE for evaluation
- Sector: Synthetic data generation for vision
- Use case: Controlled domain-shift augmentation (lighting/color/style changes) to improve model robustness
- Workflow/Product: Data pipelines that sweep δ to produce incremental edits, preserving geometry while varying appearance
- Assumptions/Dependencies: MM-DiT editors; curation with SSIM/LPIPS; task-specific validation
- Sector: Platform safety and compliance
- Use case: Edit governance with provenance
- Workflow/Product: Integrate GRAG with C2PA/metadata tooling; enforce default δ thresholds for platform-posted content; audit logs of edit intensity
- Assumptions/Dependencies: Content provenance stack; policy definitions of “degree of edit”; potential need for watermarks and disclosures
Long-Term Applications
These applications require further research, scaling, or development to mature (e.g., stability in training-free settings, multi-modal extensions, video consistency, policy frameworks).
- Sector: Video post-production and VFX
- Use case: Temporally consistent, controllable video editing
- Workflow/Product: Extend GRAG to video DiTs with temporal attention; “keyframe edit curves” controlling δ over time; plugins for After Effects/DaVinci Resolve
- Assumptions/Dependencies: Temporal models; new grouping strategies across frames; robustness against flicker; efficient inference
- Sector: Healthcare imaging and privacy
- Use case: Clinically safe synthetic augmentation and controlled de-identification
- Workflow/Product: GRAG-driven edits that preserve anatomy/fidelity while varying nuisance factors (contrast, noise, anonymization intensity)
- Assumptions/Dependencies: Rigorous validation with clinicians; regulatory approval; medically specialized DiT editors; risk management to avoid misleading artifacts
- Sector: Robotics and autonomous systems
- Use case: Simulation-to-real domain adaptation via controlled visual edits
- Workflow/Product: Controlled environment perturbations (weather/time-of-day/texture changes) in simulation datasets to bridge domain gaps
- Assumptions/Dependencies: DiT-based editing for scene data; performance evaluation on downstream tasks; integration with simulators; safety testing
- Sector: Education technology
- Use case: Adaptive visual content generation for lessons
- Workflow/Product: Teaching materials where visual edits gradually increase in intensity to scaffold learning (e.g., progressive style changes to illustrate concepts)
- Assumptions/Dependencies: Curriculum integration; age-appropriate moderation; reliable DiT editors available in classrooms
- Sector: Software engineering for generative systems
- Use case: Generalized “relative guidance” abstractions beyond images
- Workflow/Product: Research into token-group relative guidance for audio, 3D, and text modalities (LLMs), exploring bias-Δ decomposition for controllable editing
- Assumptions/Dependencies: Evidence of shared bias structures in other modalities; architecture hooks for token grouping; new evaluation metrics
- Sector: Policy and standards
- Use case: Degree-of-edit reporting and thresholds in normative frameworks
- Workflow/Product: Standards bodies define edit intensity measures, disclosure requirements, and provenance expectations; platform rules tied to δ/λ ranges
- Assumptions/Dependencies: Consensus on measurement; adoption of C2PA-like standards; enforcement mechanisms
- Sector: Model training and architecture design
- Use case: Training objectives and layers that expose/structure bias vectors for better controllability
- Workflow/Product: New DiT training pipelines that regularize Q/K bias components and optimize GRAG responsiveness; improved token-group definitions (e.g., dynamic grouping via attention clustering)
- Assumptions/Dependencies: Access to training data; compute; empirical studies on generalization; open-source implementations
- Sector: Forensics and trust
- Use case: Detectability and quantification of edits
- Workflow/Product: Forensic tools that estimate edit intensity and map likely attention-guidance footprints; support for newsroom verification workflows
- Assumptions/Dependencies: Ground-truth datasets; cooperation with platforms; calibrated detectors; risk of adversarial bypass
- Sector: Training-free editing reliability
- Use case: Stabilized GRAG for general T2I models without fine-tuning
- Workflow/Product: Methods that better align self-attention and cross-attention interplay so GRAG does not destabilize source representations; robust default parameterization for δ/λ
- Assumptions/Dependencies: Architectural adjustments; hybrid guidance strategies; evaluation on diverse tasks
Cross-cutting assumptions and dependencies
- GRAG is most stable on training-based MM-DiT editors (Kontext, Qwen-Edit, Step1X-Edit); training-free T2I models may need additional stabilization.
- Effective integration requires access to attention-layer embeddings and clear token group indices (e.g., text, source image, edit tokens).
- δ-only tuning provides the most continuous control; joint δ and λ tuning can introduce artifacts.
- Performance and fidelity vary with task type; selective region editing (masks) and prompt clarity remain helpful.
- Licensing and governance for proprietary models are needed; responsible-use guardrails (provenance, watermarks, disclosures) should accompany deployments in public-facing contexts.
Collections
Sign up for free to add this paper to one or more collections.