- The paper introduces a novel multimodal dataset that emulates real-world moderation scenarios and benchmarks multiple MLLMs against human reviewers.
- It reports Gemini-2.0-Flash achieving an F1-score of 0.91 and highlights the cost efficiency of lightweight models like Gemini-2.0-Flash-Lite.
- The study identifies limitations in processing contextual nuances in non-English content, suggesting hybrid human-AI moderation strategies.
AI vs. Human Moderators: A Comparative Evaluation of Multimodal LLMs in Content Moderation for Brand Safety
Introduction
The rapid proliferation of video content on social media platforms has precipitated an urgent demand for scalable and efficient moderation solutions. Traditional human moderation poses significant operational challenges due to the vast volumes of content and has been associated with detrimental effects on moderators' mental health. This paper provides a detailed evaluation of Multimodal LLMs (MLLMs) in automating content moderation tasks, specifically within the domain of brand safety. This entails aligning advertisement placements with advertiser standards, avoiding association with risky content categories such as violence or controversial political discourse.
Novel Dataset and Methodology
A cornerstone of this research is the introduction of a novel, meticulously labeled multimodal dataset, encompassing visual and textual cues across various risk categories and languages, curated to emulate a real-world content moderation setting. Through a comparative analysis, MLLMs like Gemini, GPT, and Llama are benchmarked against professional human reviewers, evaluating both performance metrics and cost efficiency.
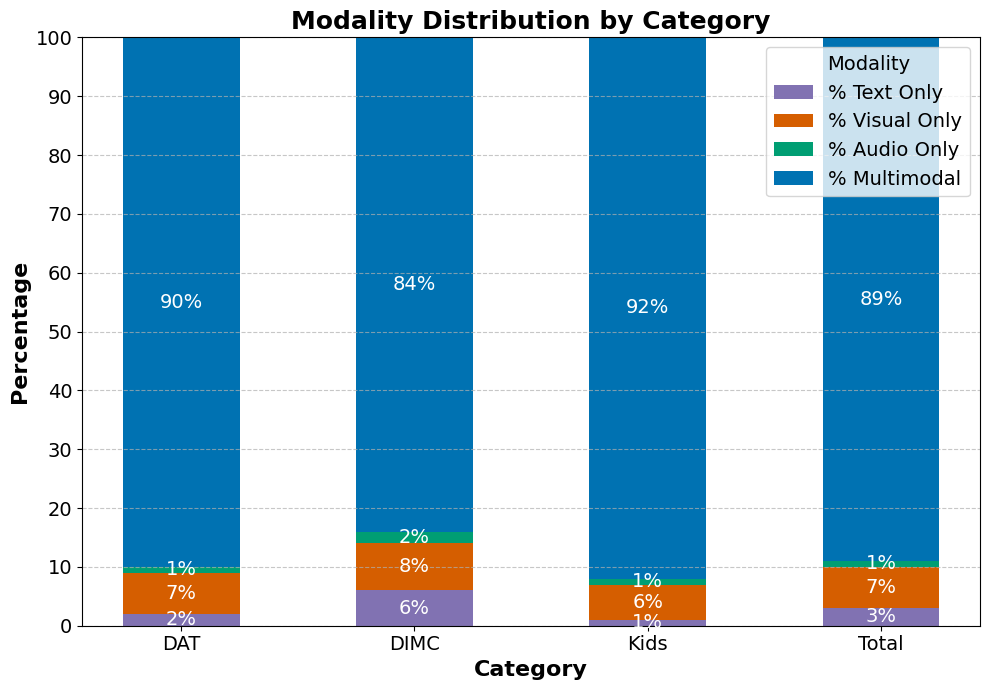
Figure 1: Percentage Distribution of the Risk Signals Present in Videos by Modality for each Category.
In particular, the dataset editing elucidates the multimodal nature of content moderation, with a significant percentage of risky content manifesting across multiple modalities. This exemplifies the necessity of employing multimodal inputs in MLLMs to effectively mirror the nuanced decision-making processes of human reviewers.
Evaluation Results
The performance of MLLMs was assessed across key metrics such as precision, recall, and F1-score. The results underscored Gemini's balanced performance across risk categories, with its latest iteration, Gemini-2.0-Flash, achieving a commendable F1-score of 0.91, indicative of its robust classification capability in diverse settings.
Conversely, GPT models, while performing well in text-centric tasks, exhibited limitations in effectively resolving multimodal content, particularly in categories with high visual dependencies.
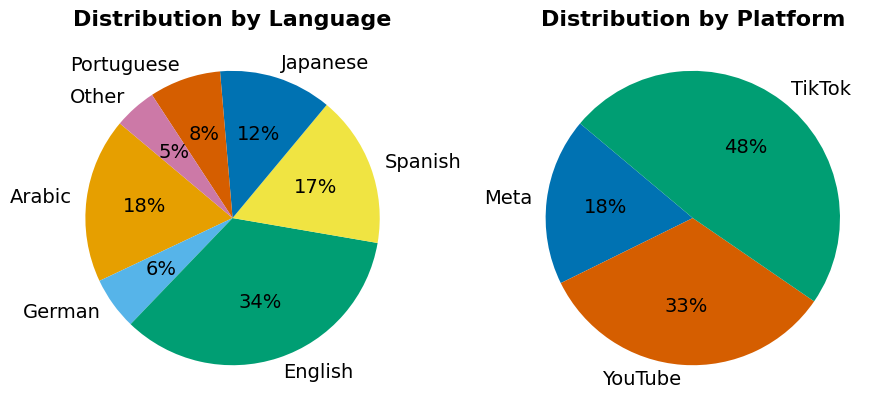
Figure 2: Percentage Distribution by Language and by Platform.
Moreover, the cost efficiency analysis illuminates the viability of MLLMs as a cost-effective adjunct to human moderation. The computational costs of these models were meticulously tabulated, revealing the competitive edge of compact variants like Gemini-2.0-Flash-Lite, which balances performance with reduced operational costs.
Limitations and Practical Implications
Despite promising results, several limitations were identified. Notably, MLLMs exhibited challenges in comprehensively understanding contextual nuances in non-English content, highlighting a prevalent language bias. Additionally, MLLMs sometimes failed to correctly classify content due to incorrect associations or ambiguities in terminology. These limitations point to essential areas for improvement, such as enhancing the versatility of native language processing and refining contextual understanding.
Conclusion
This investigation substantiates the potential of MLLMs to augment content moderation frameworks, providing a scalable and economically viable alternative to sole human moderation. The superior recall rates in certain categories underscore the promise of hybrid approaches where AI can efficiently pre-filter content before final human review ensures precision.
Given these findings, future work will focus on further refining MLLMs through fine-tuning and extending evaluations to encapsulate longer-format content and additional risk categories. The publicly released dataset is anticipated to serve as a fertile ground for continued advancements in responsible brand safety and content moderation research.