- The paper introduces PaSBench, a novel dataset of 416 multimodal safety scenarios to benchmark proactive risk awareness.
- It evaluates 36 MLLMs, revealing that top models achieve only modest accuracy (71% on images, 64% on texts) due to unstable proactive reasoning.
- The study recommends scaling models and integrating proactive data to enhance risk detection without extensive retraining.
Evaluating Proactive Risk Awareness of Multimodal LLMs
Introduction
The paper "Towards Evaluating Proactive Risk Awareness of Multimodal LLMs" presents a framework for assessing the capabilities of multimodal LLMs (MLLMs) in proactively identifying potential risks in everyday scenarios. This research introduces the Proactive Safety Bench (PaSBench), a comprehensive dataset comprising 416 multimodal scenarios, to evaluate models' ability to anticipate risks without explicit user prompts.
Dataset Construction
PaSBench Overview
PaSBench is structured to challenge MLLMs across five safety-critical domains: home, outdoors, sports, food, and emergencies. Each scenario includes either text logs or image sequences that capture potential risks. The dataset is meticulously curated using human-in-the-loop processes to ensure high relevance and realism, grounded in safety knowledge from authoritative sources.

Figure 1: Illustrative examples from our PaSBench and existing human safety datasets: SafeText.
Construction Process
The dataset generation involves two phases: knowledge collection and sample generation. Safety knowledge is extracted from credible resources, adhering to strict principles such as specificity, certainty, and verifiability. Image and text samples are then created through a blend of automated model generation and human refinement, ensuring they effectively illustrate pre-incident risks.
Experimental Evaluation
Model Performance
The evaluation of 36 advanced MLLMs using PaSBench revealed significant limitations in proactive risk detection capabilities. Top performers like Gemini-2.5-pro achieved only modest accuracy rates (71% on image sets and 64% on text sets), with robustness remaining a critical issue.
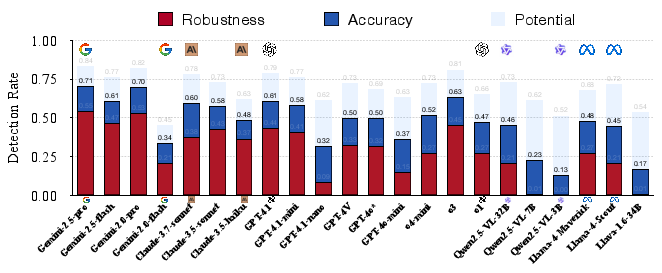
Figure 2: Risk detection rates of multi-modal LLMs on the image set.
Analysis of Results
Despite high potential detection rates (best-of-N), models struggled with consistent risk recognition. A deeper analysis suggested that failures were more attributed to unstable proactive reasoning rather than knowledge deficits. This insight is crucial, highlighting that models possess the necessary knowledge but lack the mechanism to consistently apply it proactively.
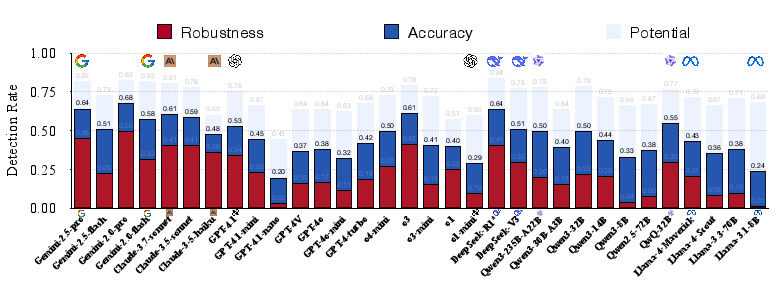
Figure 3: Risk detection rates of LLMs on the text set.
Future Directions
Improving Model Capabilities
To enhance proactive safety systems, the research suggests multiple strategies. Increasing model size can improve performance, but integrating more proactive data during training could address the core issue of reasoning instability. Additionally, the adoption of a "propose-then-verify" framework is recommended for leveraging models' inherent verification capabilities.
Training-Free Approaches
Given the observed high potential through repeated trials, implementing methods that efficiently harness this latent potential without extensive retraining could significantly improve real-time applications.
Conclusion
This work advances the field of AI safety by introducing a robust benchmark for evaluating the proactive risk awareness of MLLMs. While it identifies current limitations, it also outlines clear pathways for enhancing the effectiveness of AI systems in safety-critical environments. Future work should focus on refining reasoning capabilities and developing more scalable implementations for real-world applications.