- The paper introduces live music models that enable real-time interactive music generation via AI-driven codec language models and dynamic style embeddings.
- It employs SpectroStream for audio tokenization and MusicCoCa for joint audio-text style control to maintain high-quality, infinite streaming outputs.
- Experiments demonstrate Magenta RT outperforms competitors with superior fidelity, low latency, and flexible user control, revolutionizing live music production.
Live Music Models
Introduction
The paper introduces a novel class of generative AI models designed for real-time music creation, termed "live music models." These models, Magenta RealTime (RT) and Lyria RealTime (RT), emphasize human-in-the-loop interaction, allowing real-time control of music generation through continuous user input. The paper details the technological advancements achieved through these models, including first-of-its-kind live generation capabilities via open weights and API-based systems, offering flexible controls for artists and users.
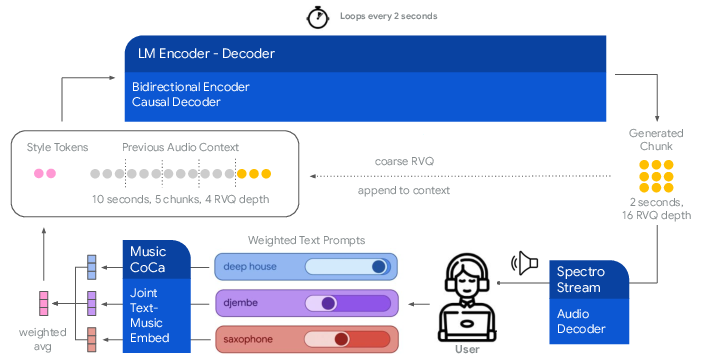
Figure 1: Magenta RealTime is a live music model that generates an uninterrupted stream of music and responds continuously to user input. It generates audio in two-second chunks using a pipeline with three components: MusicCoCa, a style embedding model, and SpectroStream.
Methodology
Magenta RT employs a codec LLM structure, enabling high-fidelity stereo audio generation conditioned on user-specified acoustic styles. The process involves encoding music into tokens using SpectroStream, a neural audio codec, and style embeddings computed by MusicCoCa. MusicCoCa fuses text and audio data into a shared embedding space, serving as a control signal for the generative model.
Audio Tokenization via SpectroStream
SpectroStream functions as the discrete audio codec in Magenta RT, transforming raw audio into RVQ-encoded tokens while preserving audio quality. With reduced bandwidth optimized for streaming, this codec facilitates real-time generation, producing compressed audio representations essential for the model's infinite streaming capability.
Style Embeddings with MusicCoCa
MusicCoCa constructs joint audio-text embeddings, enabling detailed control over music style characteristics. These embeddings, derived from diverse textual annotations and audio data, allow fine-grained stylistic manipulations in generated audio through quantized token mapping.
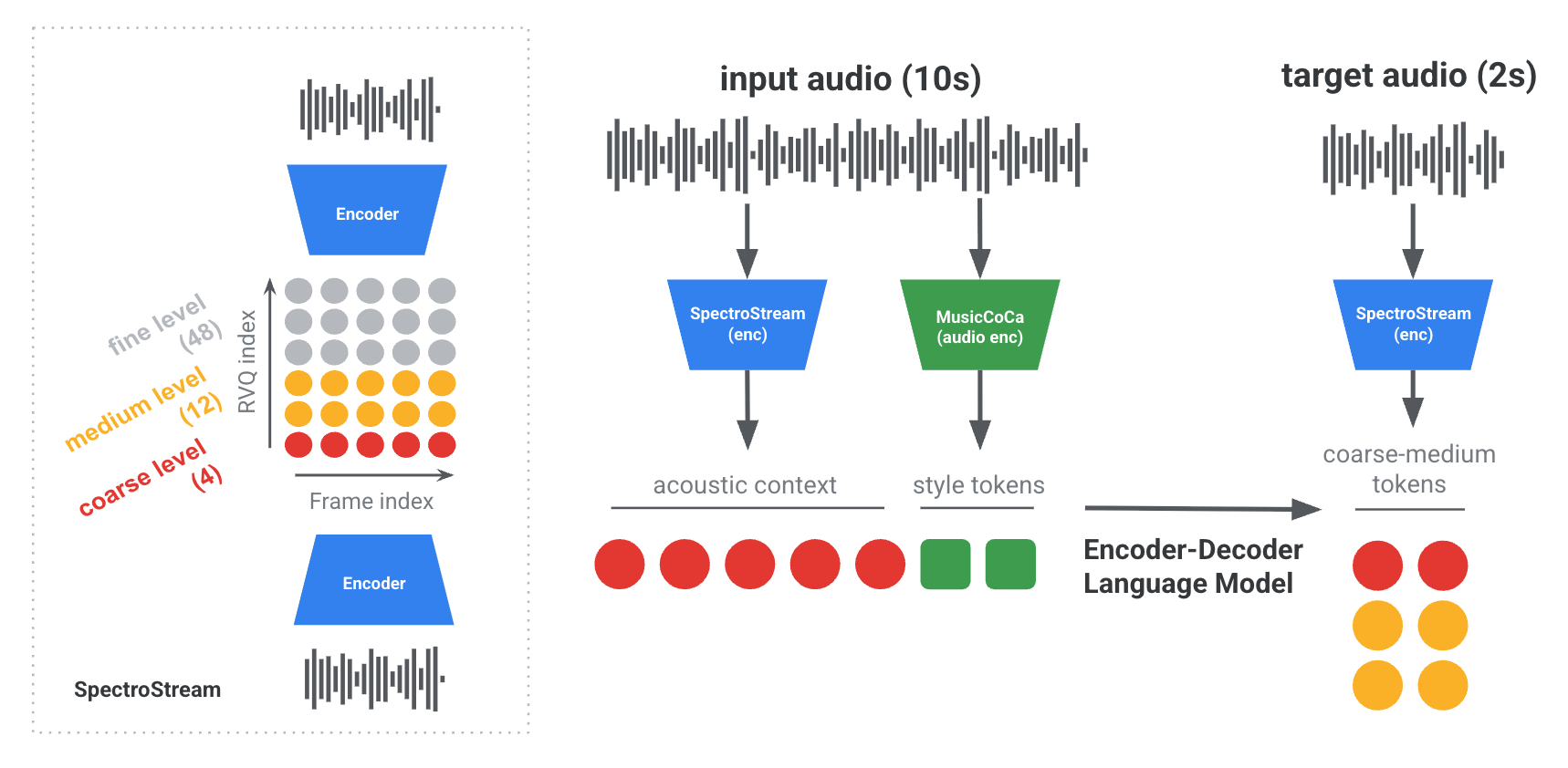
Figure 2: Overall architecture of Magenta RT. Coarse acoustic tokens and quantized style tokens corresponding to 10 seconds of audio context are concatenated and fed to the model's encoder.
Model Framework
Magenta RT's framework builds on established codec LM principles but introduces adaptations for live performance: a single-stream LLM enabling efficient operation and chunk-based autoregression for infinite audio stream predictions. These adjustments ensure that the model maintains high throughput and low latency, essential for real-time applications.
Chunk-based Autoregression
The model predicts audio chunks continuously, based on limited, recent acoustic history, without preserving information beyond the context window. This stateless inference approach minimizes errors and supports flexible real-time control, effectively generating audio with a Real-Time Factor (RTF) greater than or equal to one.
Experiments
Audio Quality Evaluation
Empirical analysis demonstrates that Magenta RT surpasses existing models like Stable Audio Open and MusicGen Large in quality metrics, including FDopenl3 and KLpasst. Despite employing fewer parameters, Magenta RT achieves superior audio generation fidelity, showing strong adherence to text prompts while enabling arbitrary-length audio outputs.
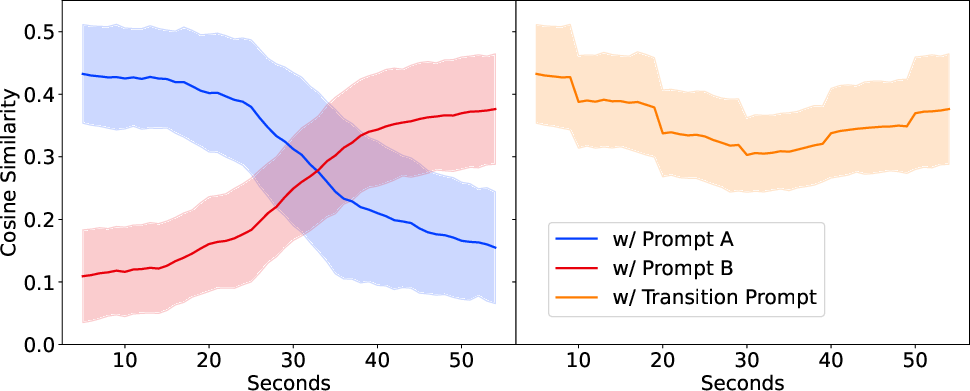
Figure 3: Evaluation demonstrates transitions between prompt embeddings via linear interpolation, indicating strong model adherence to sequential style changes.
Musical Transitions Experiment
Magenta RT's ability to smoothly transition between musical styles under dynamic prompting conditions showcases its unique capabilities for live interaction, preserving coherence throughout stylistic evolution and offering seamless blend experiences for users.
Applications and Implications
The models bring transformative potential to live music production by offering creative interactive tools for musicians and producing continuous, adaptable soundscapes in real-time. By enhancing human-machine musical experiences, they can redefine live performance paradigms and foster novel artistic possibilities in AI music generation.
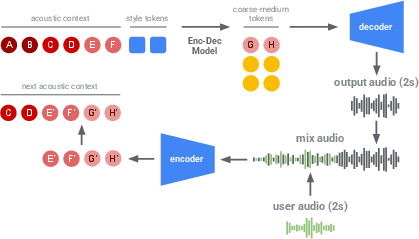
Figure 4: Steering with live audio stream illustrates user-controlled audio progression using the audio injection method, allowing real-time modification to the output.
Conclusion
Live music models, through systems like Magenta and Lyria RT, advance the landscape of generative AI in music by providing real-time interaction and control capabilities. Their innovative approach to codec LLMing and style embedding sets foundations for future AI-centric music performance enhancements, promoting more engaging, responsive, and personalized musical expressions. Further developments aiming at reducing latency will expand their interactive potential as musical partners and sophisticated synthesisers.

