- The paper introduces MusicLM, which synthesizes coherent, high-fidelity music from text using a hierarchical sequence-to-sequence modeling approach.
- It employs pre-trained models like SoundStream, w2v-BERT, and MuLan to capture acoustic and semantic tokens, achieving superior performance over baseline methods.
- Human evaluations and quantitative metrics such as FAD and MCC confirm MusicLM's capability to generate minutes-long, musically coherent sequences with minimal memorization.
An Evaluation of "MusicLM: Generating Music From Text"
Introduction
"MusicLM: Generating Music From Text" (2301.11325) introduces a significant advancement in the domain of generative music modeling. The paper presents MusicLM, a model designed to generate high-fidelity music from text descriptions. This model builds upon the framework established by AudioLM, incorporating text conditioning into the generative process. By utilizing a hierarchical sequence-to-sequence modeling approach, MusicLM achieves the synthesis of coherent music clips that are consistent over several minutes and adhere closely to input text prompts.
Methodology
MusicLM leverages a combination of advanced techniques to achieve its results. Central to its approach is the hierarchical sequence modeling framework that enables the generation of structured musical content. The model relies on three key pre-trained components for audio representation: SoundStream for acoustic tokens, w2v-BERT for semantic tokens, and MuLan for shared music-text embeddings. These models are pre-trained independently to capture different facets of audio representation.
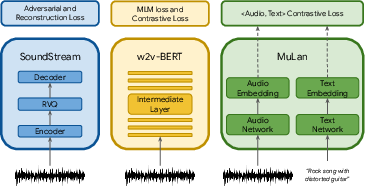
Figure 1: Independent pretraining of the models providing the audio and text representations for MusicLM.
The training methodology divides the process into semantic modeling and acoustic modeling stages. In the semantic stage, the model predicts semantic tokens from MuLan audio tokens, whereas the acoustic stage involves the prediction of acoustic tokens conditioned on both MuLan audio tokens and semantic tokens.
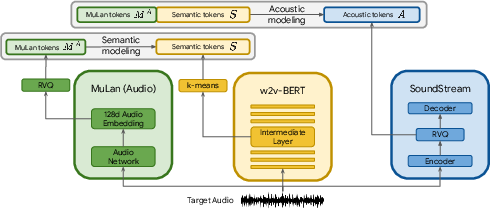
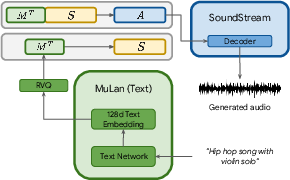
Figure 2: During training, we extract the MuLan audio tokens, semantic tokens, and acoustic tokens from the audio-only training set.
During inference, the model uses MuLan text tokens derived from text prompts as its conditioning signal, effectively leveraging the shared embedding space between music and text to guide music generation.
Results and Evaluation
The paper reports extensive experimental results, demonstrating MusicLM's superior performance over baseline models such as Mubert and Riffusion. The evaluation encompasses both quantitative measures and qualitative listening tests.
Quantitatively, MusicLM achieved favorable scores in terms of Fréchet Audio Distance (FAD) and MuLan Cycle Consistency (MCC), indicating high audio quality and strong adherence to text descriptions, respectively. The human listener studies further validated these findings by showing a marked preference for MusicLM outputs over both baselines.
Figure 3: Pairwise comparisons from the human listener study. Each pair is compared on a 5-point Likert scale.
The model's ability to generate long and coherent music sequences was emphasized as a key strength. Additionally, the paper tackled the memorization issue by conducting a detailed analysis, which revealed minimal memorization of training data, ensuring creative diversity in generated outputs.
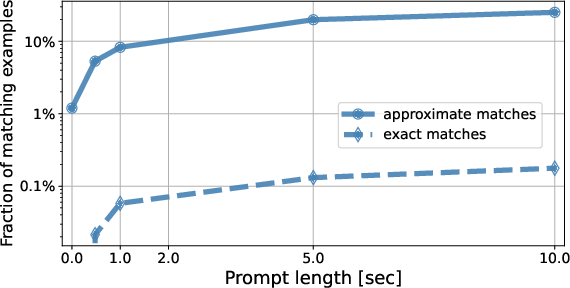
Figure 4: Memorization results for the semantic modeling stage.
Extensions and Future Work
MusicLM includes valuable extensions such as melody conditioning and the potential for story-mode generation. These extensions allow for more dynamic and adaptive music generation, accommodating changes in text conditions over time. The paper identifies areas for future exploration, notably in enhancing text conditioning, improving vocal quality, and achieving higher sample rates.
Conclusion
"MusicLM: Generating Music From Text" represents an advancement in the field of music generation, offering a robust solution for generating high-quality music from natural language descriptions. The proposed model synthesizes music that not only maintains high fidelity but also aligns closely with the semantic content of text prompts. While the model shows pronounced efficacy, the paper acknowledges certain limitations and prompts future research directions, particularly in text comprehension and broader evaluative capabilities. Overall, MusicLM establishes a foundational step towards integrating AI in creative musical applications.

