- The paper introduces MedCheck, a lifecycle framework that systematically evaluates medical benchmarks for clinical reliability.
- It assesses design, dataset integrity, reasoning, and governance, revealing significant flaws in current evaluation methods.
- Empirical findings show over 50% of benchmarks fail to meet medical standards, highlighting the need for more robust, real-world metrics.
Beyond the Leaderboard: Rethinking Medical Benchmarks for LLMs
The paper introduces MedCheck, a lifecycle-oriented framework for evaluating medical benchmarks tailored to assess LLMs in healthcare settings. It identifies systemic issues within existing medical benchmarks and proposes a structured evaluation process that moves beyond traditional methods to ensure reliability and clinical relevance.
Motivation and Impact
The paper addresses concerns about the reliability and clinical applicability of current medical benchmarks. Traditional benchmarks often rely heavily on closed-form multiple-choice questions (MCQA), which assess basic factual knowledge but fail to evaluate models' ability to engage in open-ended clinical reasoning. Furthermore, many benchmarks are constructed from non-clinical data sources, risking contamination and divergence from real-world applicability. The introduction of MedCheck aims to standardize evaluation across five continuous stages to address these deficiencies.
The potential impact of MedCheck in transitioning from superficial benchmarks towards reliable measures in AI healthcare processes is significant. By focusing on domains like data contamination and safety-critical evaluation dimensions, MedCheck is poised to advance the development of trustworthy clinical AI systems.
MedCheck Framework and Methodology
MedCheck introduces a five-phase lifecycle model for medical benchmark development, which emphasizes stages from design to governance. Each phase is intricately connected with criteria designed to evaluate benchmarks thoroughly. These criteria focus on construct validity, dataset authenticity, and the comprehensive assessment of model capabilities.
- Design and Conceptualization: This stage transcends basic task definition, focusing on the benchmark's theoretical underpinnings. Construct validity is emphasized, with a need for alignment with formal medical standards and inclusion of multi-dimensional metrics. Less than half of existing benchmarks align with medical standards, pointing to a profound disconnect from clinical practice.
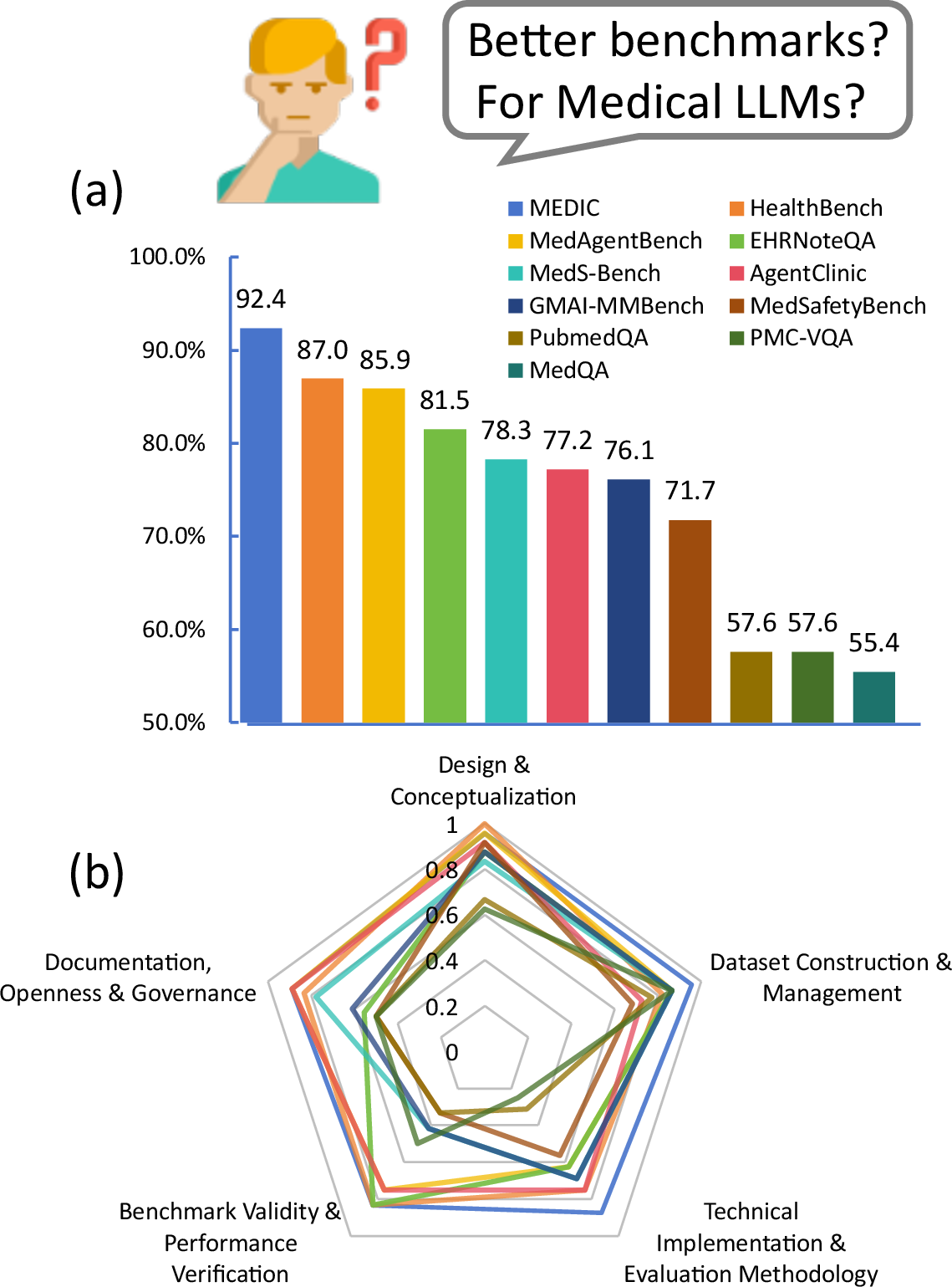
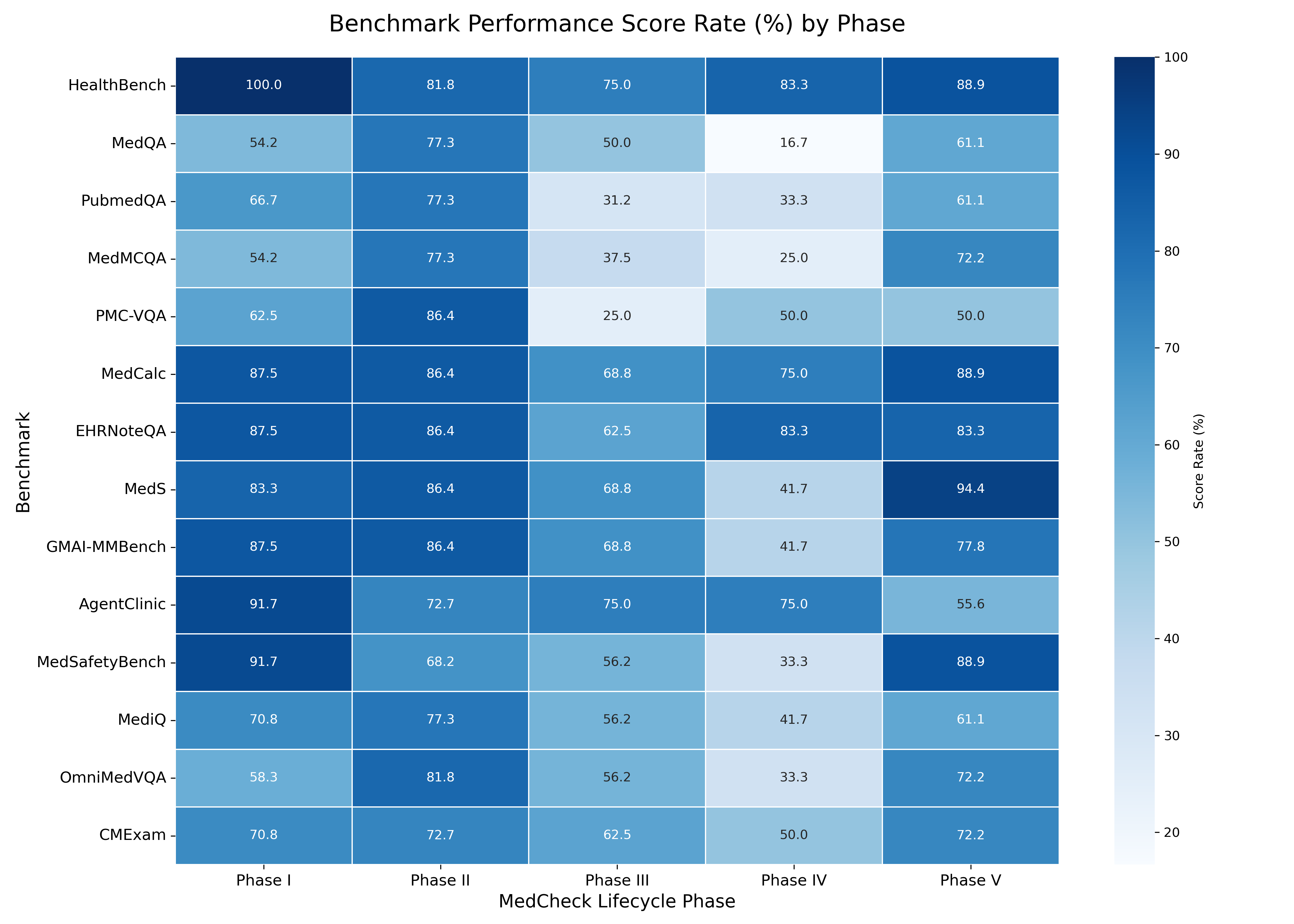
Figure 1: (a) Overall and (b) phase-by-phase performance of medical LLM benchmarks. The significant variance, identified through our MedCheck evaluation, highlights the core motivation for this work: the development of a principled framework for systematic benchmark evaluation.
- Dataset Construction and Management: It critically evaluates the sources for diversity, contamination prevention, and adherence to privacy regulations. Many benchmarks currently lack mechanisms for detecting contamination, leading to artificially inflated performance scores.
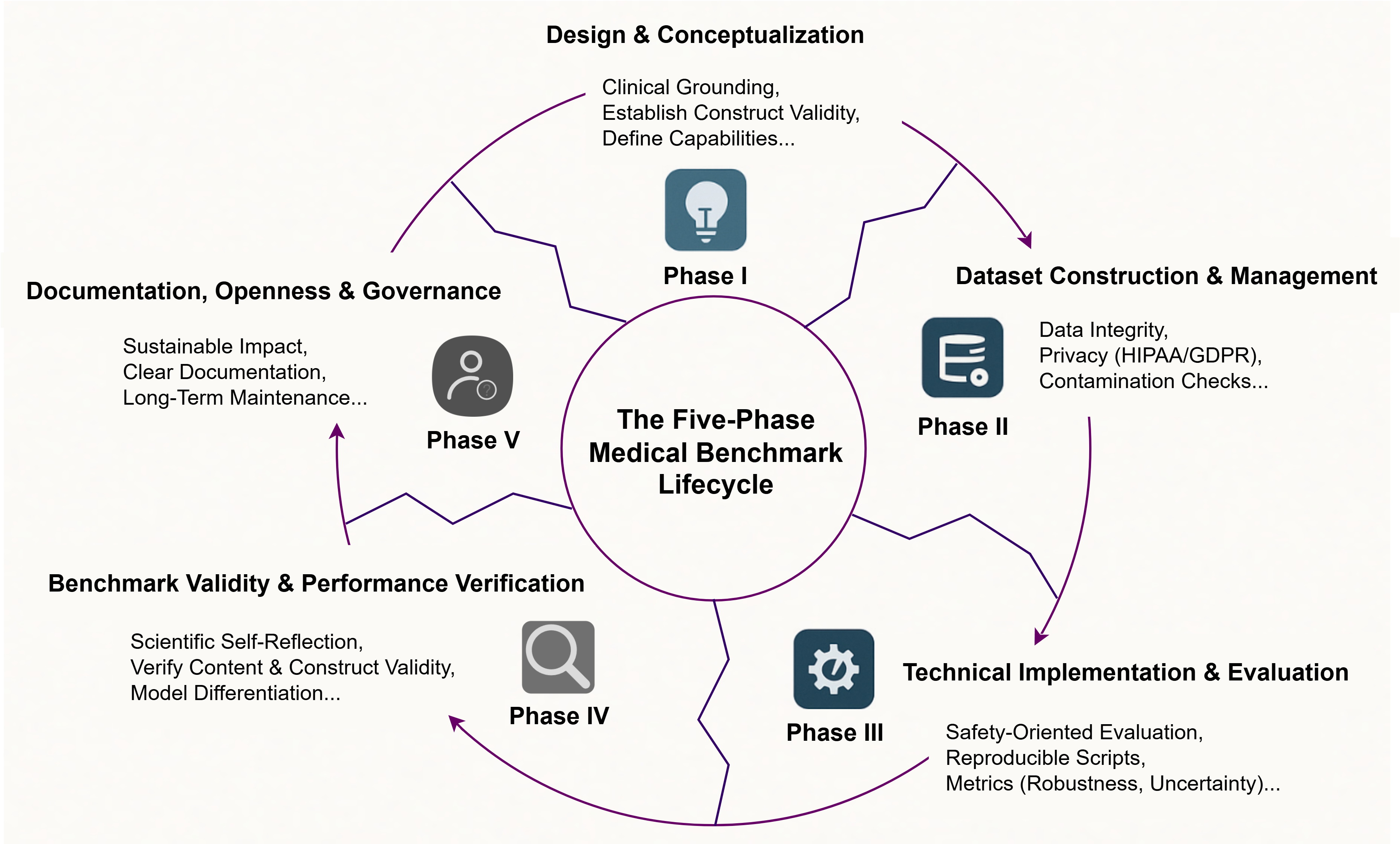
Figure 2: The proposed five-phase lifecycle for medical benchmark engineering. This model illustrates the interconnected and continuous stages of development, from initial design and conceptualization to long-term documentation and governance.
- Technical Implementation and Evaluation Methodology: Beyond traditional performance measures like accuracy, this phase includes the evaluation of reasoning processes, robustness, and uncertainty. Most benchmarks neglect these aspects, failing to assess critical safety features.
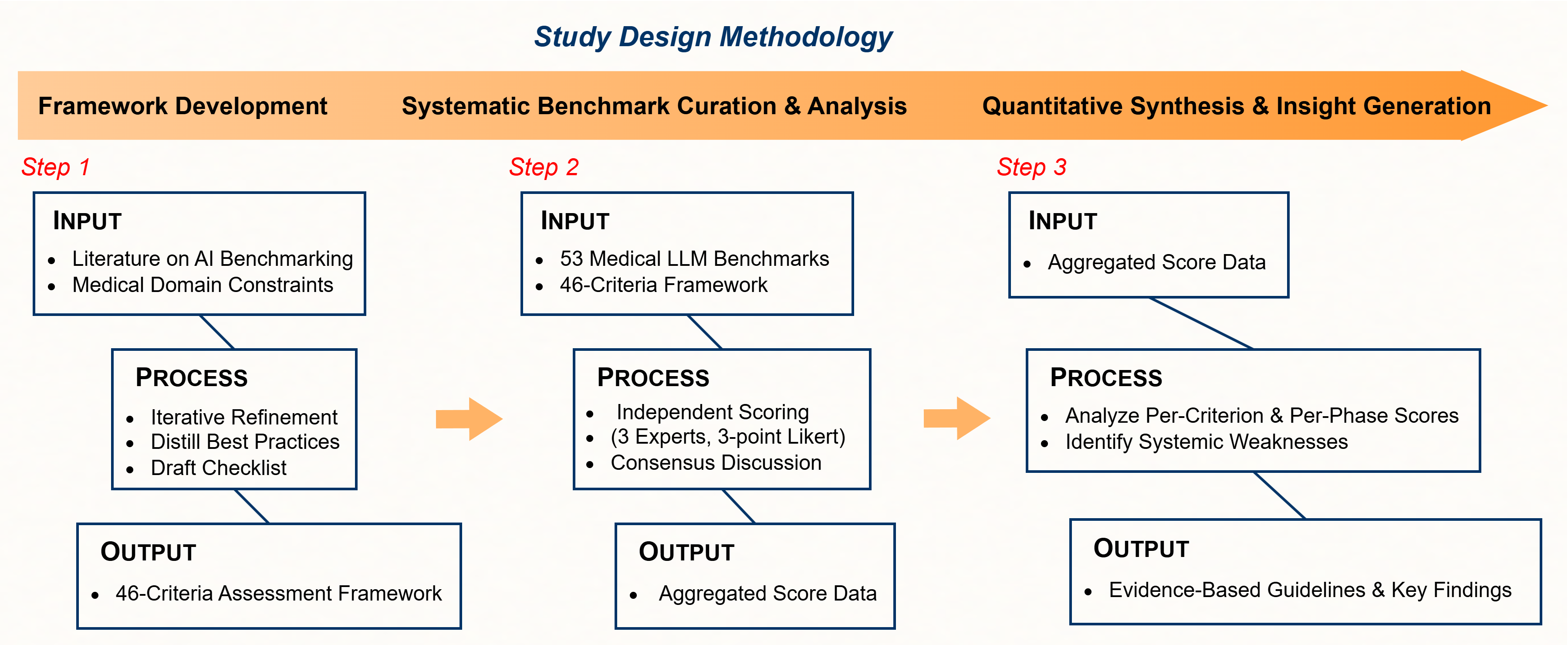
Figure 3: The three-step methodology employed in this study. Our approach involved (1) developing the 46-criteria assessment framework, (2) systematically curating and scoring 53 benchmarks against it, and (3) performing a quantitative synthesis to generate systemic insights.
- Benchmark Validity and Performance Verification: Focused on empirical validation, this stage demands evidence that benchmark scores translate to real-world clinical performance. Only 40% of current benchmarks reflect realistic clinical settings, raising concerns about their external validity.
- Documentation, Openness, and Governance: This final phase ensures clarity in documentation, promotes open-source access, and institutes governance mechanisms for maintenance and updates. The lack of robust governance models in existing benchmarks threatens sustainability.
Empirical Findings and Analysis
The paper's empirical evaluation of 53 benchmarks underscores systemic weaknesses. A vast majority fail to comprehensively address critical safety and robustness evaluations:
Discussion and Future Directions
The study reveals a pressing need for a paradigm shift in medical LLM benchmarking. By addressing limitations, the MedCheck framework offers a path to producing clinically relevant and scientifically rigorous benchmarks. The authors propose future directions focusing on:
- Dynamic and interactive benchmarks that reflect real-time decision-making processes.
- Empirical correlation between benchmark evaluation and clinical application outcomes.
- A collaborative ecosystem, fostering open discussion and improvement of benchmarks.
Conclusion
MedCheck confronts the prevailing inadequacies in medical benchmarks by redefining evaluation metrics through a lifecycle framework. Its adoption promises to transition the field from performance illusions driven by flawed benchmarks to a future grounded in genuine clinical applicability and reliability.
In summary, "Beyond the Leaderboard: Rethinking Medical Benchmarks for LLMs" establishes a comprehensive, responsible framework designed to enhance the consistency, transparency, and reliability of LLM evaluations in healthcare, marking a significant step forward for AI applications in medicine.