- The paper introduces the LaRMA framework to evaluate reasoning in LLM-based agent tasks by segmenting activities into tool usage, plan design, and problem-solving.
- It demonstrates that LRMs excel in intricate reasoning tasks such as plan design, while LLMs perform better in execution-focused tasks.
- Hybrid configurations combining LLMs and LRMs achieve optimal trade-offs between computational cost and reasoning depth for enhanced agent performance.
Exploring the Necessity of Reasoning in LLM-based Agent Scenarios
Introduction
The paper "Exploring the Necessity of Reasoning in LLM-based Agent Scenarios" provides an analytical framework to understand the role of reasoning within agent scenarios powered by LLMs and Large Reasoning Models (LRMs). The LaRMA framework was proposed to assess reasoning across nine specific tasks involving tool usage, plan design, and problem-solving, aiming to delineate the contributions and constraints of reasoning capabilities in enhancing agent performance.
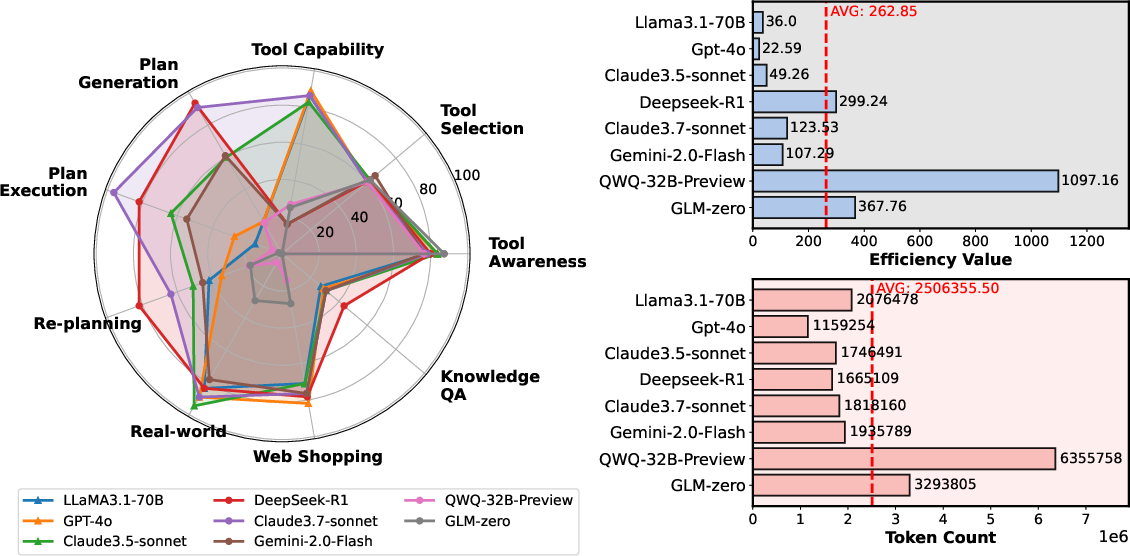
Figure 1: Overall Performance in the ReAct Paradigm. a) Performance across tasks and models; b) Efficiency and cost comparisons.
Methodology
The LaRMA framework is structured into three phases:
- Task Segmentation for Agent Capabilities: This phase involves dividing agent tasks into key categories such as tool usage, plan design, and problem-solving, thereby quantifying the reasoning demands within each task dimension.
- Selection for Generic Agent Paradigms: Two agent paradigms, ReAct and Reflexion, are employed to evaluate reasoning within real-time interaction and reflective settings, respectively. This phase highlights reasoning's impact on agent behaviors across varied environments.
- Performance Assessment: Multiple models are analyzed using metrics including accuracy, efficiency, and computational cost. This objective assessment reveals the practical significance of reasoning within different agent scenarios.
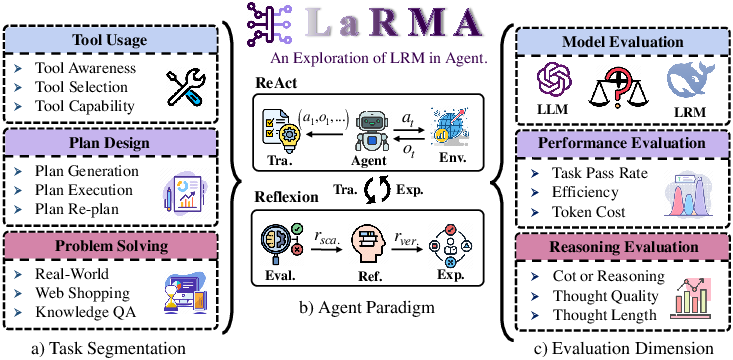
Figure 2: Overview of the LaRMA Investigation Process.
Experimental Insights
The experimental results reveal that LRMs exhibit superior performance in tasks demanding intricate reasoning, such as plan design, compared to LLMs, which perform better in execution-focused tasks. Reflexion proved more beneficial than ReAct for LLMs, enhancing efficiency through iterative improvement. Conversely, LRMs benefit less from Reflexion due to innate reasoning strengths, highlighting model-specific adaptation to reasoning paradigms.
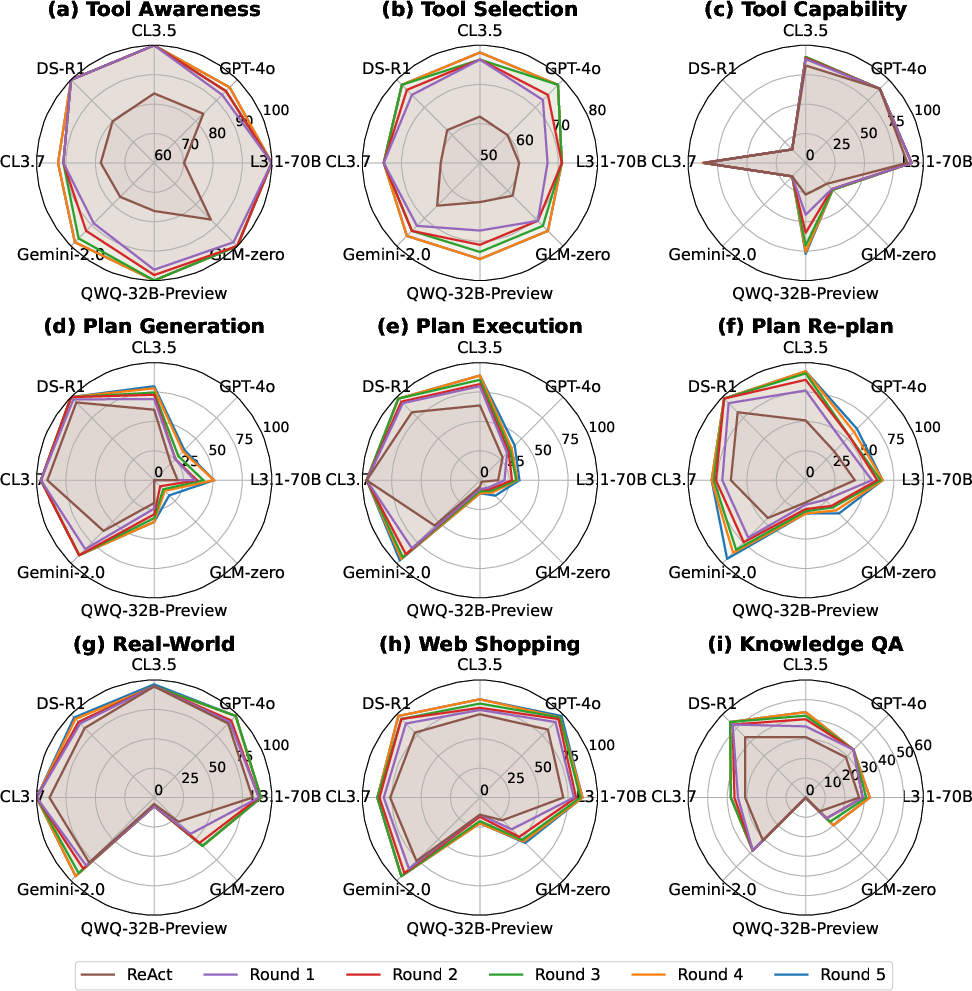
Figure 3: Performance trends across Reflexion iterations.
Computational Trade-offs
LRMs, while excelling in deep reasoning tasks, incur higher computational costs and latency compared to LLMs. Token usage and execution time metrics underscore a trade-off between reasoning efficiency and computational demands, posing a challenge in resource-constrained environments.
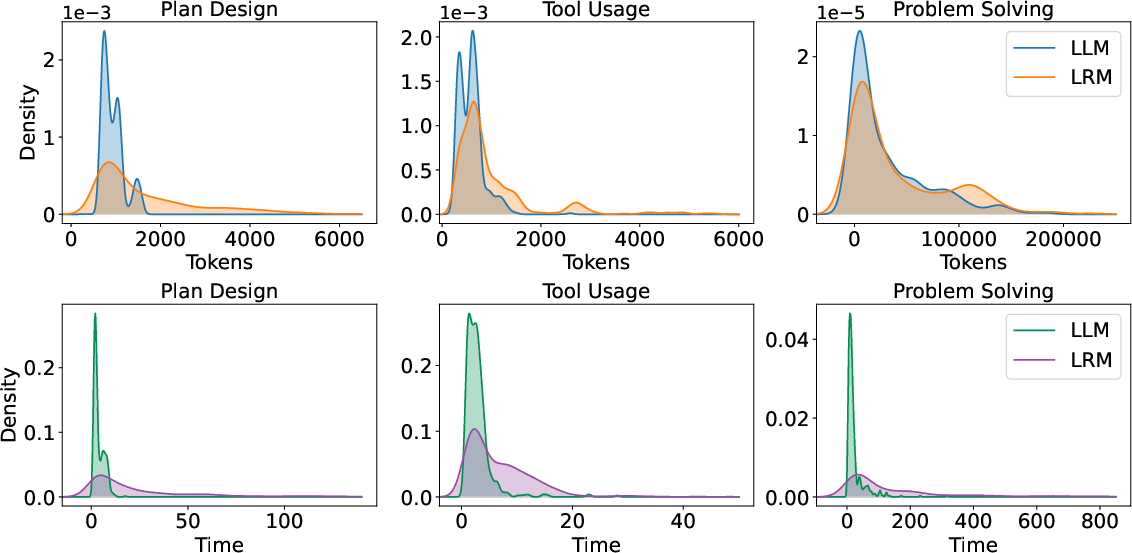
Figure 4: Probability Distributions of Token Usage and Execution Time for LLMs and LRMs Across Three Task Domains.
Hybrid Configurations
Hybrid LLM-LRM settings, where LLMs execute tasks while LRMs refine strategies through reflection, yield optimal performance. This configuration leverages LLMs' speed and LRMs' reasoning depth, suggesting a promising direction for enhancing agent functionality.
Challenges and Limitations
Key dilemmas associated with LRM deployment include overthinking and fact-ignoring tendencies, which detract from decision-making precision and efficiency. Addressing these inaccuracies is crucial for enhancing LRM reliability in dynamic agent tasks.
Conclusion
The study delineates the importance of reasoning in LLM-based agent applications, fostering an understanding of the nuanced roles that reasoning plays across various models and tasks. By highlighting the strengths and limitations of LLMs and LRMs, the paper sets a foundation for optimizing agent architectures through enhanced reasoning integration, balancing computational efficiency with reasoning depth. These insights offer a pathway toward more adaptive and robust AI agent designs capable of navigating complex real-world scenarios.