- The paper introduces neural-based evaluation metrics and specialized tokenization to address n-gram shortcomings in diverse languages.
- It demonstrates that metrics' correlation with human judgment varies significantly with linguistic typology, especially in fusional languages.
- The study recommends fine-tuning large language models on multilingual datasets to enhance abstractive summarization performance.
Beyond N-Grams: Rethinking Evaluation Metrics and Strategies for Multilingual Abstractive Summarization
Introduction to Multilingual Evaluation
The paper "Beyond N-Grams: Rethinking Evaluation Metrics and Strategies for Multilingual Abstractive Summarization" addresses the inadequacy of traditional n-gram-based metrics, like ROUGE, in evaluating summaries across different languages. These metrics, while indicative for English, struggle with the linguistic diversity of non-English languages, especially those with rich morphology and complex tokenization schemes. The authors propose a comprehensive evaluation suite across eight languages from four typological families to better understand these issues.
Assessment and Findings
Typological Sensitivity: The study finds that n-gram-based metrics are highly sensitive to linguistic typology. For fusional languages, which exhibit complex morphological structures, these metrics frequently show negative correlations with human assessments. However, agglutinative and isolating languages show better alignment with n-gram metrics, though still imperfect.
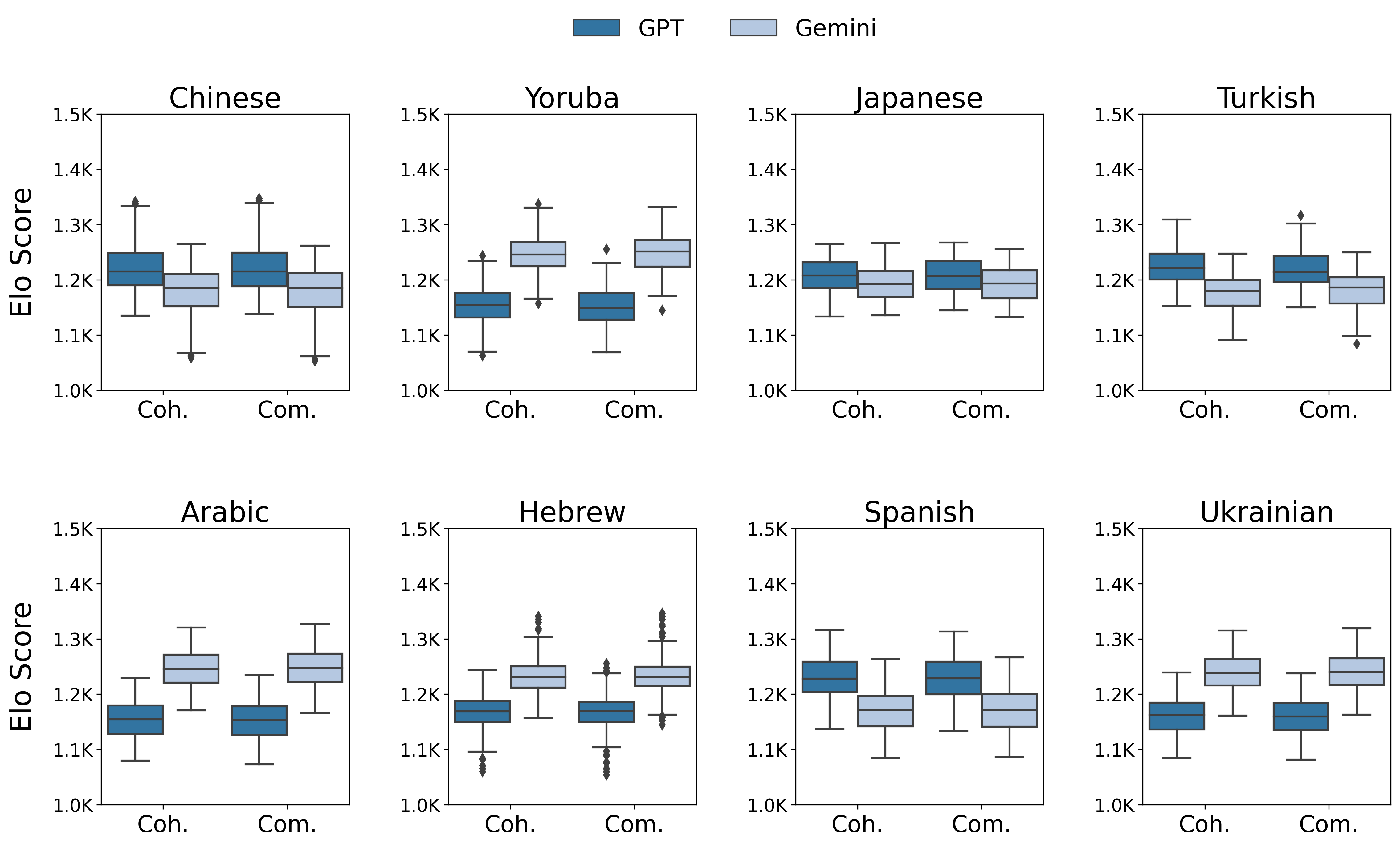
Figure 1: Elo score distribution of human annotations for Gemini- and GPT-generated summaries across all criteria. Coh. = Coherence, Com. = Completeness.
Mitigation Strategies: The authors suggest using specialized tokenization strategies to improve the performance of n-gram metrics in fusional languages. Tokenizers that can handle complex morphological units better facilitate a more accurate evaluation.
Neural-Based Metrics
The paper also explores the efficacy of neural-based metrics. COMET, a neural network trained specifically for evaluation tasks, outperforms other metrics in terms of correlation with human judgments, especially in low-resource languages. This suggests that task-specific training can bridge the gap between automated metrics and human evaluation.
Implementation of Neural Metrics
Implementing neural metrics requires access to pre-trained models like COMET, which utilize LLMs such as XLM-R for assessment. The recommended approach for practitioners is to fine-tune these models on relevant datasets if computationally feasible, as this can significantly improve performance over generic models.
Sample Implementation:
1
2
3
4
5
6
7
8
9
10
11
|
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "facebook/wmt19-comet-da-xlm-r"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def evaluate_summary(summary, reference):
inputs = tokenizer(summary, reference, return_tensors="pt")
outputs = model(**inputs)
score = outputs.logits.softmax(dim=-1)[0][1] # Assuming binary relevance score
return score.item() |
Practical Implications and Future Work
The study advocates for a transition towards neural-based metrics specifically trained for multilingual evaluation tasks. This is particularly crucial for languages with complex morphological structures. Furthermore, adapting existing LLM architectures to include such metrics could improve the evaluation of generative tasks across languages.
Conclusion
The paper provides a comprehensive analysis of the shortcomings of existing summarization evaluation metrics in multilingual contexts. By advocating for neural approaches tailored to specific evaluation tasks, the research highlights a pathway towards more equitable and effective assessment methodologies. Future developments may include expanding task-specific training for broader linguistic coverage and integrating these metrics into generative model evaluation workflows.
In conclusion, this work underscores the necessity of rethinking evaluation frameworks in multilingual text generation, promoting specificity and adaptability to handle linguistic diversity effectively.