- The paper presents SingLoRA, replacing dual-matrix updates with a symmetric single-matrix low-rank adaptation that eliminates scale imbalances for greater stability.
- It demonstrates superior performance on both language and vision tasks, achieving higher accuracy and reduced parameter counts compared to traditional LoRA methods.
- Empirical experiments and ablation studies confirm that SingLoRA is robust to hyperparameter variations and compatible with standard optimizers like SGD and Adam.
SingLoRA: A Symmetric Single-Matrix Paradigm for Low-Rank Adaptation
Motivation and Theoretical Foundations
Low-Rank Adaptation (LoRA) has become a dominant method for parameter-efficient fine-tuning (PEFT) of large pretrained models by injecting a low-rank update composed from two matrices. However, scale imbalances between these matrices (A and B) introduce instability, especially as model width increases, resulting in vanishing or exploding gradients and suboptimal optimization. SingLoRA introduces a structural change: the pretrained weight matrix is updated by a symmetric low-rank matrix, parameterized as W0+AA⊤, where A∈Rn×r is the sole trainable parameter, effectively halving the parameter count compared to LoRA and eliminating inter-matrix scaling conflicts.
Analyzing SingLoRA in the infinite-width regime and via transformation-invariance, the paper demonstrates that the update dynamics are inherently stable. Contrary to LoRA—which requires specialized learning rates or Riemannian optimization to negotiate inter-matrix scale—SingLoRA achieves feature learning stability using standard first-order optimizers such as SGD and Adam.
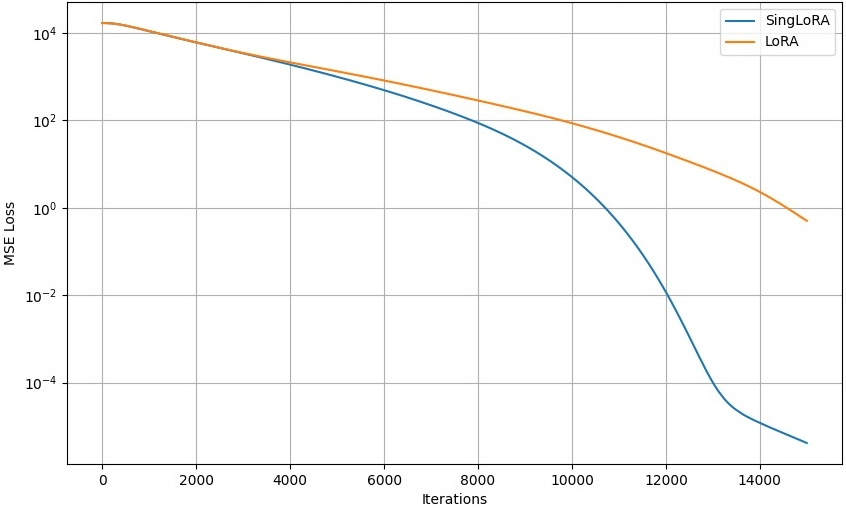
Figure 1: Synthetic experiment: convergence plot comparing LoRA and SingLoRA, demonstrating superior convergence speed and final accuracy for SingLoRA.
Empirical Results: Language and Vision Tasks
The empirical evaluation spans several modalities. In natural language tasks, RoBERTa-base and GPT-2 models fine-tuned on GLUE, MNLI, QQP, and QNLI benchmarks with SingLoRA show a mean accuracy improvement of up to 1.1% over LoRA with only half the parameter budget. For large-scale LLM adaptation, fine-tuning Llama-7B on MNLI yields 91.3% accuracy with only 12M parameters using SingLoRA, surpassing LoRA (89.1%, 20M), LoRA+ (90.2%, 20M), and DoRA (90.6%, 21M). Importantly, SingLoRA maintains performance stability across a broad range of learning rates, in contrast to LoRA, which fluctuates by nearly 5%.
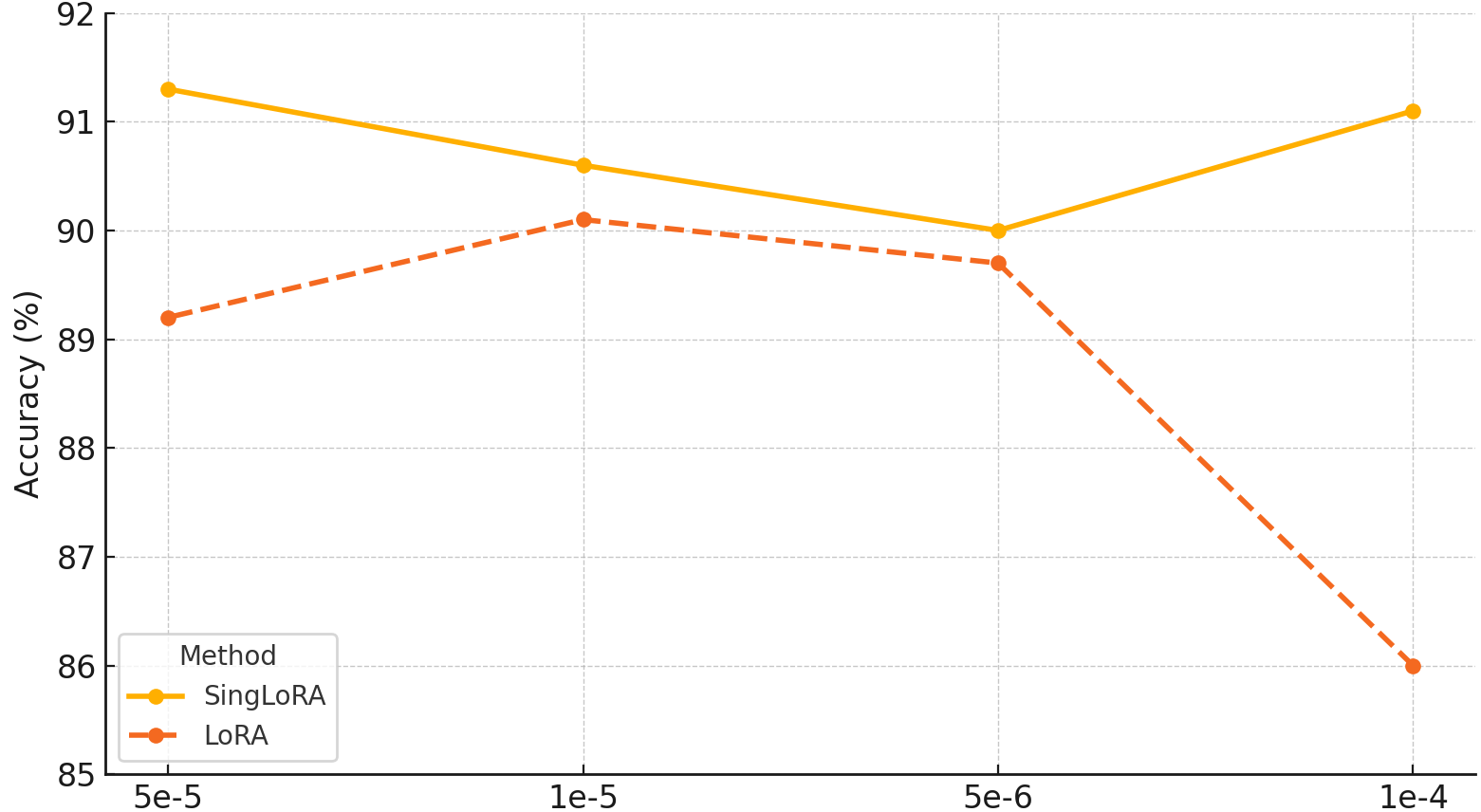
Figure 2: Accuracy of Llama-7B fine-tuned on MNLI across varying learning rates, highlighting SingLoRA’s robustness relative to LoRA.
In image generation, SingLoRA fine-tuning of Stable Diffusion on DreamBooth delivers significant improvement in DINO similarity score (0.151 with 16-rank adapters), representing a 5.4% relative improvement over LoRA and DoRA, while offering prompt fidelity and object retention qualities superior to prior methods.

Figure 3: Qualitative comparison of LoRA, DoRA, and SingLoRA on Dreambooth, illustrating improved subject fidelity with SingLoRA.
Additional experiments show that SingLoRA adapts robustly even with automatically-generated datasets such as synthetic faces, emphasizing its ability to capture nuanced detail across domains.

Figure 4: Samples from the synthetic face dataset used in image generation experiments, reinforcing SingLoRA’s expressivity.
Stability, Robustness, and Hyperparameter Sensitivity
SingLoRA’s optimization dynamics are inherently more robust to hyperparameter variation than LoRA and its variants. The transition from pretrained weights is managed by a ramp-up function u(t) controlling adaptation rate, and ablation studies confirm that performance is resilient to the choice of ramp hyperparameter T, eliminating the need for exhaustive searching.
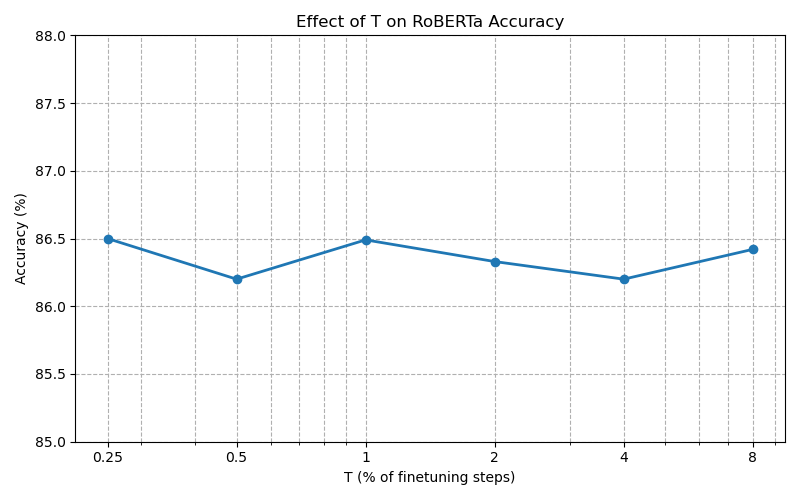
Figure 5: Ablation study on hyperparameter T for SingLoRA’s ramp-up function, showing robustness across values.
Architectural Implications and Expressiveness
Despite the symmetric structure of the update AA⊤, SingLoRA retains full expressiveness in transformer architectures. Analysis of self-attention layers shows that the interactions between separate query and key updates do not constrain the attention patterns to symmetric forms unless the matrices commute, which is not the case in general. Synthetic attention experiments confirm that approximation accuracy with SingLoRA significantly exceeds that of LoRA given equal parameter counts.
Practical and Theoretical Implications
From a practical perspective, SingLoRA yields parameter-efficient adaptation with improved generalization, greatly reduced hyperparameter sensitivity, and robust optimization using standard optimizers. Theoretically, SingLoRA leverages the mathematical properties of transformation-invariance to guarantee stability in feature learning, making it broadly applicable across architectures with square and non-square weight matrices.
Integration with existing architectural variants, such as DoRA, is feasible and presents future directions for combining independent strengths. The method is shown to be complementary rather than exclusive to prior PEFT paradigms.
Conclusion
SingLoRA represents a significant advancement in parameter-efficient fine-tuning by introducing a single-matrix low-rank update with symmetric structure. It addresses central instability issues of LoRA, achieves superior accuracy with reduced parameter counts, and offers practical robustness to optimization settings. The theoretical guarantees, extensive empirical validation, and architectural compatibility underline its suitability as a general-purpose adapter for both LLMs and high-capacity vision generators. Future developments are expected in hybridization with established LoRA variants for further gains in efficiency and expressivity.