- The paper introduces a modular deep learning system, AXLearn, that achieves constant LoC-complexity and seamless adaptability to various hardware.
- AXLearn’s architecture features a Python-based composer and efficient runtime with advanced checkpointing and recovery, enabling cloud-agnostic deployment.
- Empirical evaluations demonstrate that AXLearn delivers competitive throughput and lower latency across GPUs, TPUs, and AWS Trainium for both training and inference.
AXLearn: Modular Large Model Training on Heterogeneous Infrastructure
This essay provides a comprehensive analysis of the paper "AXLearn: Modular Large Model Training on Heterogeneous Infrastructure" (2507.05411). The paper introduces AXLearn, a deep learning system optimized for scalable and high-performance training of large models on a variety of hardware infrastructures. The principal focus lies in its modular design and adaptability to heterogeneous platforms. The system emphasizes modularity through a novel measurement of Lines-of-Code (LoC)-complexity and supports efficient execution on GPUs, TPUs, and AWS Trainium.
Introduction
AXLearn addresses the growing demands of large-scale deep learning by leveraging modularity and supporting diverse computing infrastructures, essential for a technology company integrating AI models for global applications. By emphasizing strict encapsulation, AXLearn's design promotes ease of experimentation with different model architectures and training techniques, requiring minimal code changes. This is quantified through a proposed LoC-complexity metric, which indicates constant complexity as system components scale, in contrast to other deep learning systems that experience linear or quadratic complexity.
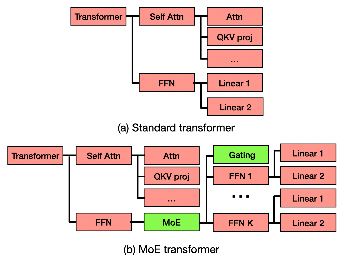
Figure 1: Specifying MoE transformer in AXLearn. Red components are reused from the specification of the standard transformer. In AXLearn, a user script that defines MoE only needs to specify the green parts of the neural network.
AXLearn Architecture
AXLearn provides a novel approach to neural network layer implementation, distinct from the subtyping paradigm common in other ML frameworks. It favors a compositional model architecture that maintains compatibility and encapsulation. This approach eliminates the compounding complexity of subtyped systems where even minor changes can trigger cascading alterations through multiple modules. The modularity is enabled through a hierarchical configuration system entirely implemented in Python, facilitating ease of use and extensibility.
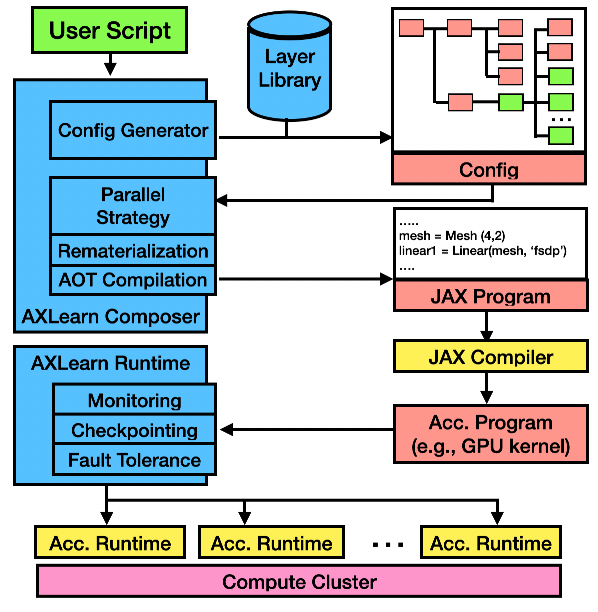
Figure 2: AXLearn's system diagram. The blue components belong to AXLearn.
The system's architecture (Figure 2) comprises two main components: AXLearn composer and AXLearn runtime, where users write hierarchical configurations processed by the composer to define complete JAX programs. This architecture supports cloud-agnostic deployment on platforms like AWS, Google Cloud, and internal servers. By leveraging XLA and GSPMD, Axelearn achieves cloud-agnosticism while maximizing hardware utilization through target-dependent optimizations.
AXLearn Composer
AXLearn's modular configuration leverages a pure Python-based interface, which encourages hierarchical config composition. This design choice supports "drop-in" replacements of network layers like MoE and RoPE by leveraging encapsulated and hierarchical modules. It avoids the need for extensive Lines-of-Code changes, which is a significant advantage for rapidly developing and scaling model architectures.
AXLearn achieves this reduced complexity by implementing layers with compatible input/output interfaces and applying strict encapsulation to all MoE-specific details, preventing these changes from propagating through the parent hierarchy. This design principle is validated through a LoC-complexity analysis, revealing a constant LoC-complexity as opposed to other systems (e.g., DeepSpeed, Megatron-LM) that incur linearly or quadratically growing changes across the system.
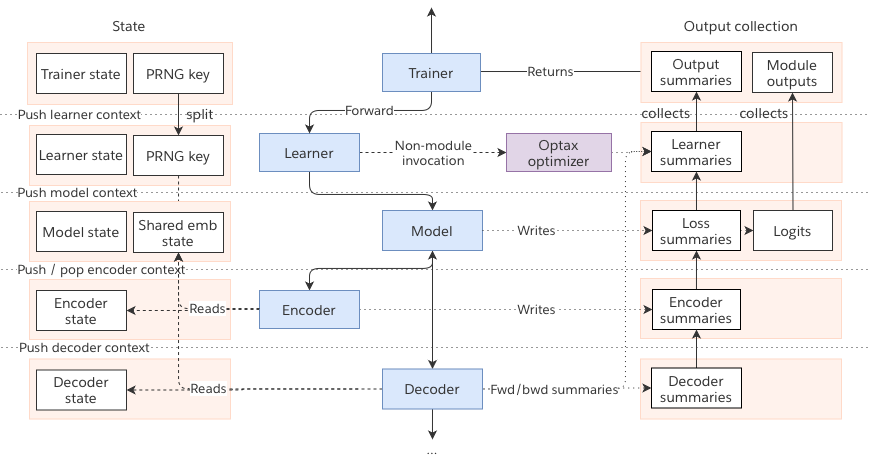
Figure 3: Invocation Context. Module invocations push contexts to the stack, which retrieve child states, split PRNG keys, and create child output collections. Upon returning, contexts are popped, collecting outputs into the parent collection. The context stack can be programmatically traversed to retrieve shared state, allowing features like tied weights to preserve encapsulation.
AXLearn Runtime
The AXLearn runtime uses orchestration to enable distributed execution, crucial for managing large-scale model training over heterogeneous infrastructure efficiently. Key components of the runtime include monitoring and profiling through integration with JAX's profiler, advanced checkpointing capabilities supporting various clouds and ensuring minimal resource waste, and robust failure detection and recovery strategies.
To maintain modularity across heterogeneous systems, AXLearn utilizes mesh rules that allow for streamlined configuration of hardware-specific optimizations. This approach allows adaptation to novel hardware, exemplified by early support for AWS Trainium2.
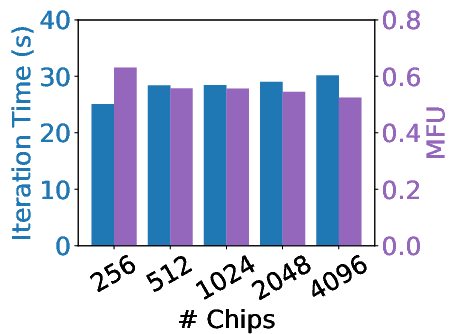
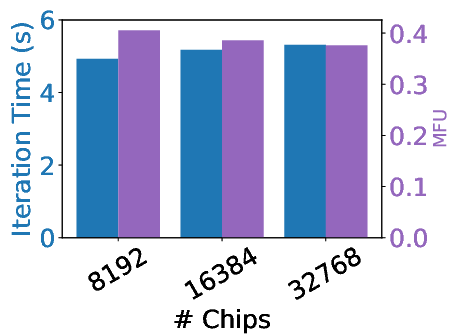
Figure 5: Comparing AXLearn with vLLM on inference throughput on TPUs.
Unifying Training and Inference
AXLearn's design facilitates the unification of training and inference processes, with significant performance advantages observed on TPUs over other state-of-the-art inference systems like vLLM. By utilizing a shared component structure, AXLearn optimizes inference without requiring additional implementation efforts, pointing to opportunities for extending this efficiency to other hardware platforms with further optimizations.
Evaluation
The evaluation of AXLearn involves both modularity analysis using LoC-complexity and empirical performance assessments across various hardware platforms. A detailed comparison with other deep learning environments demonstrates AXLearn's superior modularity, flexibility, and scalability, especially highlighted by its constant LoC-complexity in integrating MoE and RoPE across extensive model experiments.
Training performance on GPUs, TPUs, and Trainium2 shows AXLearn achieving competitive throughput and latency, showcasing its strengths over state-of-the-art systems in both training and inference scenarios on heterogeneous infrastructure.
Conclusion
AXLearn exemplifies a significant advance in deep learning systems, offering a modular framework for efficient large model training compatible with a variety of hardware backends. Its design principles provide a robust platform for researchers and engineers seeking to innovate and experiment with minimal overhead, evidencing the utility of strict encapsulation and composition in modular AI systems.

