- The paper demonstrates how MoE architectures efficiently scale LLMs by activating only a subset of parameters through conditional computation.
- It details the use of advanced gating and routing mechanisms, such as top-k selection and orthogonal constraints, to reduce computational overhead.
- The study highlights MoE's versatility, showing its applications in language modeling, computer vision, and healthcare diagnostics.
Mixture of Experts in LLMs
This essay provides an in-depth exploration of the "Mixture of Experts in LLMs" paper, which reviews the Mixture-of-Experts (MoE) architecture. Through examining its theoretical underpinnings, practical implementations, challenges, and applications, we reveal the unique benefits of MoE design for large-scale LLMs.
Introduction and Fundamentals
Mixture-of-Experts (MoE) architectures emerged as a solution to the unsustainable computational cost of scaling transformer models. Traditional scaling leads to exponential increases in FLOPs and energy usage. MoEs manage these costs by activating only a subset of the model's parameters through conditional computation. This approach not only scales model capacity efficiently but also encourages modular learning with specialized expert modules.
MoE architectures trace their origins to early works in adaptive learning systems, where models consisted of specialized ensemble experts [jacobs1991adaptive]. Progress in distributed computation has since enabled high-scale implementations, culminating in sparsely-gated networks that activate a small fraction of parameters per inference.
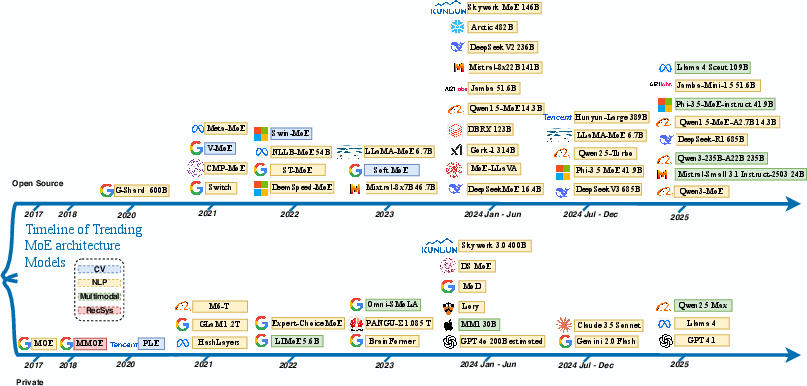
Figure 1: Timeline of mixture of experts (MoE) models development. The timeline shows key milestones in MoE architecture evolution from foundational concepts to modern large-scale implementations.
MoEs now serve as a flexible alternative to monolithic deep learning models, improving generalization and robustness across tasks. They have diversified across application domains, including language modeling, machine translation, and vision-language reasoning, demonstrating their versatility in real-world scenarios.
Core Architectures and Routing Mechanisms
MoE models include gating mechanisms, expert routing strategies, and architectural variations to improve efficiency. In fundamental MoE architectures, each input is routed to a sparse subset of experts via top-k routing, reducing computational load while maintaining parallel scalability.
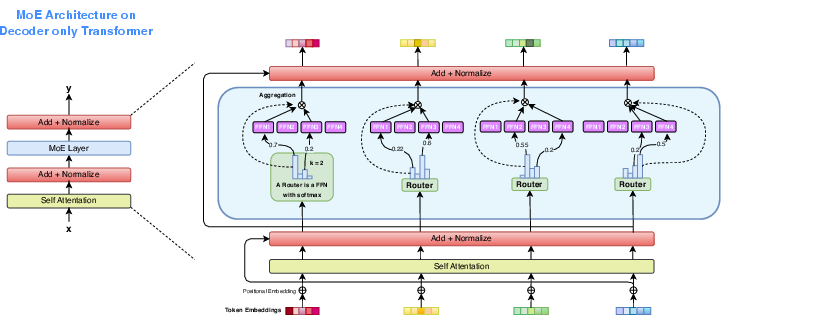
Figure 2: A brief illustration of sparsely gated Mixture of Experts (MoE) architecture on decoder only transformer. The gating function selects the two highest-scoring FFN experts for each token based on softmax probabilities.
Advanced variants such as Orthogonal MoE introduce orthogonality constraints to reduce redundancy in expert networks (Feng et al., 17 Jan 2025). Parameter-efficient tuning strategies update only a lightweight fraction of expert parameters, optimizing adaptation without retraining large-scale models.
Meta-learning capabilities enhance MoE systems by allowing rapid generalization across tasks and efficient knowledge transfer. Techniques such as meta-distillation adapt domain-specific experts for real-world tasks, while frameworks like MixER enhance modularity through nested gate designs.
In meta-learning setups, gates learn a routing policy across task distributions, supporting quick adaptation to unseen tasks via sparse expert outputs. This accelerates specialization and performance scaling for diverse scenarios (Nzoyem et al., 7 Feb 2025).
Applications and Domain-Specific Models
MoE architectures have transformed fields such as recommendation systems, healthcare, and computer vision. In recommendation systems, architectures like M3oE dynamically adjust expert composition based on evolving personalization targets.
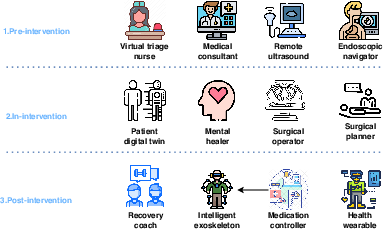
Figure 3: Applications of embedded AI in healthcare, utilizing embodied AI for pre-intervention, in-intervention, and post-intervention scenarios.
MoE designs including Med-MoE are increasingly vital in healthcare, aiding diagnostic reasoning while accommodating clinical constraints. For computer vision tasks, MoE models like Mixture of Calibrated Experts improve prediction robustness through calibrated confidence outputs (Oksuz et al., 2023).
Evaluations, Challenges, and Future Directions
Despite their advancements, MoE systems face challenges in evaluation and integration. A standardized modular framework, such as the MoE-CAP evaluation framework, is essential for benchmarking model accuracy, application performance, and deployment costs.
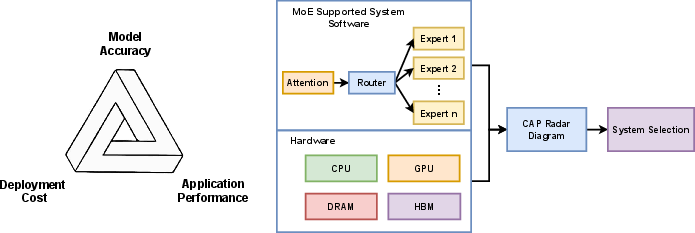
Figure 4: Framework illustration of MoE-CAP methodology, showcasing balanced considerations among deployment cost, model accuracy, and application performance.
Key challenges include expert specialization and routing stability, requiring continuous innovation in architectural and training mechanisms to improve expert differentiation and scalability.
Conclusion
The paper on Mixture of Experts in LLMs offers comprehensive insights into MoE architecture's evolution and application. MoEs challenge the prevailing assumptions about model scaling, providing efficient and adaptable solutions for large-scale AI development. The discussed innovations illustrate the potential paths for future research and real-world implementation.

