- The paper introduces a novel LLM multi-agent framework that integrates blackboard architecture to enable dynamic agent collaboration and token-efficient problem-solving.
- It employs iterative agent selection with diverse roles on both public and private blackboard spaces, achieving consensus on commonsense, reasoning, and mathematics tasks.
- Experimental results show LbMAS outperforms Chain-of-Thought methods by an average of 4.33% and static MASs by 5.02% while consuming fewer tokens.
Incorporating Blackboard Architecture into LLM Multi-Agent Systems
This paper introduces the blackboard architecture into LLM-based multi-agent systems (MASs) to enhance problem-solving capabilities. The proposed blackboard-based LLM multi-agent system (bMAS) enables agents with diverse roles to share information, facilitates agent selection based on the blackboard's content, and iterates the selection and execution process until a consensus is achieved. The paper implements a concrete bMAS, named LbMAS, and evaluates its performance on commonsense knowledge, reasoning, and mathematical datasets. The results demonstrate that LbMAS is competitive with state-of-the-art (SOTA) static and dynamic MASs, achieving comparable performance while utilizing fewer tokens.
Background and Motivation
LLM-based agentic systems have demonstrated significant achievements in various downstream tasks. LLM-based MASs aim to leverage collective intelligence to further improve problem-solving performance. Existing LLM-based MASs often employ fixed architectures with predefined agent roles and collaboration mechanisms, lacking generality and requiring manual construction. Dynamic MASs have emerged to address these limitations by configuring structures and communication strategies based on task and environment feedback. However, these systems often involve a time-consuming training step and may not cover all possible collaboration architectures. To address these challenges, the paper proposes incorporating the blackboard architecture into LLM-based MASs.
The Blackboard-based LLM Multi-Agent System (bMAS)
The bMAS framework comprises three core components: a control unit, a blackboard, and a group of LLM-based agents with different roles. The control unit selects agents to participate in the current problem-solving round based on the blackboard's content. Each selected agent takes the entire blackboard content as a prompt and writes its output back to the blackboard. This iterative process continues until a final solution is agreed upon.
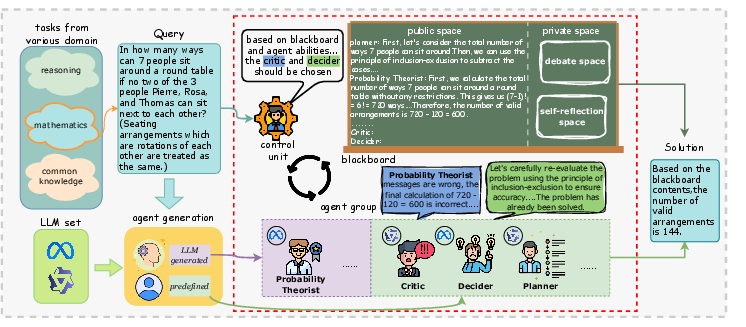
Figure 1: The general framework of bMAS, highlighting the core components and their interactions.
LbMAS Implementation
LbMAS, a concrete implementation of bMAS, includes query-related experts and constant agents such as planner, decider, critic, cleaner, and conflict-resolver. The LLMs for these agents are randomly selected from a set of LLMs at the start of the problem-solving process, promoting diversity. The blackboard is divided into public and private spaces, where the former is accessible to all agents and the latter is reserved for debates or verifications. Agents communicate solely through the blackboard, which acts as a public storage space, replacing the memory modules typically found in LLM agents. The control unit in LbMAS relies on an LLM agent to make selections for the given problem.
Experimental Evaluation
The performance of LbMAS was evaluated on a diverse set of benchmarks, including:
LbMAS was compared against several baselines, including:
The experimental results, summarized in Table 1 of the paper, demonstrate that LbMAS achieves competitive performance compared to both fixed and dynamic SOTA MASs, while also being token-economical. LbMAS outperformed CoT methods by an average of 4.33% and static methods by 5.02%. The decider and majority vote mechanisms yielded similar performance, indicating a consensus among agents in most cases.
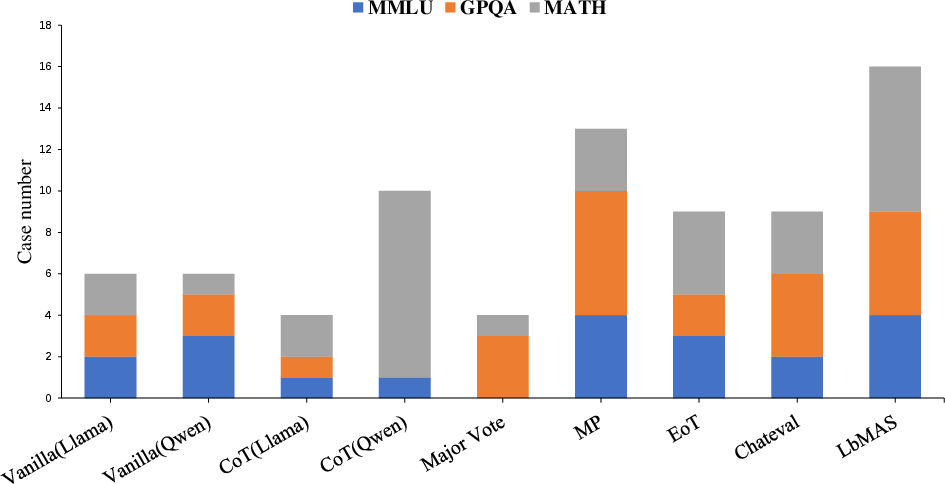
Figure 2: Visualization of the number of queries answered correctly by a single method, highlighting the unique problem-solving capabilities of each approach.
Cost Analysis
The token cost and performance of LbMAS were compared with static and autonomous MAS baselines on the MATH dataset. LbMAS achieved the second-lowest token consumption while maintaining strong performance. Autonomous MASs, which employ a two-step strategy of workflow optimization followed by problem-solving, incurred significantly higher token costs. LbMAS, on the other hand, dynamically adjusts agent selection and execution based on the blackboard content, eliminating the need for a supervised training step.
Case Studies
The paper includes case studies that illustrate the problem-solving process of LbMAS on queries of varying difficulty levels.
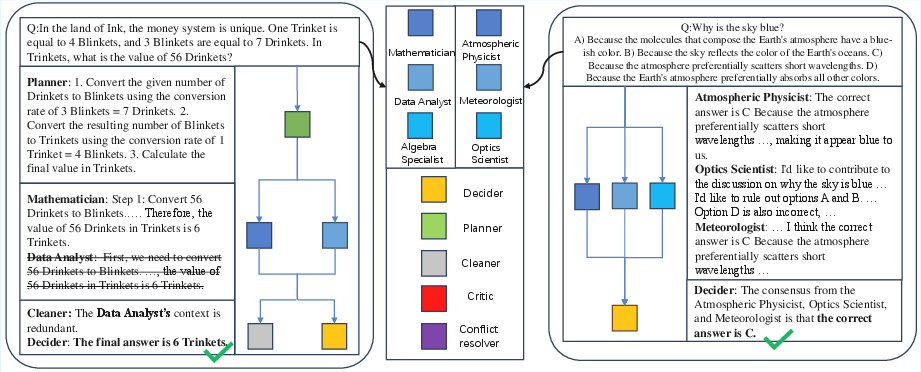
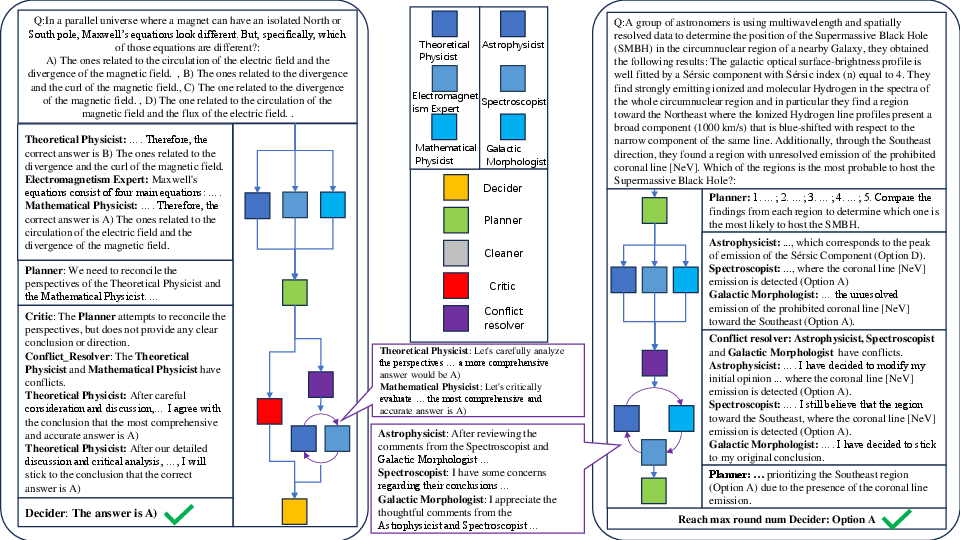
Figure 3: An example of LbMAS solving a problem, showcasing the agents' interactions and the evolution of the solution on the blackboard.
Ablation Studies
Ablation studies were conducted to assess the impact of the control unit and message removal on system performance. The control unit was found to significantly reduce token costs with minimal impact on performance, demonstrating the autonomy of LLM agents within LbMAS. Removing redundant messages through a cleaner agent was also shown to be crucial for maintaining the quality of information on the blackboard.
Prompts
The prompts used for agent generation, individual agents, and the control unit are described in detail.

Figure 4: An example agent prompt, highlighting the structure and content used to guide agent behavior.

Figure 5: Visualization of the agent-generation prompt used to create expert prompts based on the given query.

Figure 6: Structure of the control unit prompt, showcasing the input parameters and instructions for agent selection.
Max Consensus
The study analyzed the maximum number of agents having a consensus in three datasets, MMLU, GPQA, and MATH.
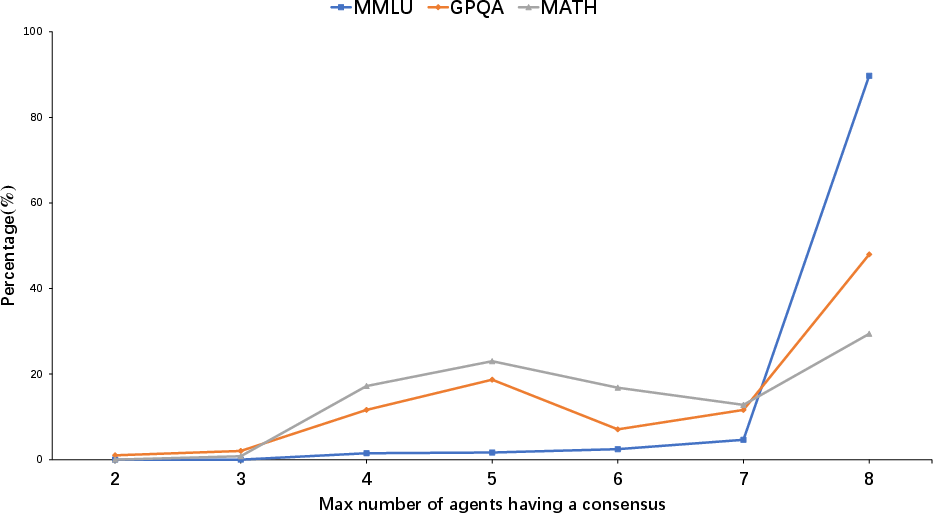
Figure 7: An example of the max number of agents having a consensus in three datasets.
Conclusions
The paper concludes by highlighting the potential of the blackboard-based LLM multi-agent framework for enabling dynamic and efficient problem-solving in scenarios where workflows are not well-defined. The authors believe that their proposal will contribute to the development of fully automated and self-organizing MASs.
Limitations and Future Work
The authors acknowledge limitations in the current implementation, including a limited number of predefined agent types and experiment benchmarks. Future work will focus on expanding the agent group, incorporating code writing and tool usage capabilities, and evaluating the framework on a wider range of datasets. The agent generation module will be enhanced to consider additional factors, such as the selection of suitable LLMs. Further exploration of the blackboard's role, including comparative experiments with shared memory pools and agent memory modules, is also planned.