- The paper introduces Text-to-LoRA, a hypernetwork that instantly generates LoRA adapters from natural language task descriptions for efficient transformer adaptation.
- It achieves near-lossless compression of hundreds of adapters and supports zero-shot generalization through both reconstruction and supervised fine-tuning methods.
- Experimental results demonstrate that T2L scales gracefully with increased tasks and compute, outperforming traditional methods while reducing FLOPs by over 4x.
Text-to-LoRA: Instant Transformer Adaptation via Hypernetworks
Introduction and Motivation
The "Text-to-LoRA: Instant Transformer Adaption" paper introduces a hypernetwork-based approach, Text-to-LoRA (T2L), for rapid, parameter-efficient adaptation of LLMs using only natural language task descriptions. The method addresses the inefficiency and rigidity of traditional fine-tuning and LoRA-based adaptation, which require per-task datasets, hyperparameter tuning, and significant compute. T2L leverages a hypernetwork to generate LoRA adapters in a single forward pass, conditioned on a text embedding of the task description, enabling both compression of many LoRA adapters and zero-shot generalization to unseen tasks.
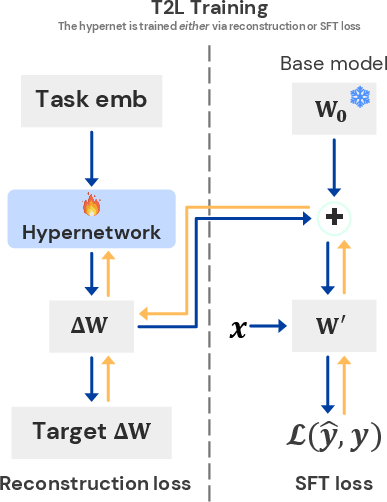
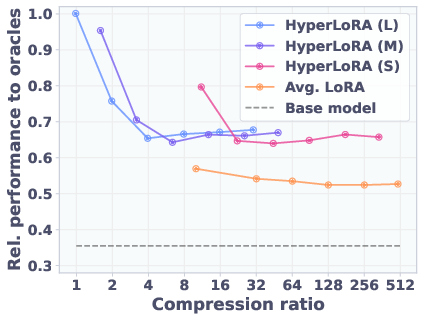
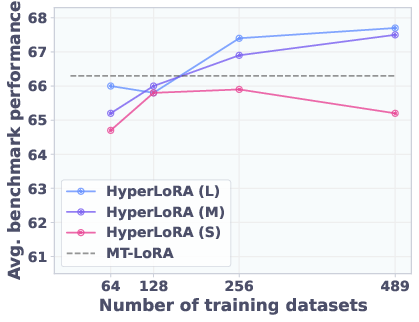
Figure 1: T2L training routine and scaling results. Left: T2L hypernetwork generates LoRA matrices from task description embeddings. Right: T2L performance scales with the number of pre-training datasets, both for compression and zero-shot generalization.
Methodology
Hypernetwork Architecture
T2L is a hypernetwork that, given a task description embedding, module type, and layer index, generates the low-rank LoRA matrices A and B for each target module and layer. The input to the hypernetwork is a concatenation of:
- f(zi): Embedding of the task description zi (e.g., via a sentence transformer or LLM).
- E[m]: Learnable embedding for module type (e.g., query/value projection).
- E[l]: Learnable embedding for layer index.
The hypernetwork outputs the LoRA weights ΔWm,li=hθ(ϕm,li) for each module/layer.
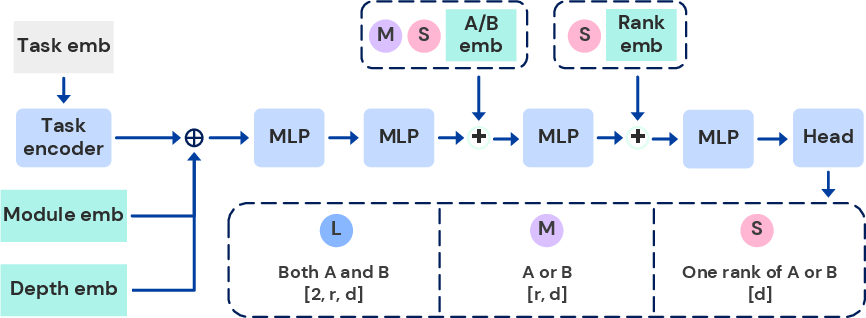
Figure 2: T2L architectural variants. Output head size and inductive bias vary across SteelBlue1!80 (largest), MediumPurple1!60 (medium), and Pink1 (most parameter-efficient).
Three architectural variants are explored:
- SteelBlue1!80: Outputs both A and B for all modules/layers in one pass; highest capacity.
- MediumPurple1!60: Shares output head between A and B; moderate capacity.
- Pink1: Outputs one rank of a low-rank matrix at a time; most parameter-efficient.
Training Schemes
Two training paradigms are considered:
- Reconstruction (Distillation): T2L is trained to reconstruct pre-trained LoRA adapters, minimizing L1 loss between generated and target LoRA weights. This enables compression of large LoRA libraries but does not generalize to unseen tasks unless task description embeddings are used.
- Supervised Fine-Tuning (SFT): T2L is trained end-to-end on downstream tasks, optimizing the SFT loss directly. This approach enables zero-shot generalization, as the hypernetwork learns to map task descriptions to effective LoRA adapters without explicit reconstruction targets.
Experimental Results
LoRA Compression
T2L achieves near-lossless compression of hundreds of LoRA adapters. When trained to reconstruct 9 benchmark-specific LoRAs, T2L matches or slightly exceeds the performance of the original adapters on their respective tasks. Notably, T2L outperforms the oracles on some benchmarks, likely due to regularization effects from lossy compression.
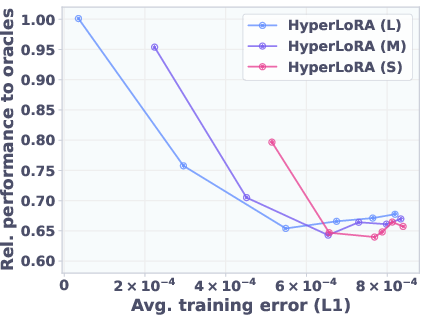
Figure 3: T2L performance and reconstruction error as the number of compressed tasks increases. Performance degrades gracefully as compression error increases.
As the number of compressed tasks increases, T2L maintains a significant fraction of oracle performance, with performance saturating even as reconstruction error grows.
Zero-Shot LoRA Generation
When trained via SFT on 479 SNI tasks, T2L can generate LoRA adapters for entirely unseen tasks using only a natural language description. On 10 diverse benchmarks (reasoning, math, coding, QA), SFT-trained T2L consistently outperforms multi-task LoRA and Arrow Routing baselines, and in some cases matches or exceeds task-specific LoRA performance.

Figure 4: Qualitative GSM8K examples. (i) Base model fails. (ii) Poor description yields poor LoRA. (iii, iv) Aligned descriptions yield correct answers with different reasoning paths, demonstrating T2L steerability.
T2L's adaptation is highly sensitive to the quality and alignment of the task description. Aligned descriptions yield correct and steerable outputs, while unaligned or random descriptions degrade performance.
Scaling and Ablations
- Scaling Training Tasks: Increasing the number of training tasks and compute budget improves zero-shot performance, especially for higher-capacity variants.
- Task Embedding Models: T2L is robust to the choice of embedding model (e.g., GTE vs. Mistral).
- Description Diversity: Using multiple, high-quality descriptions per task improves generalization.
- Training Scheme: SFT-trained T2L generalizes significantly better than reconstruction-trained T2L for unseen tasks.
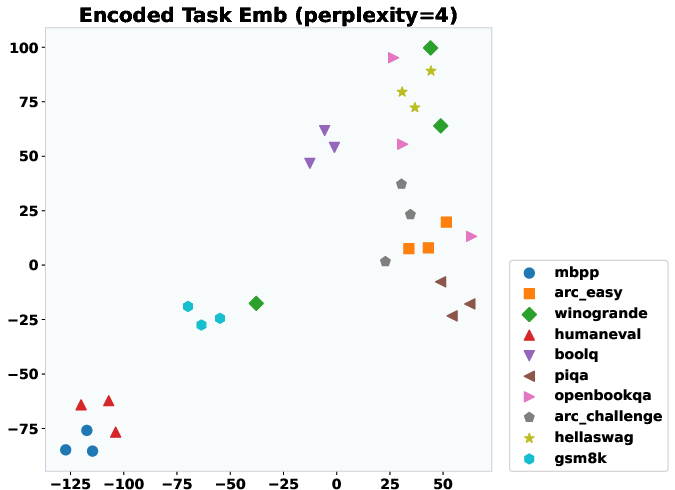
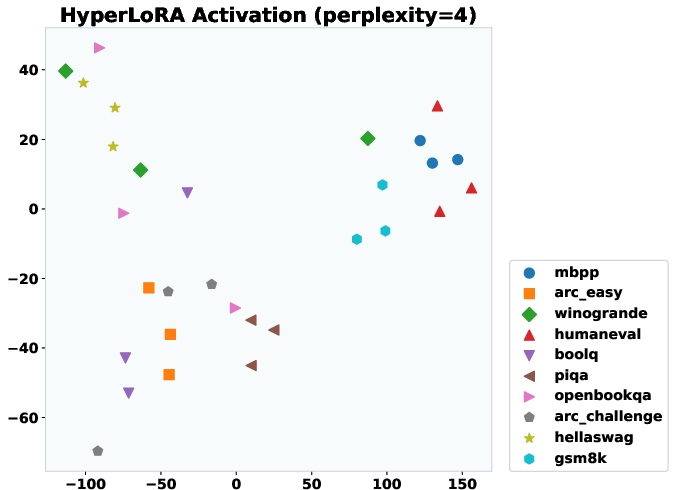
Figure 5: t-SNE projections of T2L activations. Clustering by task indicates T2L generates task-specific LoRAs for unseen tasks.
Analysis of Adapter Similarity
Adapters with similar task description embeddings perform similarly on benchmarks, but are not necessarily close in parameter space. This explains why reconstruction-trained T2L struggles to generalize: functionally similar adapters may be far apart in weight space, but SFT allows the hypernetwork to learn a more semantically meaningful mapping.
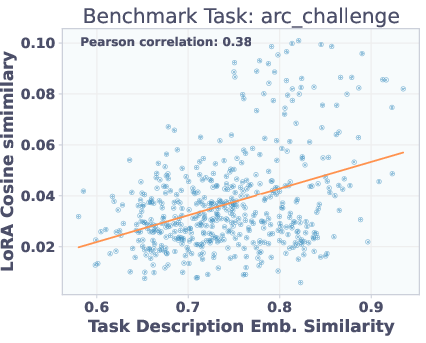
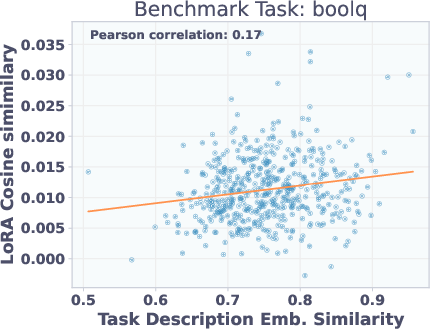
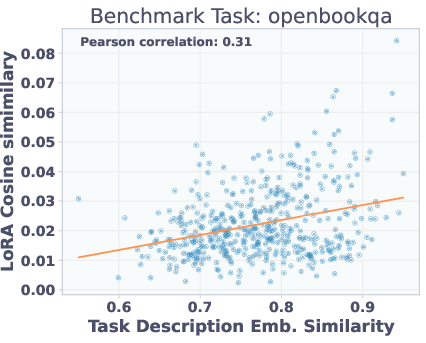
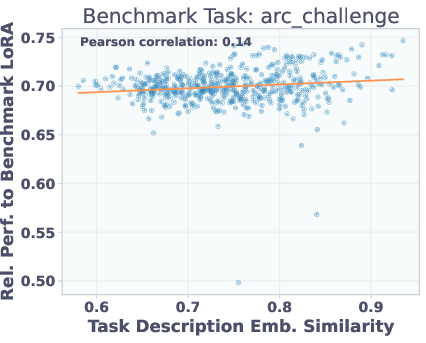
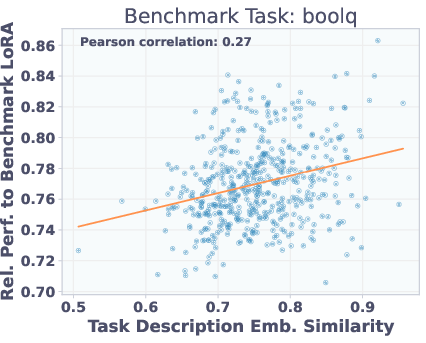
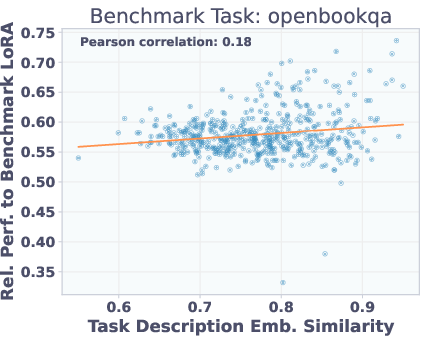
Figure 6: Top: Adapter similarity in weight space vs. description embedding space. Bottom: Adapter performance vs. description similarity. Functionally similar adapters are not close in parameter space, but description similarity predicts performance.
Implementation Considerations
- Resource Requirements: All T2L variants fit on a single H100 GPU (80GB VRAM). SFT requires more memory due to backpropagation through the base LLM.
- Adapter Generation: T2L generates all LoRA weights for a model in a single forward pass, enabling efficient deployment and fusion.
- Task Description Quality: Performance is highly sensitive to the quality and alignment of task descriptions. Automated generation via LLMs (e.g., GPT-4o) is recommended for consistency.
- Base Model Generality: T2L generalizes across LLM architectures (Mistral, Llama, Gemma) with the same hyperparameters.
- FLOPs Efficiency: T2L adaptation is significantly more compute-efficient than in-context learning, with >4x reduction in FLOPs per instance.
Practical and Theoretical Implications
T2L demonstrates that hypernetworks can serve as a universal adapter generator for LLMs, compressing large libraries of LoRA adapters and enabling instant, text-driven adaptation. This approach democratizes LLM specialization, allowing non-experts to adapt models via natural language. The method also provides a new lens for studying the geometry of adapter spaces and the relationship between task semantics and parameterization.
Theoretically, the results suggest that the space of effective LoRA adapters is highly redundant and can be efficiently parameterized by a hypernetwork conditioned on semantic task information. However, the lack of alignment between functional similarity and parameter proximity in LoRA space highlights the limitations of reconstruction-based approaches and motivates further research into more semantically structured adapter spaces.
Limitations and Future Directions
- Description Sensitivity: T2L's performance degrades with poor or misaligned task descriptions. Robustness to user-generated descriptions remains an open challenge.
- Adapter Output Space: Only LoRA adapters are considered; direct modulation of activations or other adaptation mechanisms may yield further gains.
- Zero-Shot Ceiling: While T2L narrows the gap, it does not fully match task-specific LoRA performance in zero-shot settings.
- Transfer to Larger Models: The transferability of T2L trained on smaller models to larger architectures is unexplored.
Future work should investigate more robust task embedding strategies, alternative adapter parameterizations, and broader application domains (e.g., vision-LLMs). Additionally, integrating user feedback or automated description refinement could further enhance real-world usability.
Conclusion
Text-to-LoRA (T2L) establishes a new paradigm for instant, text-driven adaptation of LLMs via hypernetworks. By mapping natural language task descriptions to LoRA adapters, T2L enables efficient compression, rapid deployment, and strong zero-shot generalization. The approach is practical, scalable, and model-agnostic, with significant implications for democratizing LLM specialization and understanding the structure of adaptation spaces. While challenges remain in robustness and zero-shot optimality, T2L provides a compelling foundation for future research in hypernetwork-based model adaptation.