- The paper introduces PGPO, which uses structured P-code Plans to enhance agents' reasoning and generalization beyond task-specific natural language planning.
- It details a pipeline that converts ReAct-style thought processes into pseudocode, reducing action errors and boosting overall efficiency in LLM agents.
- Experimental evaluations show an average performance gain of 11.6% across benchmarks, highlighting PGPO's effectiveness in minimizing overfitting and improving reasoning on unseen tasks.
Enhancing Agent Reasoning via Pseudocode-style Planning
Introduction
The paper "PGPO: Enhancing Agent Reasoning via Pseudocode-style Planning Guided Preference Optimization" (2506.01475) introduces a novel approach to improve the reasoning capabilities of LLM agents. Traditional methods rely heavily on natural language (NL) plans, which often suffer from verbosity and task specificity, limiting the generalizability of agents to unseen tasks. This research proposes the use of pseudocode-style plans, referred to as P-code Plans, to encode the structural logic of reasoning. These structured plans enhance generalization and efficiency, important for scalable and reliable agent development.
Pseudocode-style Planning
P-code Plans represent abstracted planning steps akin to functions in programming, using identifiers, parameters, and optional return values and control flows. This abstraction captures generalizable task knowledge, crucial for enhancing out-of-distribution capabilities.
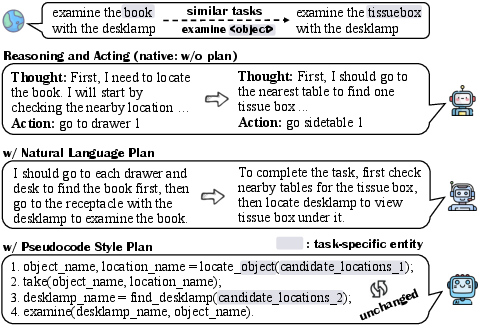
Figure 1: An example demonstrating why P-code Plan helps LLM agents generalize well. When faced with similar tasks, the thought process can be recycled through P-code Plans.
The paper details a robust pipeline to generate P-code Plans: extracting thoughts from ReAct-style datasets, summarizing into high-level plans using GPT-4o, and structuring these into pseudocode. This structured format facilitates efficient reasoning processes and promotes agent generalization to unseen tasks, as evidenced by improved average rewards across benchmarks when compared with NL planning formats.
PGPO Methodology
Building on the insights from P-code Plans, the paper introduces the Pseudocode-style Planning Guided Preference Optimization (PGPO) method. PGPO aims to optimize agent learning by iteratively refining planning capabilities through explicit preference optimization. This involves two key steps: constructing contrastive trajectory datasets based on two designed rewards—plan-driven and plan-following—and employing a preference optimization framework to update agent planning abilities.
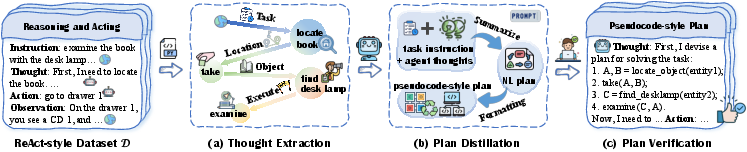
Figure 2: Overview of P-code Plan generation pipeline.
The results demonstrate significant improvement in agent performance. PGPO achieved a relative 11.6% performance gain averaged across three representative agent benchmarks, notably outperforming existing strong baselines by reducing action errors and omissions during reasoning.
Experimental Evaluation
The efficacy of PGPO was validated across four LLMs on datasets like ALFWorld and WebShop. Notably, PGPO led to better generalization on unseen tasks, confirming its ability to leverage abstract plans for broader reasoning tasks. The study emphasizes that concise, structured plans not only enhance reasoning efficiency (requiring fewer interactions) but also mitigate overfitting, which is common with verbose NL plans.
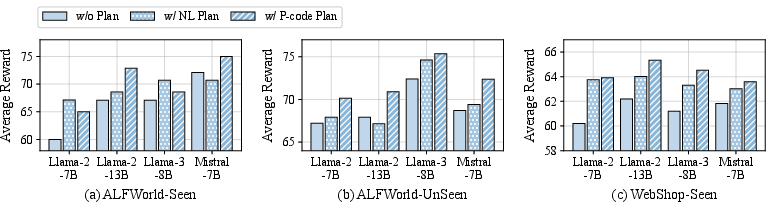
Figure 3: Comparison between w/ P-code Plan and w/o Plan, w/ NL Plan during the SFT process for LLM agents.
Implications and Future Work
The development of PGPO signifies a shift towards more structured, efficient planning paradigms in AI, prioritizing generalization and effective task guidance. Future research could extend PGPO's applicability to multi-task domains and explore automated verification methods for generated plans, a critical step towards reducing manual intervention in plan generation.
In conclusion, this paper contributes a significant advancement in the field of AI planning by demonstrating the power of pseudocode-style plans in enhancing agent reasoning capabilities, marking a vital step forward in creating scalable, generalizable AI systems.
