- The paper presents a novel geometric framework (Safety Polytope) that enforces safety constraints in LLMs without modifying model weights.
- It employs a Concept Encoder to disentangle semantic safety attributes, enhancing interpretability and reducing polysemanticity.
- Experimental results show significant reductions in adversarial attack success rates while maintaining standard task performance.
Learning Safety Constraints for LLMs
Introduction
The paper "Learning Safety Constraints for LLMs" (2505.24445) introduces a novel approach to enhancing the safety of LLMs, addressing their vulnerabilities to generating harmful outputs and susceptibility to adversarial attacks. This approach, termed the Safety Polytope (SaP), leverages a geometric framework to enforce safety constraints within the model's representation space, thereby offering a robust and interpretable mechanism for ensuring LLM safety without altering the model's weights.
Geometric Framework and Safety Polytope
The core proposition of the paper is the application of a geometric perspective to model safety, treating it akin to a constraint learning problem within constrained Markov decision processes (CMDPs). The Safety Polytope approach operates by identifying safe and unsafe regions in the model's representation space, defined as a polytope whose facets correspond to various safety constraints.
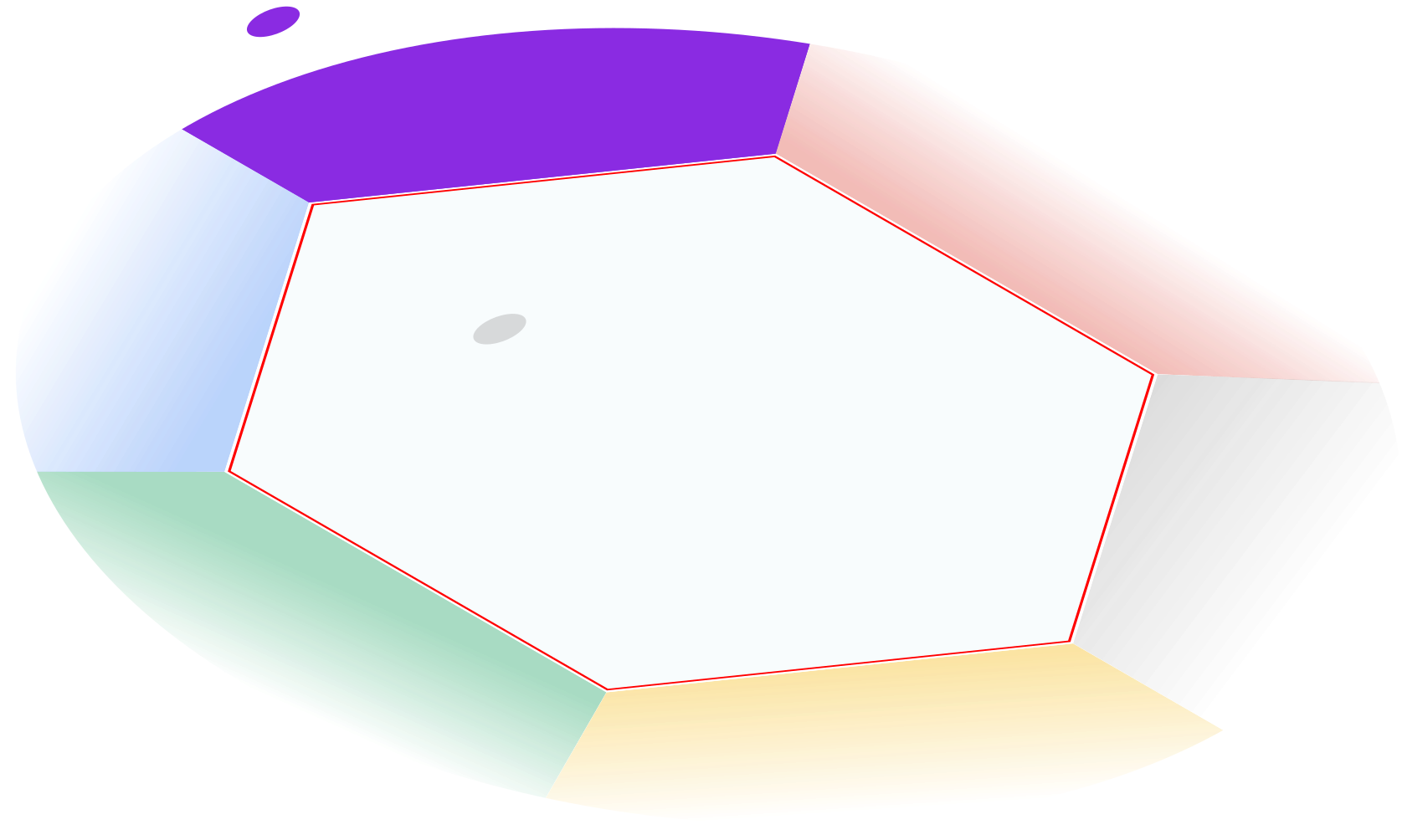
Figure 1: Illustration of the geometric approach to LLM safety proposed in this paper. A safety facet is triggered when a user asks the model to write a response suggesting fabricated content. When the model generates responses, we steer its internal representation back to the safe region to produce safe outputs.
By framing the model's decision-making as a sequential process subject to constraints, it allows for the detection and correction of unsafe outputs via post-hoc geometric steering. This process is distinct from other safety methodologies as it operates independently of modifications to model parameters, maintaining the LLM's original capabilities.
Experimental Evaluation and Results
The paper presents an extensive experimental analysis demonstrating the efficacy of the Safety Polytope across multiple LLM benchmarks. The approach effectively reduces the attack success rates significantly while maintaining model performance on standard tasks, thereby highlighting its utility in practical scenarios.
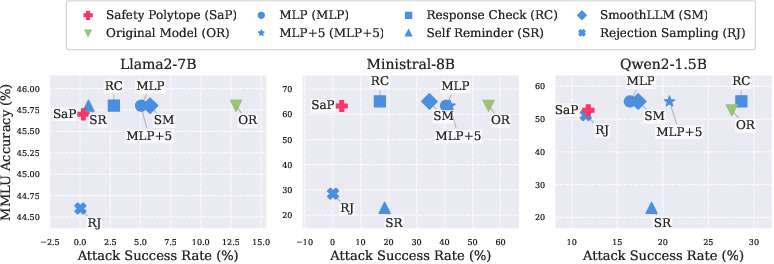
Figure 2: Comparison of model MMLU accuracy and average Attack Success Rate (ASR) on 9 attack algorithms. All defense methods are evaluated over 5 seeds. consistently retains the original MMLU accuracy while having significantly lower ASR compared to most baseline methods.
An impressive feature of the Safety Polytope is its robustness against various adversarial attacks, illustrated by a stark reduction in attack success rates across models like Llama2-7B, Ministral-8B, and Qwen2-1.5B. The use of a Concept Encoder further amplifies the model's defensive capabilities by disentangling semantic concepts related to safety, thus offering a more focused and reliable safety mechanism.
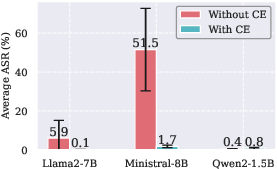
Figure 3: Comparison of average ASR for each model, with and without Concept Encoder (CE). With CE consistently shows robustness against attack across models.
Interpretability and Facet Analysis
A significant advancement highlighted in the paper is the interpretability derived from the geometric model. Through mutual information heatmaps and KL divergence analyses, the study reveals that safety facets learned through the proposed framework show distinct specialization in detecting various semantic safety concepts.
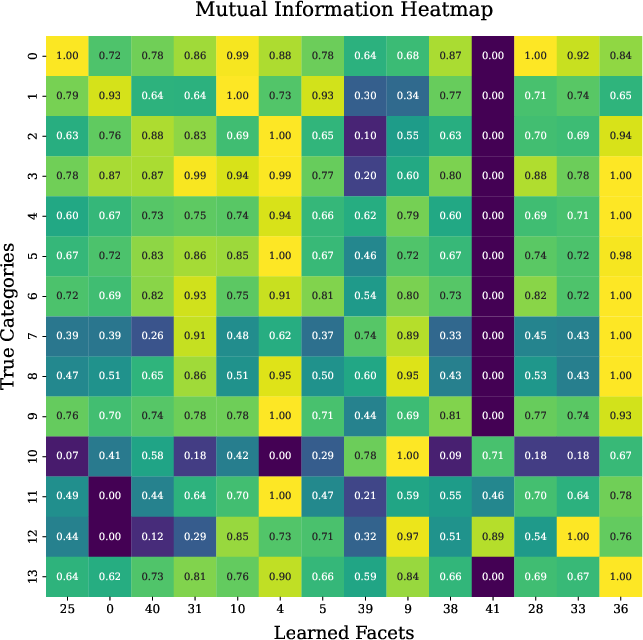
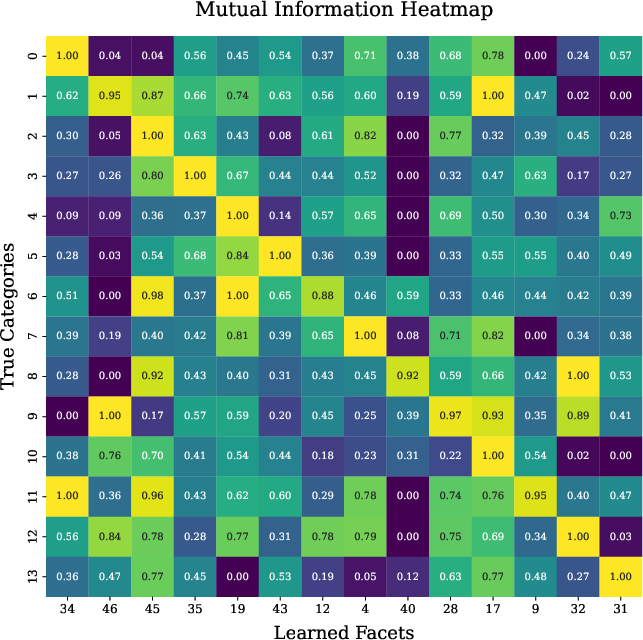
Figure 4: Mutual Information Heatmap showing the comparison between models without (a) and with Concept Encoder (b). Polytope facets learned with a concept encoder show more disentangled activations in safety classes.
The introduction of a Concept Encoder aids in reducing polysemanticity in the learned facets, thereby enhancing the interpretability and precision of safety constraints. This feature not only contributes to improved model safety but also provides a transparent method for understanding the activation patterns within the model concerning specific safety categories.
Implications and Future Directions
This geometric approach to LLM safety has notable implications for the development and deployment of AI systems. By offering a means to enforce safety constraints without continually adapting model parameters, it provides a scalable and efficient methodology for post-deployment safety assurance. Additionally, the interpretability of learned constraints supports transparency and accountability in AI safety applications.
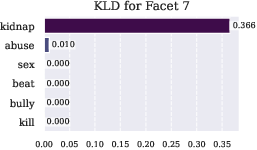
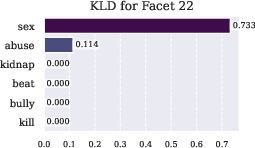
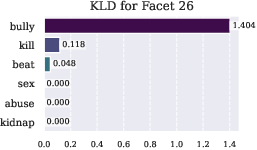
Figure 5: KL divergence analysis revealing semantic specialization of 's facets. Higher values indicate stronger activation when masking specific context words, demonstrating how each facet learns to detect distinct categories of harmful content rather than broadly negative terms.
Future research directions could explore further decomposition of geometric constraints to gain deeper insights into semantic safety understanding. Moreover, adapting these methods to address broader AI safety challenges could enhance their utility across diverse AI applications.
Conclusion
The "Learning Safety Constraints for LLMs" paper sets forth a promising framework for enhancing the safety of LLMs via geometric constraints. This framework not only strengthens defense mechanisms against adversarial attacks but also maintains model capabilities and interprets safety in a manner aligned with human semantics. The advancement marks a significant step towards safe, reliable, and interpretable AI systems.