AgentSGEN: Multi-Agent LLM in the Loop for Semantic Collaboration and GENeration of Synthetic Data
Abstract: The scarcity of data depicting dangerous situations presents a major obstacle to training AI systems for safety-critical applications, such as construction safety, where ethical and logistical barriers hinder real-world data collection. This creates an urgent need for an end-to-end framework to generate synthetic data that can bridge this gap. While existing methods can produce synthetic scenes, they often lack the semantic depth required for scene simulations, limiting their effectiveness. To address this, we propose a novel multi-agent framework that employs an iterative, in-the-loop collaboration between two agents: an Evaluator Agent, acting as an LLM-based judge to enforce semantic consistency and safety-specific constraints, and an Editor Agent, which generates and refines scenes based on this guidance. Powered by LLM's capabilities to reasoning and common-sense knowledge, this collaborative design produces synthetic images tailored to safety-critical scenarios. Our experiments suggest this design can generate useful scenes based on realistic specifications that address the shortcomings of prior approaches, balancing safety requirements with visual semantics. This iterative process holds promise for delivering robust, aesthetically sound simulations, offering a potential solution to the data scarcity challenge in multimedia safety applications.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Below is a single, actionable list of the paper’s knowledge gaps, limitations, and open questions that future work could address:
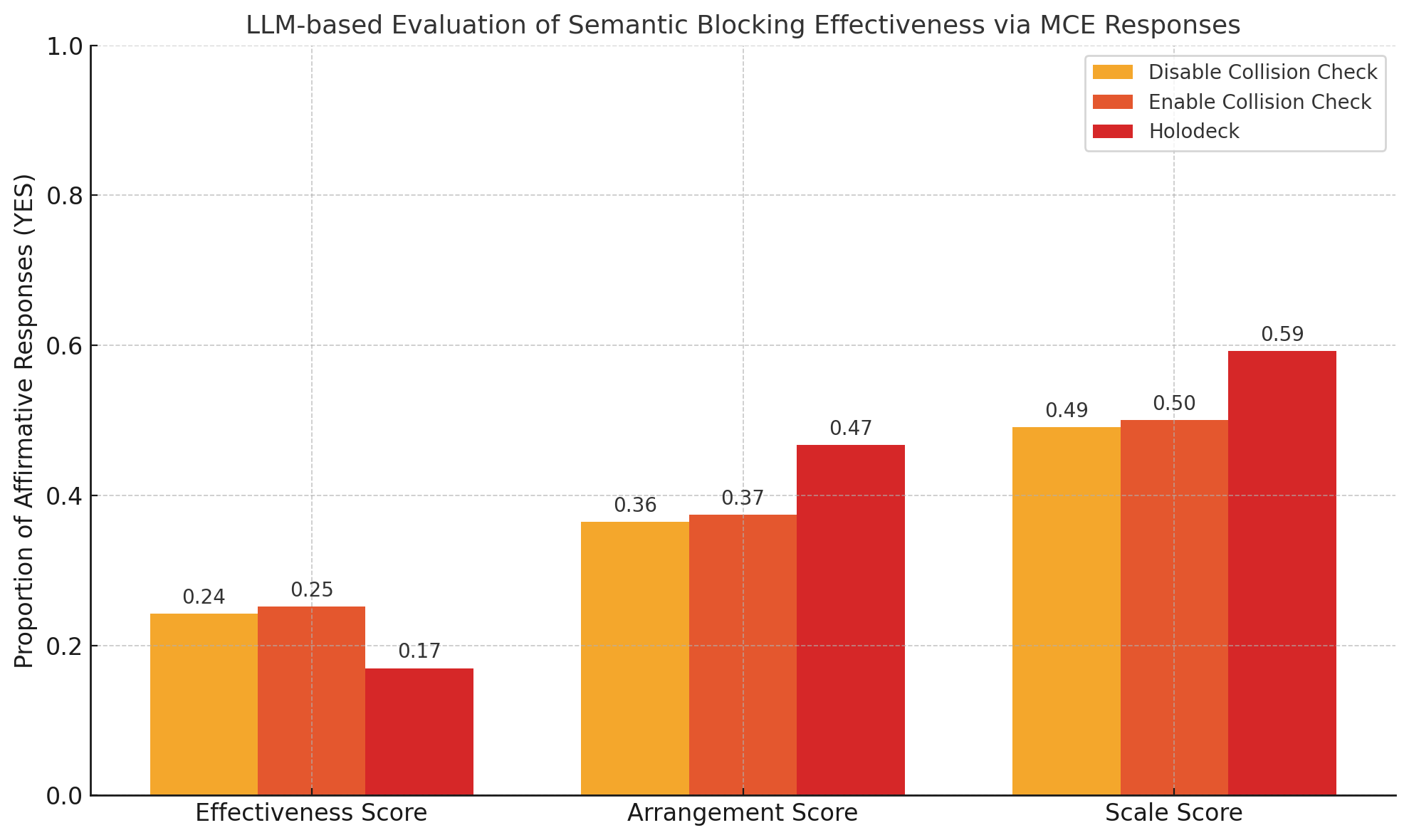
- No geometry-based, quantitative metric for “blocked exit” verification (e.g., door occlusion percentage, clearance thresholds, navigability/path existence via navmesh or shortest-path to exits).
- Missing formal handling of constraint conflicts (e.g., intentionally blocking exits vs. maintaining safety rules): define hard/soft constraints, priorities, and explicit conflict-resolution policies with explainability.
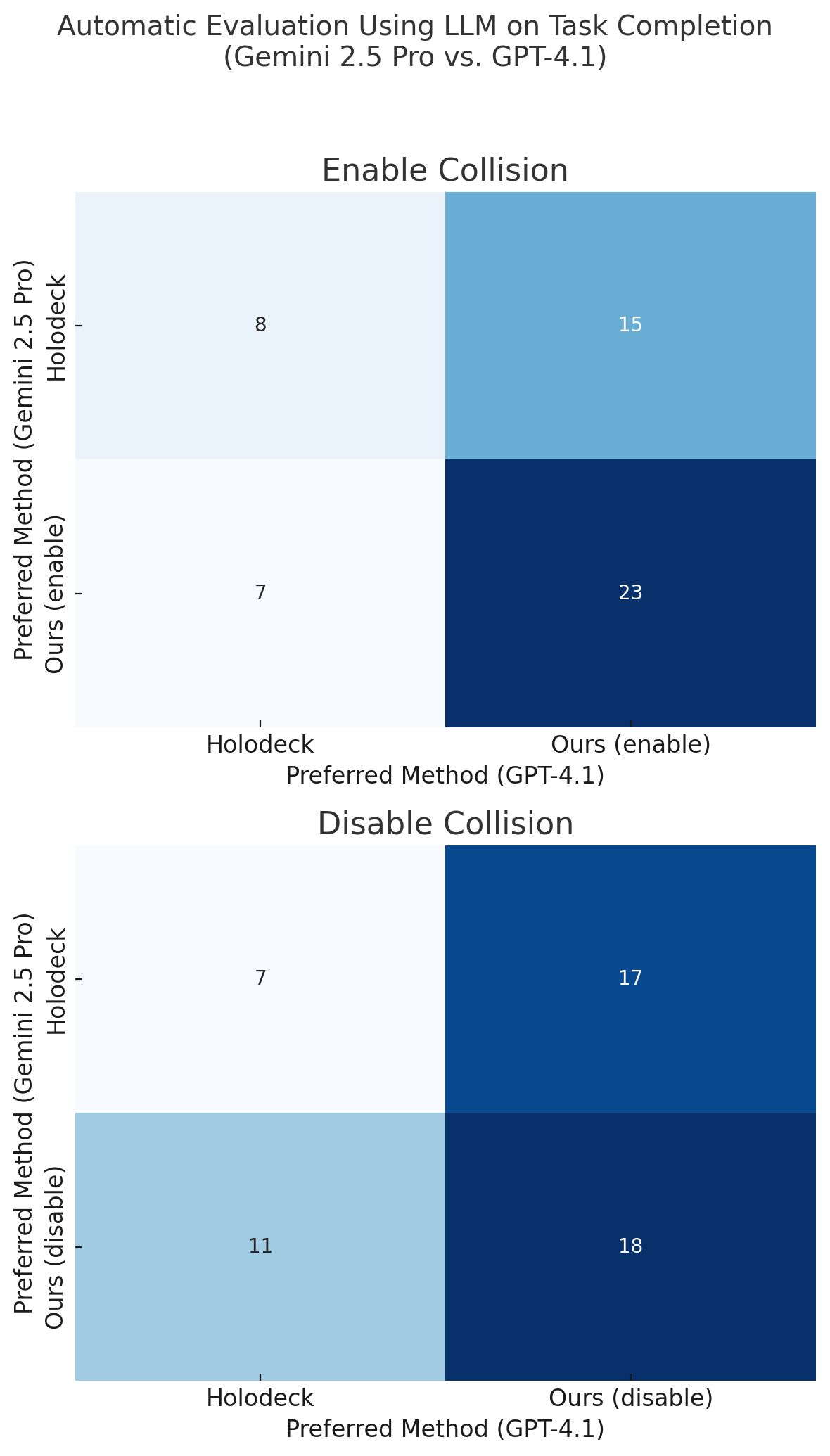
- Lack of ablation studies to justify the dual-agent design: compare against single-agent baselines, different role splits, or planner-only/executor-only configurations to quantify gains in accuracy, speed, and stability.
- Limited baseline comparisons: evaluate against scenario languages (e.g., Scenic), alternative LLM-guided 3D pipelines, and controllable generation systems (ControlNet, GLIGEN, Infinigen editing) under identical goals.
- Scalability and cost unreported: measure and report iteration counts, token usage, runtime per scene, throughput, failure rates, and convergence statistics across scene complexity levels.
- Generalization beyond “blocked doors” is untested: extend to diverse safety-critical scenarios (trip hazards, fall protection, hazardous materials placement, equipment collisions, structural instability, poor lighting).
- Physics realism is minimal (AABB only): incorporate rigid-body physics, gravity, friction, stability, contact constraints, and collision resolution to avoid visually plausible but physically impossible placements.
- Egress and human movement validation absent: assess evacuation feasibility (e.g., egress time, path widths, bottlenecks) using agent-based simulation or code-compliant path-planning.
- Dataset release details are unclear: specify size, splits, diversity across room types, asset licenses, metadata schema, and reproducibility artifacts; commit to public availability and versioning.
- Reproducibility is under-specified: pin LLM models/versions, prompts, seeds, temperatures, and code; provide end-to-end scripts to reproduce scenes and evaluations.
- Robustness to prompt variation and adversarial phrasing is not assessed: perform sensitivity analyses across paraphrases, ambiguous goals, and multi-objective prompts.
- LLM dependency risks (hallucination, bias, non-determinism) are not mitigated: add guardrails (self-consistency checks, verifier modules, tool-augmented reasoning) and audit failure/edge cases.
- Editor action space is inconsistently described: clarify and evaluate the need for operations beyond move/rotate/delete (e.g., add objects, scale, material changes) and their impact on task success.
- 2D projection-centric reasoning may miss 3D constraints: quantify errors from using top-down views (stacking, occlusion, vertical clearances, multi-level spaces) and explore full 3D reasoning.
- Automatic LLM evaluation is biased toward aesthetics: devise calibrated, goal-conditioned evaluators or non-LLM metrics; study prompt-order effects and reliability across models.
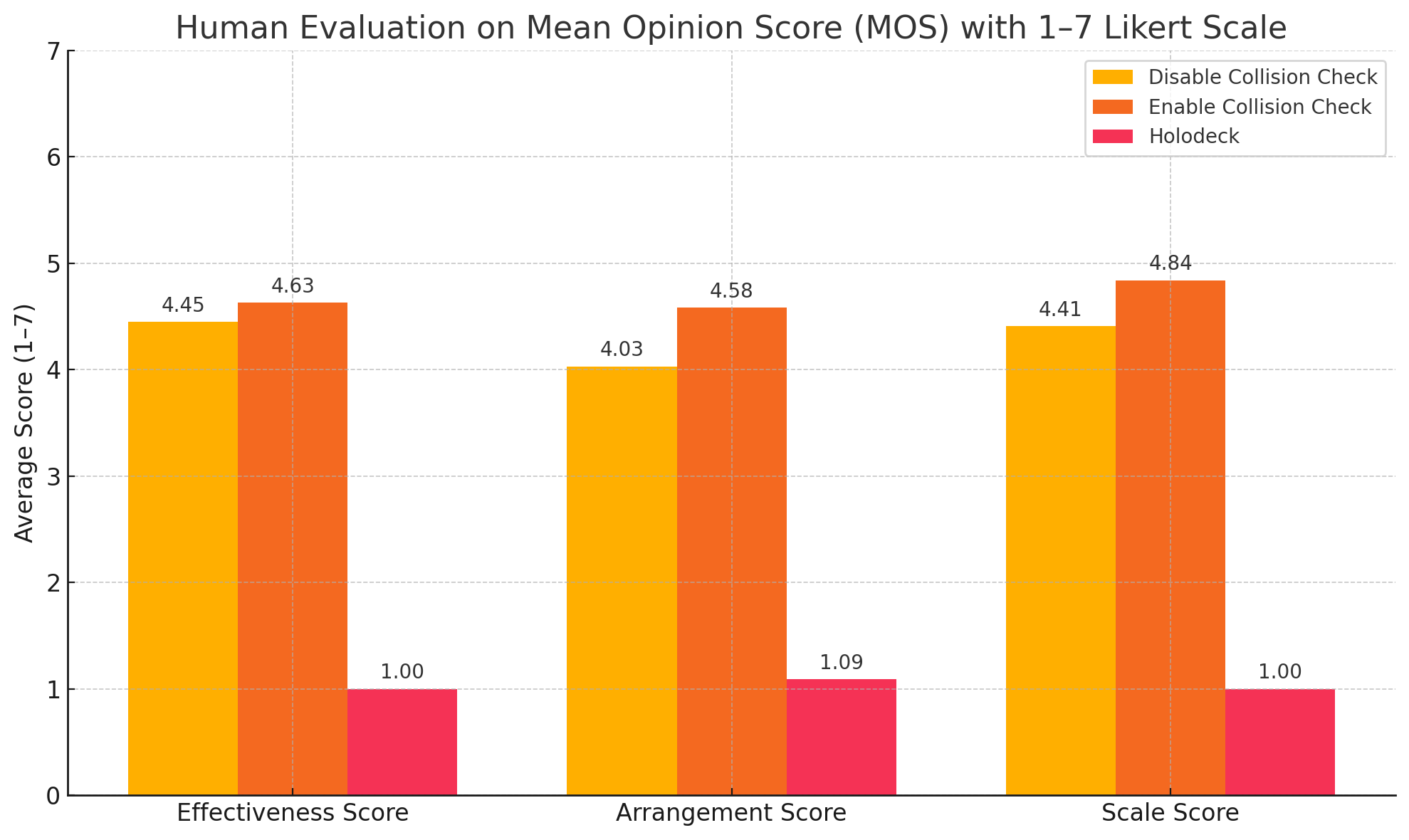
- Realism and aesthetic quality lack objective metrics: include perceptual realism measures, structural regularity metrics, or larger-scale human preference tests with varied demographics.
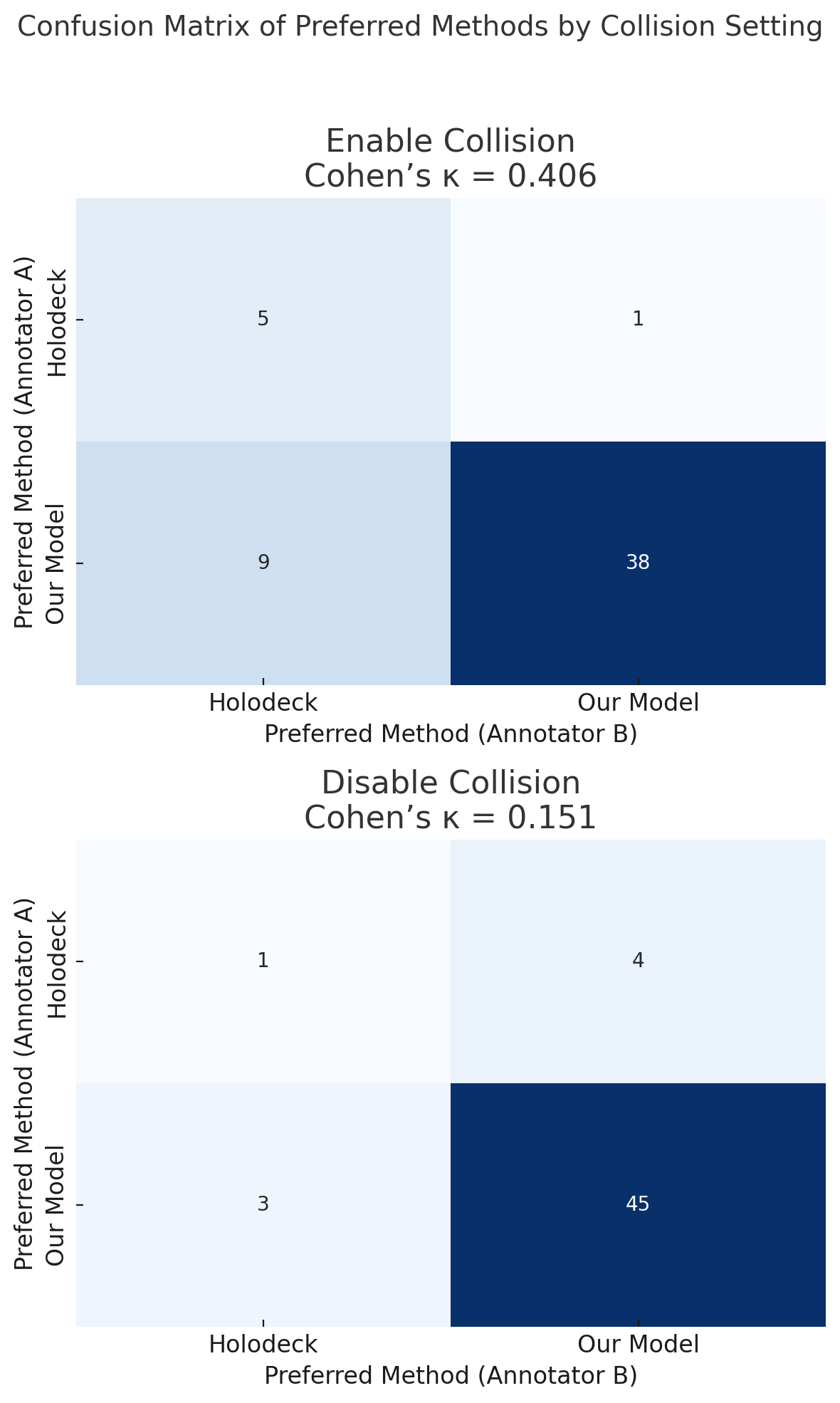
- No policy for when to toggle collision checking: learn or define criteria to switch modes based on goals, ensuring realism while achieving semantic constraints.
- Engine and asset generalization is untested: validate across AI2-THOR, Habitat, Unity, Unreal, different asset libraries, and domain gaps (e.g., BIM-linked assets).
- Downstream utility is not demonstrated: show that the synthetic data improves training of detectors/segmenters (e.g., blocked-exit detection) with mAP/F1/IoU on real-world benchmarks.
- Constraints are not formally guaranteed: integrate CSP/SMT solvers or optimization backends with LLM planning to provably satisfy constraints; provide correctness checks and certificates.
- Human evaluation scale and expertise are limited: recruit more annotators, include safety/code experts, report inter-rater reliability at scale, and analyze expertise effects on judgments.
- Failure modes are not characterized: catalog cases where scenes appear blocked but remain traversable; analyze common error patterns and implement automatic detection/remediation.
- Token/context scaling issues are unaddressed: propose compact scene graph encodings, hierarchical prompting, or retrieval to handle large-object scenes within LLM context limits.
- No uncertainty or confidence reporting: add quantitative confidence scores for constraint satisfaction, plan validity, and execution outcomes; expose introspective signals for auditing.
- Ethical and cultural realism considerations are missing: assess whether generated hazards could mislead or reinforce biases; ensure responsible release and usage guidelines.
- Temporal dynamics are ignored: extend to time-varying hazards, multi-step scenario evolution, and evacuation simulations to evaluate dynamic safety violations.
- Annotation fidelity is assumed: validate the correctness of segmentation/masks/depth/metadata against scene graphs; measure label noise and its impact on downstream models.
- Alternative multi-agent collaboration modes are unexplored: compare cooperation, competition, role reassignment, and team optimization (e.g., DyLAN) for performance and robustness.
- Visual feedback design is not evaluated: measure the impact of different render modalities (top-down, multi-view, overlays, trajectories) on agent performance and error reduction.
- Termination criteria and convergence guarantees are unspecified: define stopping rules, maximum iterations, and theoretical/empirical convergence properties under varied constraints.
- Domain-specific safety knowledge is not formalized: integrate building codes (e.g., NFPA, OSHA), represent them symbolically, and test compliance; assess cross-region code generalization.
- Multi-objective composition is unexplored: develop mechanisms to satisfy multiple, potentially conflicting goals (e.g., blocked main exit but clear secondary exit, accessibility constraints) with tunable trade-offs.
Collections
Sign up for free to add this paper to one or more collections.

