- The paper presents a novel multi-agent framework that automates the construction of anomaly detection pipelines from natural language instructions.
- It employs specialized agents for tasks such as intent interpretation, code generation, and model selection, achieving high pipeline success rates across various libraries.
- The system leverages short-term and long-term memory for efficient information retrieval, reducing latency and operational costs significantly.
AD-Agent: A Multi-agent Framework for End-to-end Anomaly Detection
AD-Agent is introduced as a multi-agent framework driven by LLMs designed to automate the construction of anomaly detection (AD) pipelines from natural language instructions. This framework addresses the significant challenge of integrating diverse data modalities and specialized AD libraries, making it accessible for non-experts who lack deep programming skills.
Introduction and Methodology
Anomaly detection remains crucial in various industries, including fraud detection and network monitoring, but is hampered by the complexity and diversity of data modalities. AD-Agent aims to bridge this gap by utilizing LLM capabilities for reasoning, code generation, and tool utilization to automate complex, multi-stage AD tasks.

Figure 1: Illustration of AD-Agent: given a user request, the multi-agent system coordinates each stage to generate a runnable pipeline.
AD-Agent leverages a modular and extensible design, composed of specialized agents including Processor, Selector, Info Miner, Code Generator, and Reviewer. These agents execute distinct subtasks such as user intent interpretation, data processing, library and model selection, information retrieval, code generation, and validation. Additional optional agents, Evaluator and Optimizer, expand the system's capabilities for performance assessment and hyperparameter tuning.
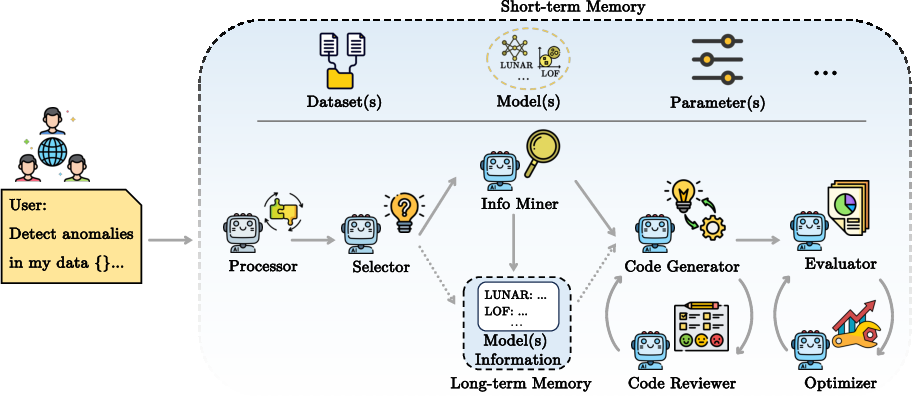
Figure 2: Flowchart of AD-Agent. Users input natural language instructions and data from various modalities. AD-Agent coordinates multiple LLM-powered agents via short-term and long-term memory to construct anomaly detection pipelines. Solid arrows represent the default workflow; dashed arrows indicate an optional path that bypasses web searches when algorithm information is stored in long-term memory.
Two memory components, a shared short-term memory for task coordination and a long-term cache for storing information, facilitate interaction among agents and optimize the process by minimizing repetitive queries.
Experimental Evaluation
AD-Agent's performance was evaluated in terms of reliability, code execution success rate, model selection quality, and efficiency in information retrieval.
Pipeline Generation
AD-Agent exhibited high reliability, achieving a pipeline success rate of 100% for PyOD, 91.1% for PyGOD, and 90.0% for TSLib across multiple dataset-model combinations, demonstrating its capability to handle diverse data modalities with minimal latency and cost.
While the collaborative feedback loop between the Code Generator and Reviewer agents effectively handled errors during initial code generation, some 'failure modes' were still observed. These included incorrect parameter assignments and unrecognized import names, suggesting areas for improvement in data validation and library consistency handling.
AD-Agent's model selection efficacy was assessed using the o4-mini LLM, with three queries per dataset to derive model recommendations. The approach surpassed average baseline performance and approximated the best model performance on most datasets for both PyOD and PyGOD libraries.
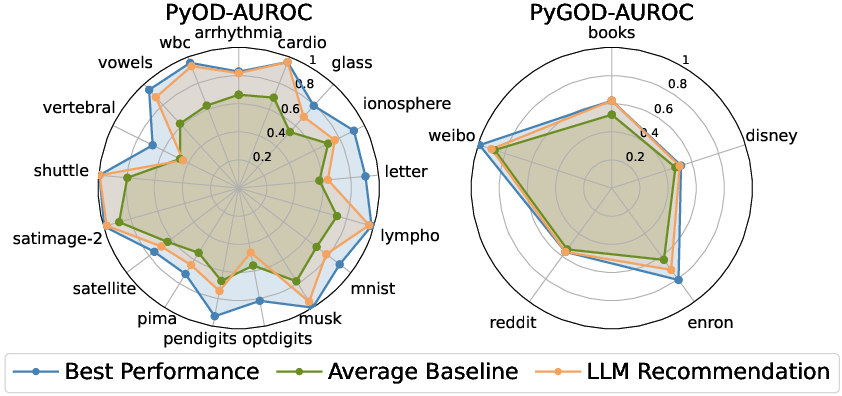
Figure 3: Model selection results for PyOD and PyGOD. We display the average AUROC of models recommended by querying the reasoning LLM three times (duplicates allowed). "Best Performance" marks the highest performance achieved by any available model for each dataset, while "Average Baseline" denotes the mean performance across all available models.
AD-Agent's use of LLMs for context-aware model selection showcases its potential to aid users without deep understanding in this task.
Long-term Memory Efficiency
The long-term memory component significantly reduces the operational overhead by storing model information from the Info Miner. Instances where long-term memory was utilized showed nearly instantaneous information retrieval compared to the 10-second average latency of a typical web search, emphasizing the efficiency gains and reduced costs.
Conclusion
AD-Agent sets forth a significant advancement in automating anomaly detection by leveraging LLM-driven multi-agent collaboration. It successfully generates executable pipelines, efficiently selects competitive models, and utilizes long-term memory to enhance retrieval efficiency, making it a valuable tool for both research and practical applications. The open-source release offers a platform for wider community engagement in LLM-driven AD research.
In future work, expanding the framework to support new data modalities and incorporating real-time conversational interactions for dynamic pipeline adjustments are proposed directions. Additionally, a secure, cost-aware cloud-based environment may further enhance user accessibility and convenience, contributing to an expanding ecosystem of open-source AD tools.