- The paper’s main contribution is the introduction of a depth-aware hybrid feature fusion method that dynamically adjusts LiDAR-camera integration for enhanced 3D object detection.
- It presents two modules, Depth-GFusion and Depth-LFusion, which incorporate depth encoding to improve both global and local feature fusion while adapting to varying depth ranges.
- Experimental results on the nuScenes and KITTI datasets demonstrate superior detection accuracy, robustness under corruptions, and competitive computational efficiency.
DepthFusion: Depth-Aware Hybrid Feature Fusion for LiDAR-Camera 3D Object Detection
The paper "DepthFusion: Depth-Aware Hybrid Feature Fusion for LiDAR-Camera 3D Object Detection" presents a novel approach to enhance 3D object detection by considering the depth factor explicitly in the fusion of LiDAR and camera data. This method aims to leverage the complementary strengths of LiDAR and camera modalities, specifically addressing the variance in their contributions at different depth ranges.
Introduction
3D object detection is a critical component in autonomous driving systems, where the integration of LiDAR and camera data can substantially enhance perception accuracy. Traditional methods have primarily focused on feature-level fusion without adequately considering depth variations. This paper claims that depth is a significant factor that influences the relevance of LiDAR versus camera data. Through the introduction of DepthFusion, the paper suggests that depth-aware hybrid feature fusion can improve detection performance across different depth ranges.
DepthFusion Method Overview
DepthFusion introduces two key modules: Depth-GFusion and Depth-LFusion. These modules are integral to the proposed depth-aware feature fusion strategy that dynamically adjusts the feature weights of LiDAR and camera inputs.
Depth-GFusion
Depth-GFusion focuses on global feature fusion using Bird's Eye View (BEV) representations from both LiDAR and cameras. It integrates depth encoding into the global fusion process to adaptively adjust the emphasis on image features based on depth. This depth encoding uses sinusoidal functions, akin to positional encoding, to provide a computationally efficient method to incorporate depth information.
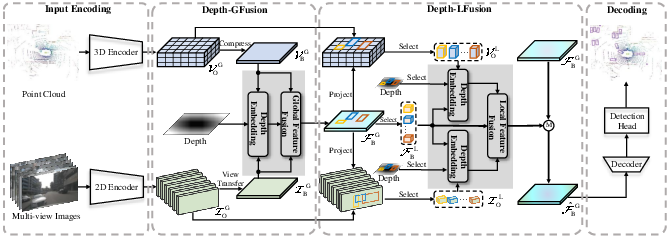
Figure 1: Overview of our method introducing depth encoding in both global and local feature fusion for depth-adaptive multi-modal representations.
Depth-LFusion
Depth-LFusion aims to enhance local feature fusion by utilizing region-specific voxel and image features. This module involves cropping local features based on regressed 3D boxes and applying a dynamic weighting strategy guided by the depth information. This approach compensates for information loss when transforming features into BEV space.
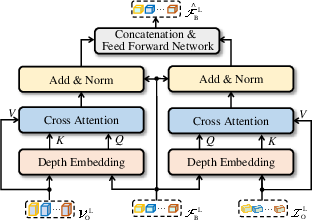
Figure 2: Illustration of the Depth-LFusion module.
Experimental Results
DepthFusion was evaluated on the nuScenes and KITTI datasets, demonstrating superior performance compared to state-of-the-art methods. The results highlight significant improvements in scenarios with varying depth and depict enhanced robustness to data corruptions.
- On the nuScenes dataset, DepthFusion achieved an NDS of 74.0 and mAP of 71.2 using a ResNet50 backbone, outperforming other contemporary methods.
- DepthFusion also showed strong performance on the KITTI dataset, achieving high mAP across small and distant objects, underscoring its ability to handle diverse object scales.
Robustness Experiments
When subjected to the nuScenes-C dataset, designed to test robustness under various corruptions, DepthFusion showed reduced performance degradation compared to baseline methods, particularly excelling in scenarios involving weather and object-level corruptions.
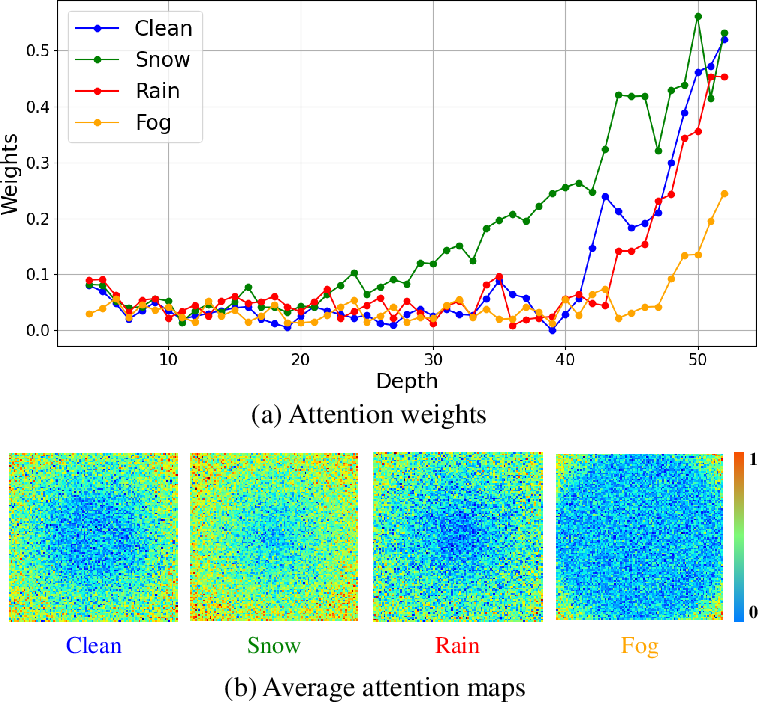
Figure 3: Statistics of attention weights and visualization of attention maps under different weather conditions, showcasing robustness.
Computational Efficiency
DepthFusion was designed with efficiency in mind, providing a balance between detection performance and computational cost. The method achieves competitive inference speeds, making it suitable for real-time applications.
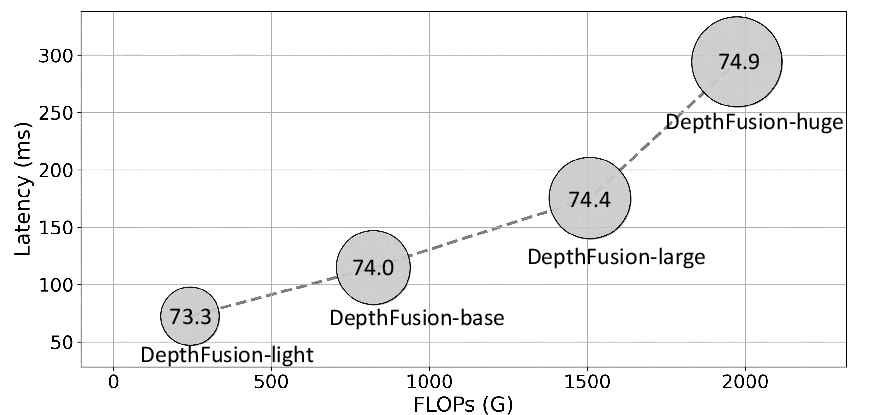
Figure 4: Trade-off between performance (NDS) and computational cost (FLOPs and latency) across different DepthFusion variants.
Conclusion
The introduction of depth encoding into the LiDAR-camera fusion process marks a significant advancement in 3D object detection methodology. DepthFusion's ability to dynamically adapt fusion strategies based on depth ensures enhanced detection accuracy and robustness across a range of scenarios. Future work could explore further refinement of depth encoding techniques and extend the method to more diverse datasets and real-world applications.

