- The paper introduces a two-stage detector that fuses sparse LiDAR and dense camera data using a unified attention mechanism.
- The methodology employs RoI feature extraction and dual attention (self and cross) to integrate complementary modality features.
- Experiments on KITTI and Waymo datasets demonstrate improved long-range detection and competitive performance over one-stage detectors.
FusionRCNN: LiDAR-Camera Fusion for Two-stage 3D Object Detection
The paper "FusionRCNN: LiDAR-Camera Fusion for Two-stage 3D Object Detection" (2209.10733) introduces a novel two-stage multi-modality 3D object detector that fuses LiDAR point clouds and camera images in the regions of interest. The proposed FusionRCNN adaptively integrates sparse geometry information from LiDAR and dense texture information from camera in a unified attention mechanism. It can significantly improve the performance of existing one-stage detectors with minor changes.
Introduction
The paper addresses the problem of accurately recognizing and locating objects using LiDAR point clouds, which can be difficult due to their sparsity, especially at long distances. To solve this, the authors propose FusionRCNN, a two-stage approach that effectively fuses point clouds and camera images in the Regions of Interest (RoI). The method leverages an intra-modality self-attention to enhance domain-specific features, followed by a cross-attention mechanism to fuse information from the two modalities. The approach is designed to be plug-and-play, allowing it to be integrated with different one-stage methods with minimal architectural changes.
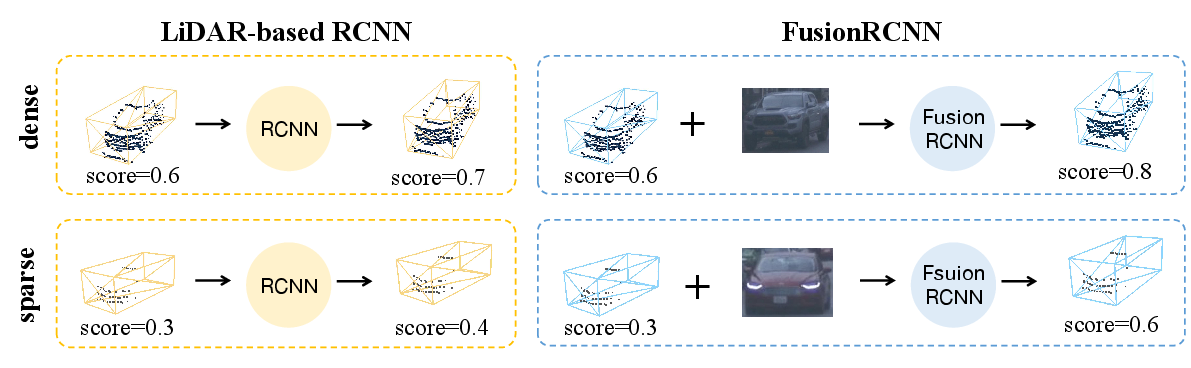
Figure 1: Comparison of our method with previous LiDAR-based two-stage methods. When objects comprise sparse point clouds, LiDAR-based methods fail to correctly determine the category and give less confident scores, while our method effectively combines point cloud structure with dense image information to solve such problems.
Method
The FusionRCNN architecture consists of three main steps: RoI feature extraction, feature fusion via attention mechanisms, and bounding box refinement.
The RoI Feature Extractor extracts RoI features from both point clouds and images corresponding to the proposals generated by a one-stage detector. For the point cloud branch, points within the expanded bounding box are sampled or padded to a unified number N. Point features are enhanced by concatenating the distance to the eight corners and the center of the bounding box. For the image branch, multi-view images are converted into feature maps via ResNet [he2016resnet] and FPN [lin2017fpn]. The expanded 3D bounding boxes are projected onto the 2D feature map, and RoI pooling is performed to obtain the image feature with a unified size.
Fusion Encoder
The Fusion Encoder fuses the features of the two modalities through intra-modality self-attention and inter-modality cross-attention. This module replaces hard associations between points and images with an attentive fusion mechanism. Self-attention is applied to both point and image features to model inner relationships. Then, cross-attention is used to fuse the information of the two domains at the feature level. The fused features are fed into a FFN with two linear layers.
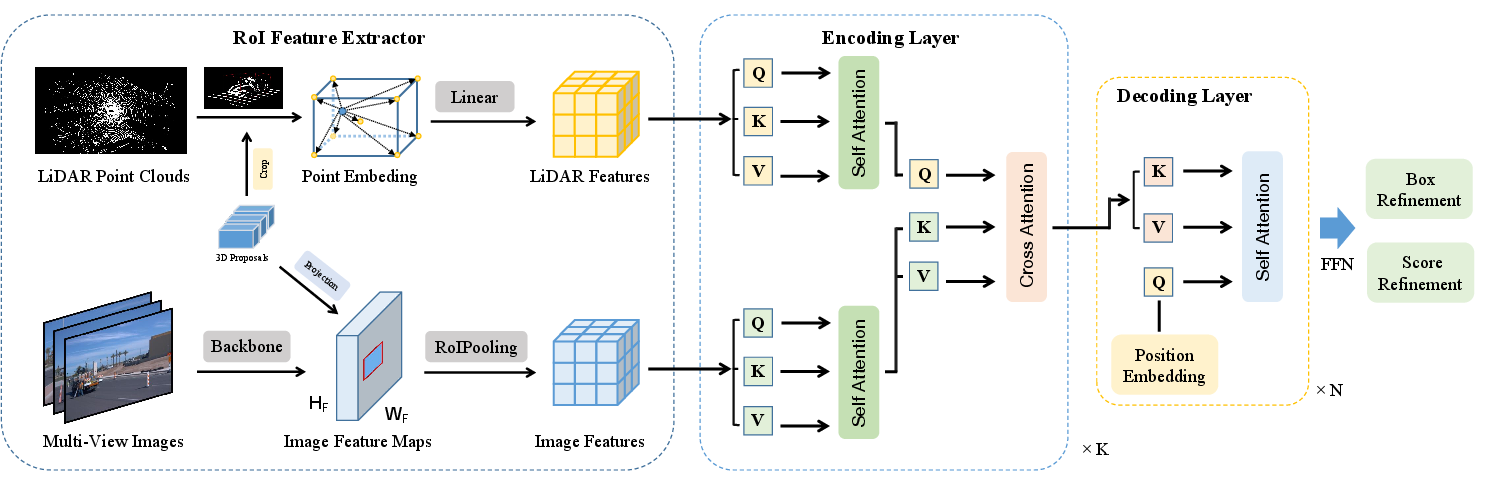
Figure 2: Overall architecture of FusionRCNN. Given 3D proposals, LiDAR and image features are extracted separately through RoI feature extractor. Then, the features are fed into K fusion encoding layers which comprises self-attention and cross-attention modules. Finally, point features fused with image information are further fed into a decoder and predict the refined 3D bounding boxes and confidence scores.
Decoder
The decoder module takes the encoded fusion features and refines the 3D bounding boxes and confidence scores. A learnable query embedding E is initialized and used as a query, with the encoded features serving as keys and values in an attention mechanism. The decoder module consists of several decoding layers to iteratively refine the features and predictions.
Experiments
The authors evaluated FusionRCNN on the KITTI [geiger2013vision, geiger2012we] and Waymo Open Dataset [sun2020scalability] datasets. The implementation details include the use of OpenPCDet [openpcdet2020], SECOND [yan2018second] as the RPN, ResNet50 [he2016resnet] as the image backbone, and Adam optimizer. The results on Waymo show that FusionRCNN outperforms previous methods in both LEVEL_1 and LEVEL_2 difficulty settings. On KITTI, FusionRCNN improves upon the one-stage method SECOND and achieves competitive performance with other LiDAR-based and LiDAR-Camera fusion methods.
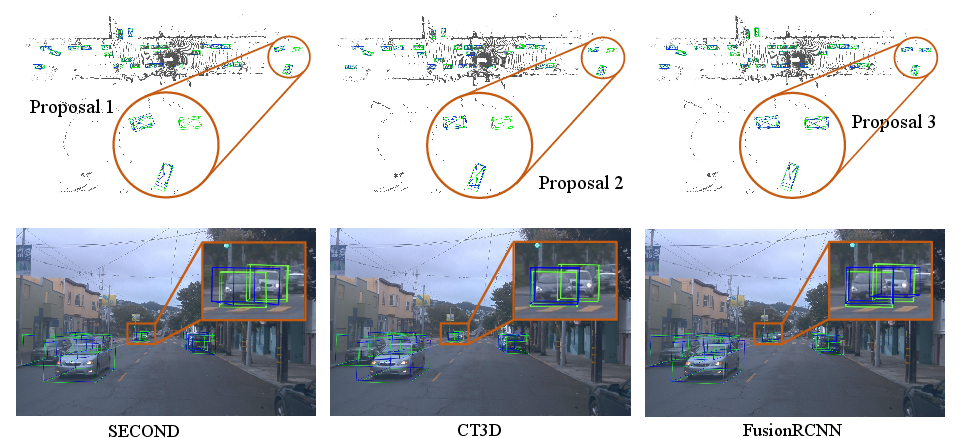
Figure 3: Qualitative comparison between LiDAR-based two-stage detector (CT3D) and our FusionRCNN on the Waymo Open Dataset. Green boxes and Blue boxes are ground-truth and prediction, respectively. Three proposal vehicles in red circle are zoom-in and visualize on 2D images and 3D point clouds. Our FusionRCNN works better than CT3D with only LiDAR input in long range detection.
Ablation studies validate the effectiveness of the LiDAR-Camera fusion and the generality of FusionRCNN with different RPN backbones such as SECOND, PointPillar [lang2019pointpillars] and CenterPoint [yin2021center]. The results indicate that the fusion of LiDAR and camera data leads to improved performance, especially for long-range detection. Additionally, the ablation studies on the RoI Feature Extractor show that different output sizes of RoI image features have little impact on performance, suggesting that the fusion encoding layer effectively integrates the LiDAR and image features.
Conclusion
The FusionRCNN framework effectively integrates LiDAR point cloud and camera image information, leveraging a well-designed attention mechanism to achieve Set-to-Set fusion. The method is robust to LiDAR-Camera calibration noise and has the potential to enhance existing one-stage 3D detectors.