- The paper shows that L2 regularization drives a phase transition, shifting the DNN error landscape and triggering an onset-of-learning.
- It employs geometric analysis using Ricci curvature and experimental testing on a two-hidden-layer network to highlight transitions at specific β values.
- Findings reveal grokking and hysteresis effects under high data complexity, offering insights for enhanced training control in neural networks.
Detailed Summary of "Phase Transitions between Accuracy Regimes in L2 Regularized Deep Neural Networks" (2505.06597)
Introduction
The paper investigates the phenomena associated with L2 regularization in deep neural networks (DNNs), focusing on phase transitions in their error and loss landscapes. It provides a geometric interpretation of phase transitions during the training of DNNs, characterizing these transitions using the Ricci curvature of the error landscape. The study extends existing works by predicting additional transitions when data complexity increases and elucidates the role of geometry in grokking.
Geometric Interpretation of Phase Transitions
L2 regularization modifies the loss landscape, acting as a force that shifts the global minimum towards the origin, effectively acting upon the parameter space. The paper describes a first-order phase transition termed "onset-of-learning", where DNNs transition from a useful model to a trivial one as regularization strength β increases.
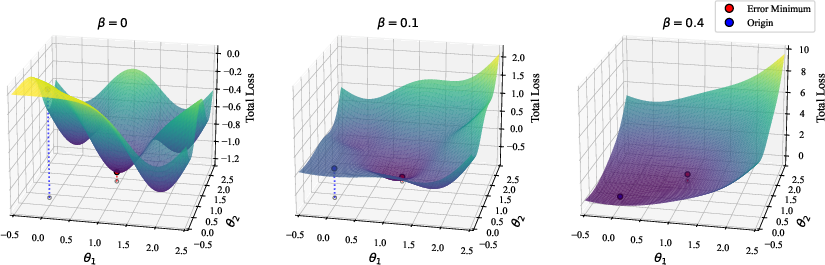
Figure 1: Sketch of a loss landscape with increasing L2 regularizer strength β.
This transition is characterized by a sudden shift in parameters, interpreted as the model being pushed out of an error basin, and can be observed as a jump in the error surface metrics.
Experimental Verification
The authors present experimental results that confirm the phase transitions in DNNs. A two-hidden-layer NN is considered, trained with varying β values illustrating transitions in mean squared error, curvature, and parameter distance.
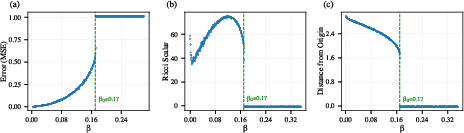
Figure 2: Phase transitions in a two-layer neural network with differing regularization strengths, showing transitions related to accuracy and error surface geometry.
The results show not only the onset-of-learning at β0 but also an additional transition at β1, pointing to complex interactions between regularization and data complexity.
Grokking and Hysteresis
Grokking, described as delayed convergence due to being stuck in a local minima, is explored as a hysteresis effect. This is especially pronounced in high-complexity scenarios, where models initially enter a low-accuracy phase before eventually achieving higher accuracy.
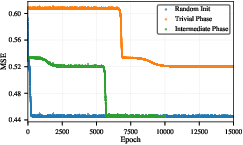
Figure 3: Mean-Squared-Error over Epochs for NNs with different initializations showing delayed convergence due to hysteresis.
The paper illustrates how grokking can be induced by initializing models within different accuracy phases, displaying the time-dependent nature of neural network training dynamics as controlled by error basins.
Conclusion
The research provides a comprehensive geometric framework for understanding phase transitions and hysteresis in L2 regularized DNNs. Through theoretical analysis complemented by numerical experiments, the paper deepens the understanding of how regularization interacts with data complexity. Future research directions include further characterizing the global error landscape and addressing methods to mitigate undesirable effects like grokking during neural network training. The study proposes potential for harnessing these insights to refine model training efficiency and controllability in complex learning environments.

