The Hidden Width of Deep ResNets: Tight Error Bounds and Phase Diagrams
Published 12 Sep 2025 in cs.LG | (2509.10167v1)
Abstract: We study the gradient-based training of large-depth residual networks (ResNets) from standard random initializations. We show that with a diverging depth $L$, a fixed embedding dimension $D$, and an arbitrary hidden width $M$, the training dynamics converges to a Neural Mean ODE training dynamics. Remarkably, the limit is independent of the scaling of $M$, covering practical cases of, say, Transformers, where $M$ (the number of hidden units or attention heads per layer) is typically of the order of $D$. For a residual scale $\Theta_D\big(\frac{\alpha}{LM}\big)$, we obtain the error bound $O_D\big(\frac{1}{L}+ \frac{\alpha}{\sqrt{LM}}\big)$ between the model's output and its limit after a fixed number gradient of steps, and we verify empirically that this rate is tight. When $\alpha=\Theta(1)$, the limit exhibits complete feature learning, i.e. the Mean ODE is genuinely non-linearly parameterized. In contrast, we show that $\alpha \to \infty$ yields a \lazy ODE regime where the Mean ODE is linearly parameterized. We then focus on the particular case of ResNets with two-layer perceptron blocks, for which we study how these scalings depend on the embedding dimension $D$. We show that for this model, the only residual scale that leads to complete feature learning is $\Theta\big(\frac{\sqrt{D}}{LM}\big)$. In this regime, we prove the error bound $O\big(\frac{1}{L}+ \frac{\sqrt{D}}{\sqrt{LM}}\big)$ between the ResNet and its limit after a fixed number of gradient steps, which is also empirically tight. Our convergence results rely on a novel mathematical perspective on ResNets : (i) due to the randomness of the initialization, the forward and backward pass through the ResNet behave as the stochastic approximation of certain mean ODEs, and (ii) by propagation of chaos (that is, asymptotic independence of the units) this behavior is preserved through the training dynamics.
The paper establishes that deep ResNets converge to a Neural Mean ODE in the infinite-depth limit, independent of how the hidden width scales.
It provides non-asymptotic error bounds that combine discretization (O(1/L)) and sampling errors (O(α/√(LM)), validated through extensive numerical experiments.
Phase diagrams delineate regimes for complete feature learning versus lazy training, offering principled guidelines for hyperparameter selection in large-scale architectures.
Tight Error Bounds and Phase Diagrams for Deep ResNets
Overview and Motivation
This paper provides a rigorous analysis of the training dynamics of deep residual networks (ResNets) under standard random initializations, focusing on the interplay between depth (L), hidden width (M), and embedding dimension (D). The central result is that, as depth diverges (L→∞), the training dynamics of ResNets converge to a Neural Mean ODE, regardless of how M scales with D. This limit is shown to be independent of the scaling of M, which is significant for practical architectures such as Transformers, where M is typically of the order of D. The paper establishes tight non-asymptotic error bounds between finite ResNets and their infinite-depth/width limit, and characterizes the regimes of feature learning and lazy training via phase diagrams.
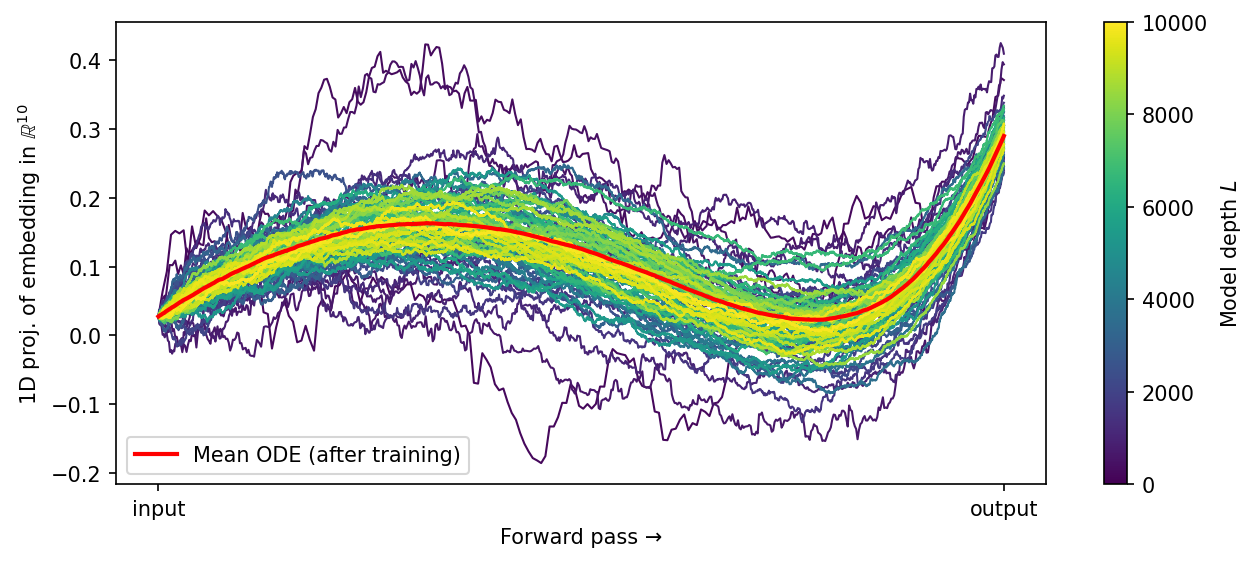
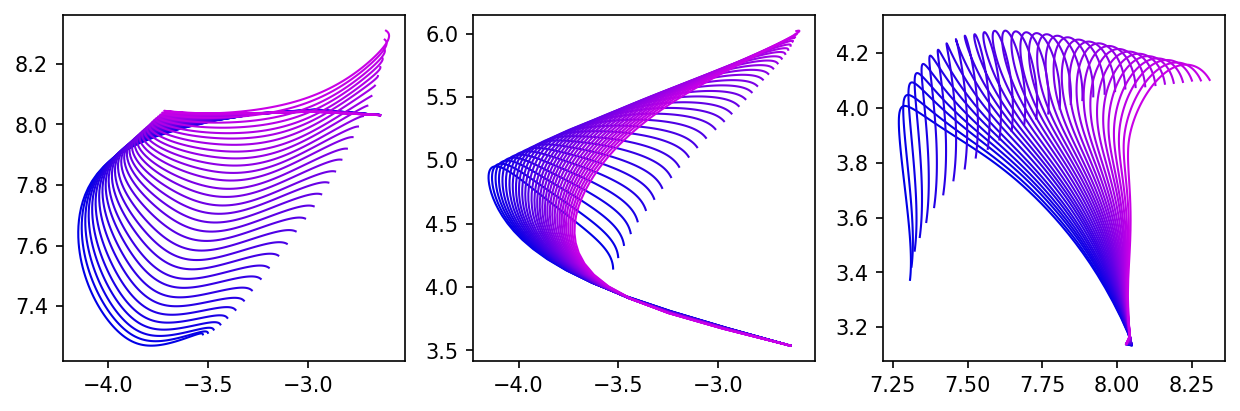
Figure 1: Forward pass (1D projection, fixed input) of trained ResNets with two-layer-perceptron blocks, varying depths L and hidden width M=1. The red curve shows the corresponding forward pass for the limit model.
Theoretical Results: Error Bounds and Regimes
Neural Mean ODE Limit
The paper formalizes the convergence of ResNet training dynamics to a Neural Mean ODE as L→∞, with arbitrary scaling of M. The forward pass recursion for a ResNet is given by: h^ℓ(x,z)=h^ℓ−1(x,z)+LMαi=1∑Mϕ(h^ℓ−1(x,z),zi,ℓ)
where ϕ is a generic block (e.g., MLP, attention head).
The corresponding limit model is described by the ODE: ∂sh(s,x,Z)=αE[ϕ(h(s,x,Z),Z(s))]
with Z a stochastic process over depth.
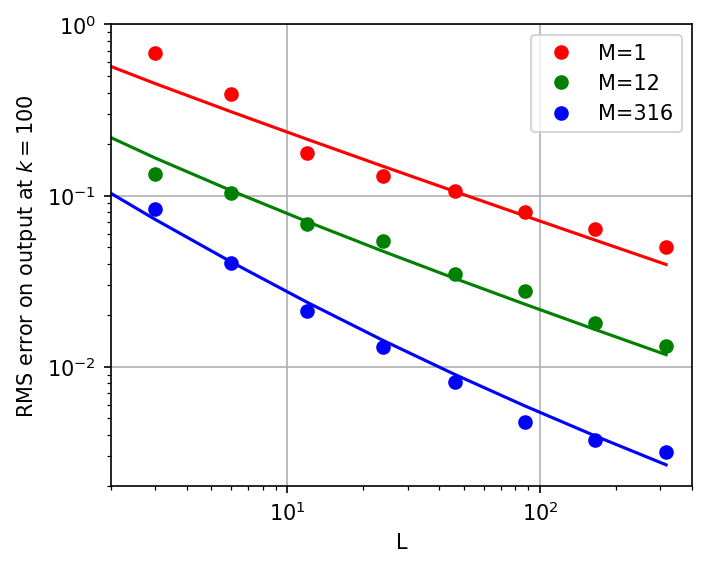
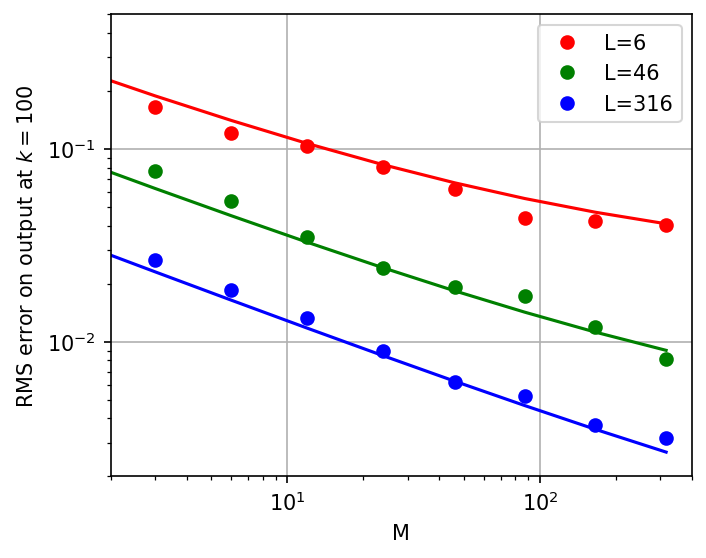
Tight Error Bounds
The main quantitative result is a non-asymptotic error bound between the output of a finite ResNet and its Neural Mean ODE limit after K gradient steps: OD,K(L1+LMα)
This bound consists of a depth-discretization error (O(1/L), Euler method) and a sampling error (O(α/LM), Monte Carlo rate), with LM acting as an effective width. Empirical results confirm the tightness of these rates.
Figure 2: Error on output vs depth L.
Feature Learning vs Lazy Regimes
Feature Learning Regime (α=Θ(1)): The limit exhibits complete feature learning, with nonlinear parameterization and nontrivial evolution of features.
Lazy ODE Regime (α→∞): The limit is linearly parameterized (Neural Tangent ODE), and the error bound becomes:
OD,K(α1+L1+LMα)
In this regime, parameter updates are suppressed, and feature learning is minimal.
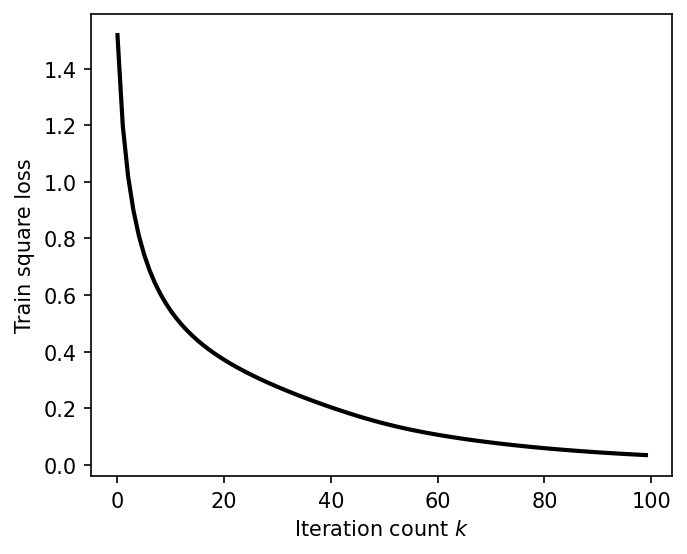
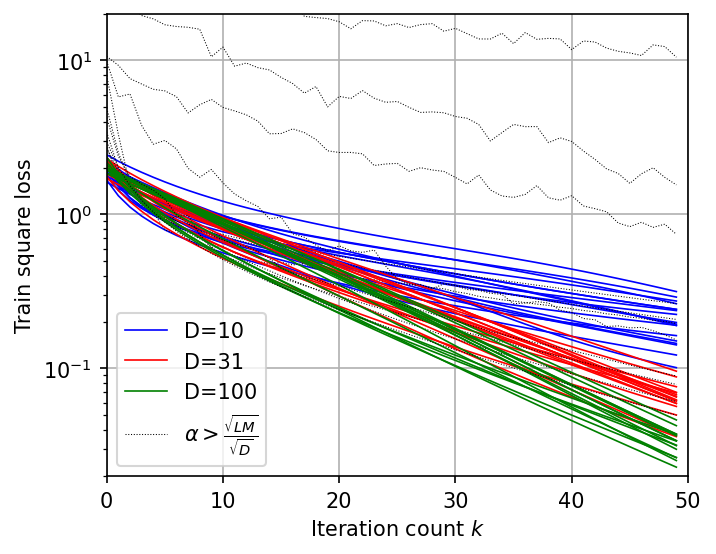
Figure 3: Evolution of the square loss, indicating convergence of the Mean ODE model.
Explicit Scaling Laws for Two-Layer Perceptron Blocks
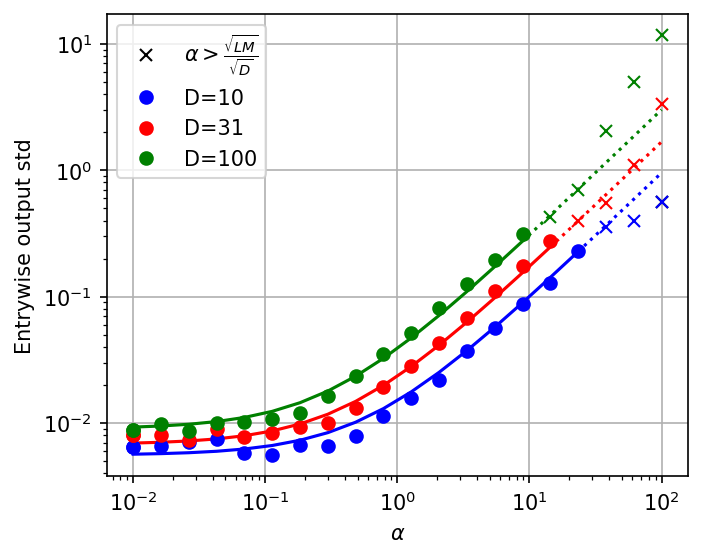
The analysis is extended to ResNets with two-layer perceptron (2LP) blocks, tracking explicit dependencies on D. The critical residual scale for complete feature learning is shown to be Θ(D/(LM)). The error bound in this regime is: O(L1+LMD)
This scaling is validated both theoretically and empirically, and is shown to be necessary for nontrivial feature evolution in practical settings where M≈D.
Figure 4: Fluctuations vs α, illustrating the sampling error scaling with α and D.
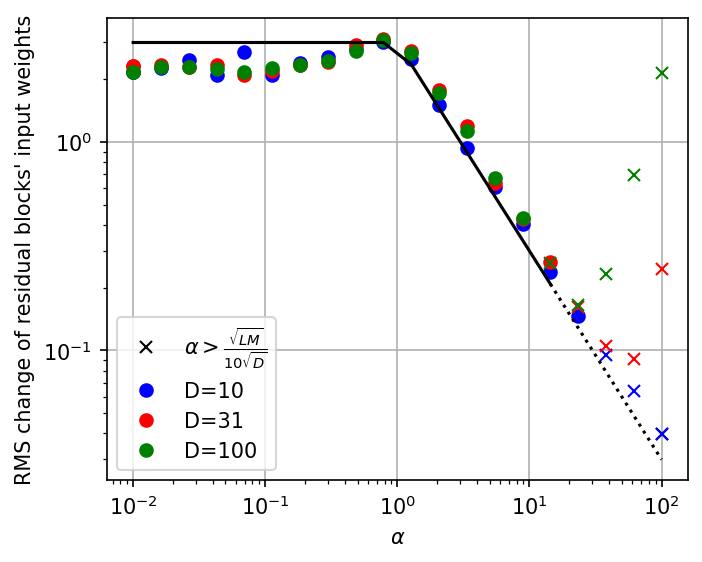
Phase Diagrams and Hyperparameter Implications
The paper synthesizes these results into phase diagrams that classify the regimes of ResNet training as a function of residual scale, depth, width, and embedding dimension. The only residual scale that leads to complete feature learning for arbitrary architectures with D=O(LM) is Θ(D/(LM)). Larger scales yield lazy training, while smaller scales result in semi-complete regimes with limited feature diversity.
The analysis provides principled guidance for hyperparameter selection in large-scale architectures, including Transformers, and clarifies the trade-offs between depth, width, and initialization scale.
Mathematical Techniques
The proofs leverage stochastic approximation theory and propagation of chaos, showing that the forward and backward passes through a randomly initialized ResNet behave as stochastic approximations of mean ODEs, and that this behavior is preserved through training. The error analysis combines discretization and sampling errors, and is robust to various block types (MLP, attention).
Empirical Validation
Extensive numerical experiments confirm the theoretical predictions, demonstrating tight agreement between observed errors and theoretical bounds across a range of L, M, D, and residual scales. The experiments also illustrate the regularity of the limit dynamics and the transition between feature learning and lazy regimes.
Implications and Future Directions
The results have direct implications for the design and scaling of deep architectures, especially in settings where width and depth are both large but not infinite. The identification of LM as the effective width and the explicit scaling laws for feature learning provide actionable guidelines for practitioners. The phase diagrams unify previous mean-field and Neural ODE analyses, and clarify the conditions under which feature learning is possible.
Theoretically, the work suggests further exploration of stochastic approximation methods for other architectures and training algorithms, and motivates the study of dynamical phenomena beyond initialization. Practically, the scaling laws and error bounds can inform automated hyperparameter tuning and architecture search in large-scale deep learning.
Conclusion
This paper establishes tight non-asymptotic error bounds for the convergence of deep ResNets to their Neural Mean ODE limit, identifies the critical scaling laws for feature learning, and provides phase diagrams that organize the hyperparameter space. The results are validated both theoretically and empirically, and have significant implications for the design and analysis of large-scale neural architectures. The mathematical framework developed here is broadly applicable and sets the stage for further advances in the theory and practice of deep learning.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.