- The paper presents a novel MAML-based framework that uses Gaussian Mixture Models to construct meta-tasks for zero-shot financial forecasting.
- It leverages a dual-purpose encoder and diverse task constructions (intra-cluster, inter-cluster, hard tasks) to adapt to sudden market regime shifts.
- Experimental results over international markets demonstrate improved accuracy and robustness, highlighting its effectiveness in volatile and emerging economies.
This paper introduces a novel MAML-based meta-learning framework designed for zero-shot financial time series forecasting, particularly in volatile markets or emerging economies. The approach focuses on constructing effective meta-tasks using Gaussian Mixture Models (GMMs) to cluster time series embeddings, enabling the model to adapt quickly to new market conditions and generalize across different financial instruments.
Methodology and Implementation
The core of the framework revolves around a dual-purpose encoder that generates embeddings used both for meta-task construction and downstream predictions. (Figure 1)
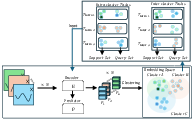
Figure 1: Illustration of the proposed meta-learning framework.
Input sequences are encoded, and GMMs are employed to softly cluster these embeddings, assigning them probabilistically to different latent regimes. This soft clustering approach allows for a more nuanced representation of the complex, multi-modal distributions often found in financial time series data. Meta-tasks are then constructed in three ways:
- Intra-cluster tasks sample support and query sets from the same cluster, encouraging local consistency.
- Inter-cluster tasks sample from different clusters, promoting the learning of distribution-invariant features.
- Hard tasks pair support and query sets from the most dissimilar clusters, further enhancing cross-domain adaptation.
The dissimilarity between Gaussian components i and j is measured using the symmetric KL divergence:
d(μi,Σi,μj,Σj)=21[DKL(Ni∥Nj)+DKL(Nj∥Ni)],
where Ni=N(μi,Σi) denotes the multivariate Gaussian distribution with mean μi and covariance Σi.
The encoder can be implemented using various architectures, such as GRUs, LSTMs, or Transformers, providing flexibility in adapting the framework to different computational constraints and performance requirements. The prediction head is typically a linear layer that maps the embeddings to future time steps. The learning procedure follows a standard MAML approach, where model parameters are adapted on the support set and evaluated on the query set, with the Pseudo-Huber loss function used for robustness against outliers.
Experimental Results and Analysis
The framework was evaluated on stock market datasets from high-volatility periods and multiple international markets, including the S{content}P 500, N225, HSCI, and NSE. The data were split into training, validation, and testing sets based on the VIX index to represent different volatility regimes. (Figure 2)
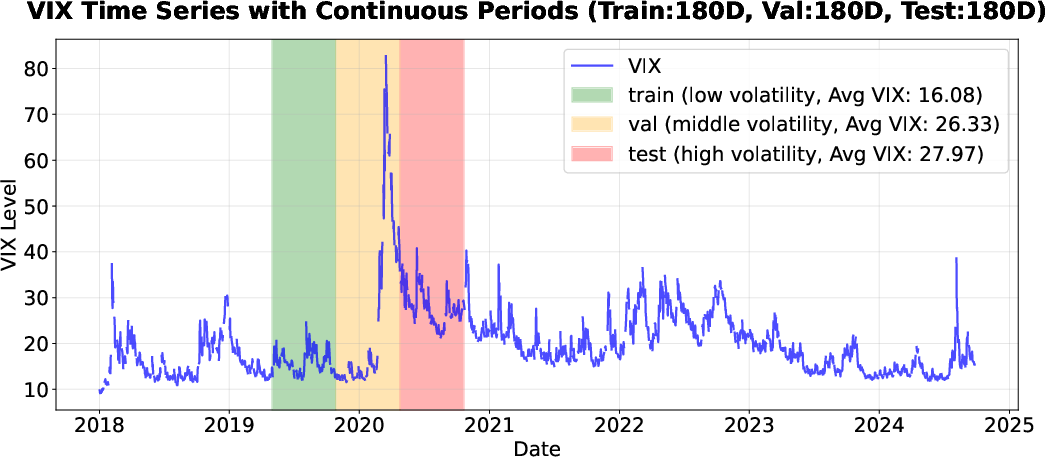
Figure 2: Data Split based on VIX.
The results demonstrate that the proposed framework outperforms existing approaches in zero-shot cross-stock prediction scenarios. Notably, the Indian market exhibited the most severe distribution shift, highlighting the model's ability to generalize under challenging conditions. (Figure 3)
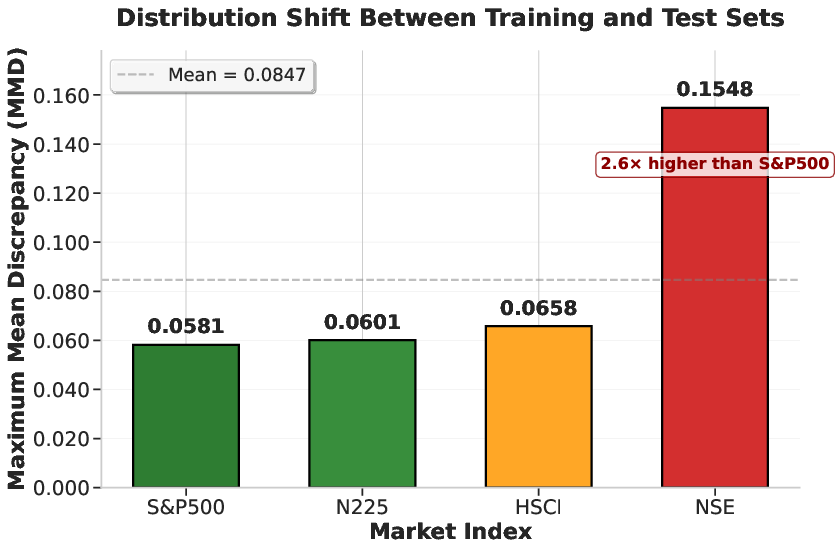
Figure 3: Maximum Mean Discrepancy (MMD) between training and test sets for each market.
Ablation studies further revealed the importance of both inter-cluster and hard tasks in achieving optimal performance, indicating that a combination of moderate and highly challenging meta-task structures is crucial for enhancing model robustness and generalization.
Parameter sensitivity analysis, conducted via grid search over the hard task ratio (HT) and inter-cluster ratio (CC), showed that the framework exhibits robustness across a wide parameter region, with optimal performance achieved at CC=0.7 and HT=0.9. (Figure 4)
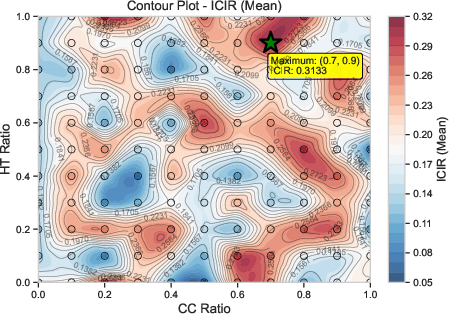
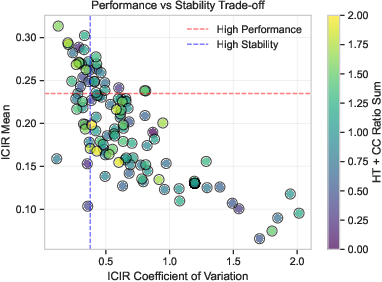
Figure 4: Contour plot of ICIR (Mean) for the Indian market across HT/ICT parameter grid.
Implications and Future Directions
This research addresses a critical challenge in financial time series forecasting: adapting to abrupt market regime shifts and generalizing to emerging markets with limited historical data. By leveraging meta-learning and GMM-based task construction, the proposed framework offers a robust and effective solution for zero-shot forecasting in dynamic financial environments.
Future work could explore adaptive strategies for task ratio selection and more flexible sampling schemes beyond fixed sliding windows to further enhance the approach's effectiveness.

