- The paper introduces RD-Agent(Q), a multi-agent framework that co-optimizes data-centric factors and models to enhance performance and reduce complexity.
- It details a modular pipeline—comprising specification, synthesis, implementation, validation, and analysis—integrated by a multi-armed bandit scheduler for adaptive optimization.
- Experimental results on the CSI 300 dataset demonstrate superior predictive metrics and higher returns with fewer factors compared to conventional methods.
Multi-Agent Framework for Data-Centric Factor-Model Co-Optimization
The paper "R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization" (2505.15155) introduces RD-Agent(Q), a novel multi-agent framework designed to automate the research and development of quantitative strategies through coordinated factor-model co-optimization. This framework addresses the limitations of current quantitative research pipelines, such as limited automation, weak interpretability, and fragmented coordination. RD-Agent(Q) decomposes the quantitative process into iterative research and development stages, connected by a feedback mechanism that evaluates experimental outcomes and informs subsequent iterations using a multi-armed bandit scheduler. The paper demonstrates that RD-Agent(Q) achieves higher annualized returns with fewer factors than classical factor libraries and outperforms state-of-the-art deep time-series models.
Core Components and Workflow of RD-Agent(Q)
RD-Agent(Q) comprises five functional modules that operate in a continuous iterative loop (Figure 1). These modules include:
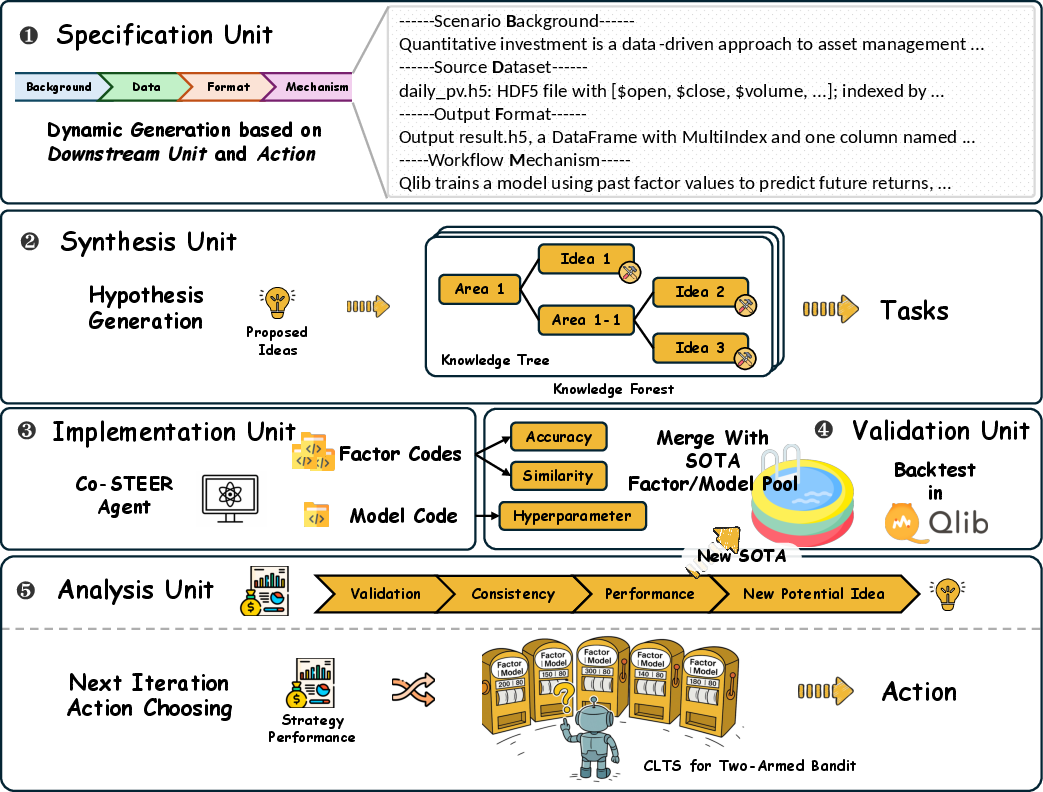
Figure 1: RD-Agent(Q) consists of five functional modules that collaborate in a continuous iterative loop to generate highly effective quantitative factors and models for real-world financial markets.
- Specification Unit: Dynamically configures task context and constraints, ensuring consistency across design, implementation, and evaluation.
- Synthesis Unit: Generates new hypotheses based on historical experiments, simulating human-like reasoning.
- Implementation Unit: Translates executable tasks into functional code using Co-STEER, a specialized code-generation agent.
- Validation Unit: Evaluates the practical effectiveness of generated factors or models through real-market backtests.
- Analysis Unit: Assesses experimental results, generates targeted suggestions for refinement, and adaptively selects the next optimization direction using a multi-armed bandit scheduler.
The Research phase involves the Specification and Synthesis Units, while the Development phase includes the Implementation and Validation Units, with the Analysis Unit providing feedback to both phases. The framework supports the dynamic co-optimization of factor and model components, enabling continuous and autonomous strategy evolution.
Implementation Details of Co-STEER
Co-STEER, the code-generation agent within the Implementation Unit, employs a guided chain-of-thought mechanism and a DAG to represent task dependencies. The agent maximizes cumulative implementation quality by generating code cj for each task tj based on the task description and a knowledge base K:
cj=I(tj,K)
The knowledge base K records successful and failed task-code-feedback triples, allowing the agent to retrieve solutions to similar tasks and improve code generation efficiency. The scheduling is adaptive, with feedback from previous executions integrated to improve planning. Repeated failures on a task signal increased complexity, prompting prioritization of simpler tasks to enhance knowledge accumulation and execution success.
Experimental Results and Analysis
The paper evaluates RD-Agent(Q) on the CSI 300 dataset, comparing its performance against various baselines, including classical factor libraries and machine learning/deep learning models. RD-Agent(Q) consistently outperforms these baselines in both predictive and strategic metrics.

Figure 2: Pass@k accuracy of GPT-4o and o3-mini in RD-Factor, RD-Model, and RD-Agent(Q). x-axis: attempts (k); y-axis: success rate within k tries.
When only the factor space is optimized (RD-Factor), the framework surpasses static factor libraries with higher IC and improved ARR using fewer factors. For model optimization with fixed factors (RD-Model), the framework achieves the best performance on Rank IC and MDD. Jointly optimizing factors and models (RD-Agent(Q)) yields the highest overall performance, demonstrating that coordinated refinement unlocks complementary improvements. The pass@k accuracy metric (Figure 2) illustrates Co-STEER's ability to efficiently repair initial errors through feedback.
A key finding is that RD-Agent(Q) achieves these results at a cost of under \$10, demonstrating its cost-efficient scalability. The research component of RD-Agent(Q) balances exploration and exploitation, enabling the construction of compact, diverse, and high-performing factor libraries (Figure 3). Analysis of factor effects demonstrates that iterative factor refinement eliminates regime-sensitive or redundant signals, improving predictive stability (Figure 4).

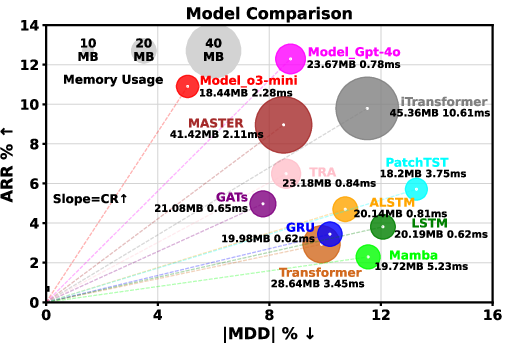
Figure 3: Comparison between classical factor libraries and RD-Factor-generated factors using a LightGBM predictor on CSI~300. RD-Factor was initialized from Alpha~20 or~Alpha 158 and operated with GPT-4o or o3-mini.
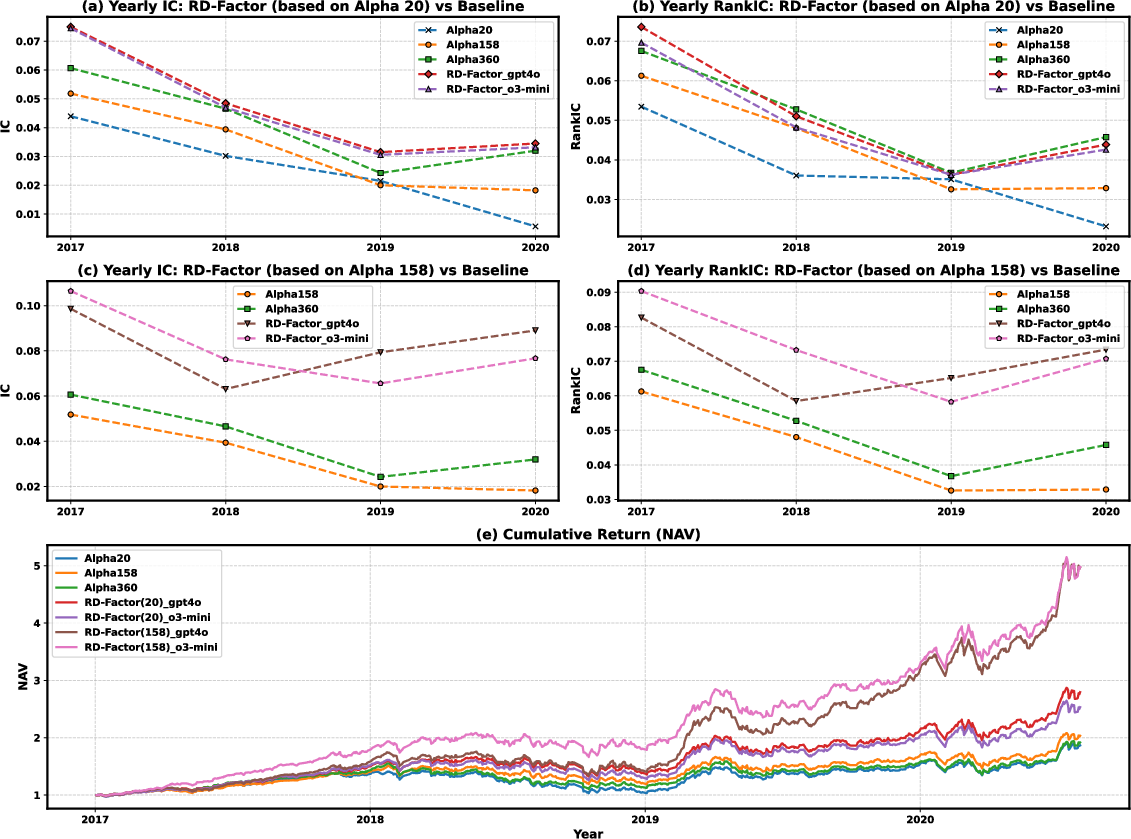
Figure 4: Comparison between classical factor libraries and RD-Factor-generated factors using a LightGBM predictor on CSI~300. RD-Factor was initialized from Alpha~20 or~Alpha 158 and operated with GPT-4o or o3-mini. The top left figure shows the IC values of each method across different years, while the top right figure shows the RankIC valuesâthe higher the value, the stronger the predictive power. The bottom figure presents the cumulative returns (NAV) of the corresponding strategies.
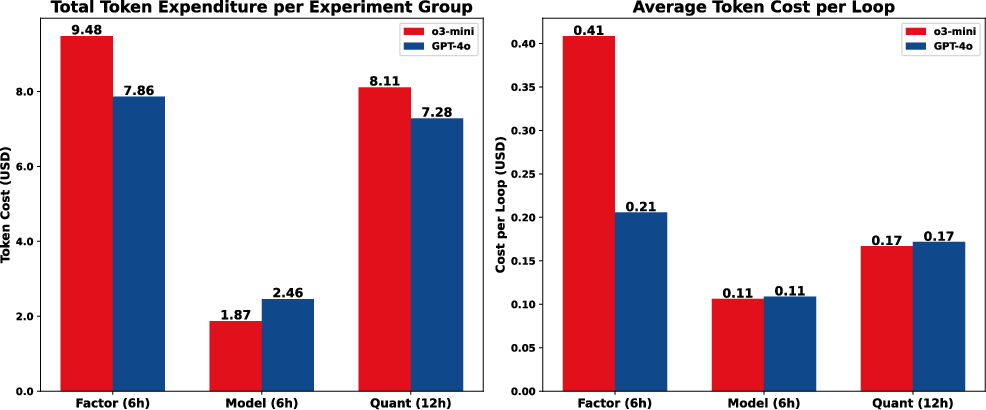
Figure 5: Token cost across different LLM backends (averaged over 5 trials). Left: total cost over corresponding runtimes (6h for RD-Factor/RD-Model, 12h for RD-Agent(Q)); right: average per-loop cost. All costs are in USD.
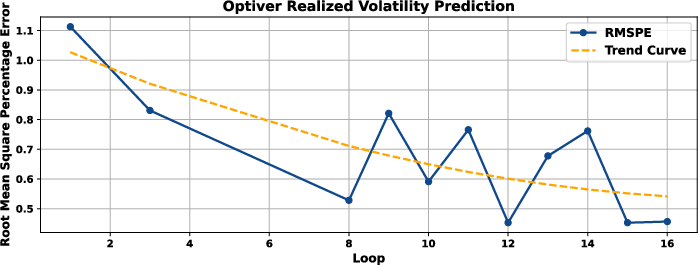
Figure 6: The RMSPE curve and fitted curve of RD-Agent on Optiver Realized Volatility Prediction.
Implications and Future Directions
RD-Agent(Q) presents a significant advancement in automating quantitative research by integrating LLMs with a multi-agent framework. The framework's modular design and bandit-based scheduler facilitate efficient and adaptive iteration under computational constraints. The experimental results demonstrate its superior performance in signal quality, strategy performance, and cost-efficiency. RD-Agent(Q)'s modularity also enables adaptation to real-world settings. However, the framework's reliance on the LLM's internal financial knowledge suggests avenues for future work. Enhancements could include incorporating domain priors and enabling online adaptation to evolving market regimes. Moreover, the application of RD-Agent(Q) to the Optiver Realized Volatility Prediction competition (2505.15155) highlights its potential for solving complex, real-world financial problems. The cost efficiency of RD-Agent(Q) is demonstrated in Figure 5.
The paper concludes by acknowledging the limitations of the current framework and suggesting future research directions, such as enhancing data diversity, incorporating domain priors, and enabling online adaptation to evolving market regimes. RD-Agent(Q) marks a step toward intelligent and autonomous quantitative research, with broad implications for the asset management industry.