- The paper demonstrates that LLMs can handle complex arithmetic yet falter on basic addition, questioning their true rule comprehension.
- The paper shows that performance drops sharply under symbolic transformations, highlighting a dependence on token-level heuristics.
- The paper reveals that while fine-tuning boosts numeric accuracy, it often fails to improve symbolic task performance, underscoring a trade-off in generalization.
Assessing Understanding of Arithmetic in LLMs: An Analysis
LLMs have demonstrated capability on sophisticated mathematical benchmarks, yet they frequently falter on basic arithmetic operations. This paper systematically investigates whether LLMs truly understand fundamental arithmetic rules or merely replicate learned patterns. The study employs two-integer addition as a diagnostic lens to evaluate LLMs on three critical properties: commutativity, representation invariance, and scaling consistency. Insights from twelve leading LLMs reveal a predominant reliance on pattern matching rather than robust rule-based reasoning.
Diagnostic Approach and Empirical Evidence
The Paradox of Arithmetic Competence
Although LLMs excel mathematically, basic arithmetic tasks expose significant weaknesses, raising doubts about their grasp of underlying rules. The paper illustrates this paradox through a representative example: LLMs perform complex numerical calculations with ease, yet struggle with simple tasks like basic addition (Figure 1).

Figure 1: Illustration of LLM Paradox: LLMs excel at complex math but falter on basic addition, raising the question of whether they grasp rules or merely reproduce patterns. True grasp implies consistent performance and adherence to mathematical properties under novel conditions.
Commutativity and Symbolic Representation
Evaluation of twelve LLM models against commutativity and symbolic representation invariance highlights systemic performance issues. Failures in these areas suggest that LLMs predominantly leverage token-level heuristics over abstracted rules, evidenced by significant accuracy drops in commutativity tests and symbolic tasks. LLMs achieving 98% numeric accuracy often see performance plummet to 7% under symbolic remapping, revealing a core reliance on familiar input patterns.
Non-Monotonic Scaling Consistency
Evidence shows non-monotonic behavior regarding operand length: accuracy inconsistently rebounds at certain digit counts instead of degrading monotonically (Figure 2). Such patterns indicate that success derives from memorized heuristics rather than scalable arithmetic understanding.
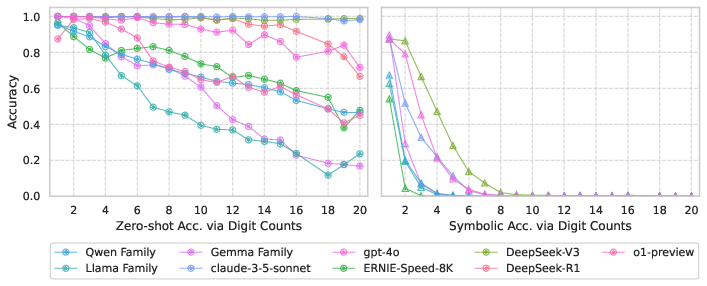
Figure 2: Performance Degradation Patterns in Zero-shot vs. Symbolic Addition. Suggests brittle pattern matching rather than true algorithmic reasoning, with systematic degradation in symbolic addition tests.
Modulating Comprehension Through Intervention
Prompt-level and Parameter-level Interventions
The paper explores interventions including explicit rule provision and fine-tuning strategies. Surprisingly, explicit rule provision degrades arithmetic performance, contradicting expected improvements (Figure 3). This degradation underscores LLMs' tuning towards token memorization.
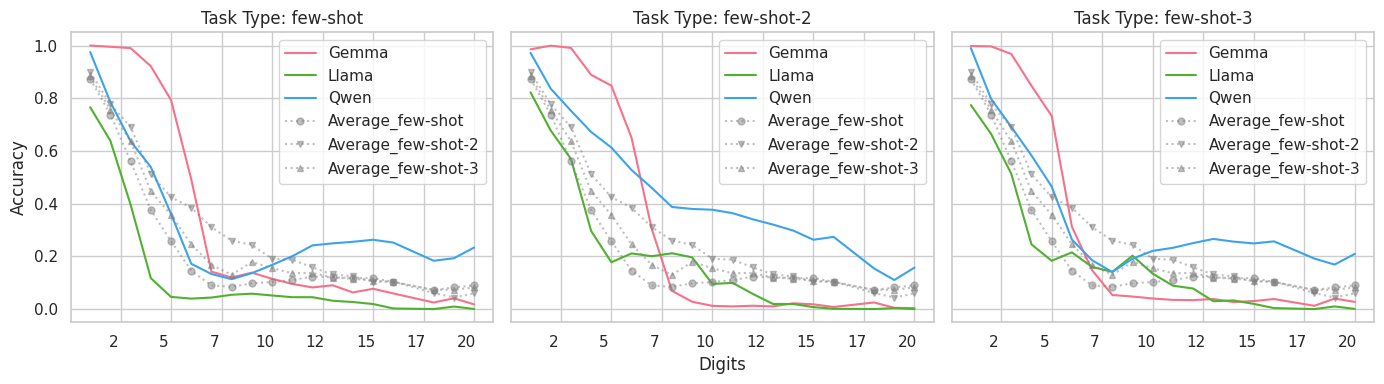
Figure 3: Few-Shot Performance with Explicit Rule Provision. This strategy drops performance compared to zero-shot, contradicting improvement expectations.
Fine-Tuning Strategies
Fine-tuning experiments reaffirm the pattern-matching characteristics in LLMs. While Supervised Fine-Tuning (SFT) enhances numeric accuracy, it shows minimal transfer to symbolic tasks, reflecting a primary optimization towards data-specific tokens. Preference Optimization (DPO) and Reinforcement Learning (RL) strategies yield better symbolic task generalization but compromise peak numeric performance, revealing trade-offs between generalization and specialization.
Implications and Future Directions
The findings underscore a significant limitation in current LLMs' arithmetic comprehension, suggesting an urgent need for new benchmarks focusing on keyword invariance, scaling consistency, and algebraic integrity. Beyond benchmarking, future model development should strive for architectures capable of abstract rule abstraction, bridging pattern reliance and genuine arithmetic reasoning. The implication is clear: without targeted evaluation efforts, prevailing benchmarks may inflate perceived LLM capabilities, overlooking foundational reasoning gaps.
Conclusion
In summary, this diagnostic study exposes critical arithmetic understanding deficits in LLMs despite their apparent mathematical prowess. The reliance on pattern-matching over rule-based reasoning limits models' arithmetic reliability. Moving forward, research must prioritize fostering genuine mathematical abstraction in LLMs to facilitate robust, rule-consistent AI applications.