- The paper demonstrates that GSM-Symbolic, a benchmark using symbolic templates, significantly challenges LLMs’ reasoning capabilities.
- It employs an 8-shot Chain-of-Thought approach and diverse problem instantiations to reveal model fragility and sensitivity to minor numeric variations.
- Findings indicate that LLMs rely on pattern matching rather than genuine logical reasoning, with performance dropping as question complexity increases.
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in LLMs
Introduction
The paper "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in LLMs" explores the mathematical reasoning capabilities of LLMs, specifically addressing their performance limitations with the GSM8K benchmark. The authors propose GSM-Symbolic, an enhanced benchmark designed to provide more reliable metrics for evaluating mathematical reasoning capabilities of these models. By introducing a diversity of problem variants through symbolic templates, GSM-Symbolic extends beyond static question sets to enable controlled evaluations of LLMs over numerous instantiations.
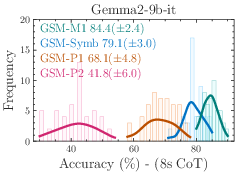
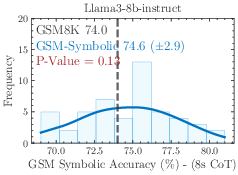
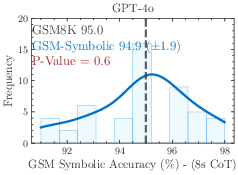
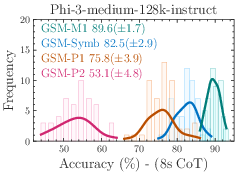
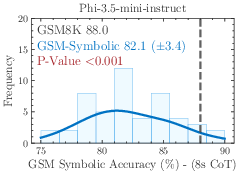
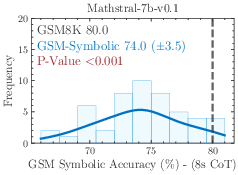
Figure 1: 8-shot CoT performance across 50 sets generated from GSM-Symbolic templates. All state-of-the-art models exhibit notable variance in accuracy.
Methodology
GSM-Symbolic Benchmark
The GSM-Symbolic benchmark was developed to capture a wider array of mathematical reasoning scenarios than are possible with the GSM8K dataset. By utilizing symbolic templates, GSM-Symbolic can generate an extensive variety of questions while preserving consistent logical steps required for solutions. The templates facilitate changes in variables such as names and numerical values, allowing the study of how these alterations affect LLM performance.
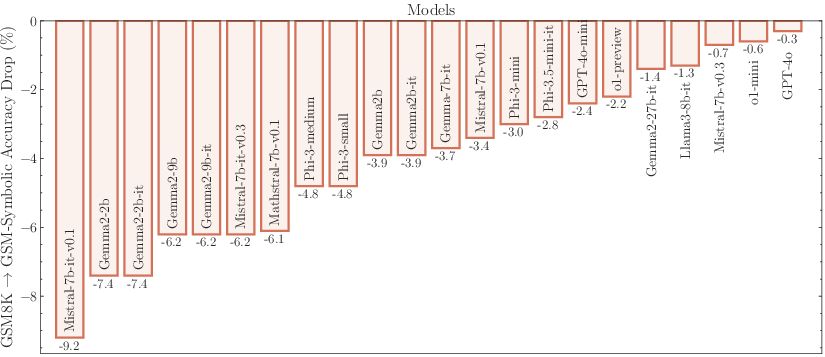
Figure 2: The performance of all state-of-the-art models on GSM-Symbolic drops compared to GSM8K.
Evaluation Setup
The study employs an 8-shot Chain-of-Thought prompting approach across multiple sub-benchmarks generated from GSM-Symbolic templates. Evaluations are structured around different variants by manipulating characteristics such as the insertion of extraneous clauses or altering variable values to assess the impact on model reasoning.
Results
The models demonstrate considerable variance in performance when tested across different GSM-Symbolic generated instances. Statistical analysis suggests that the original benchmark scores, represented by dashed lines, often lie at the distribution tails of the GSM-Symbolic performances, hinting at potential data contamination and indicating a model's potential memorization rather than reasoning capability.
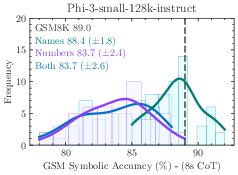
Figure 3: How sensitive are LLMs when we change \textcolor{teal60}{only names}, \textcolor{purple70}{only numbers}, or \textcolor{cyan60}{both names and numbers}?
Sensitivity to Superficial Changes
The study reveals a heightened sensitivity of LLMs to minor numeric adjustments compared to nominal alterations. This is evidenced by a noticeable performance drop and increased variance when changes extend beyond superficial names to numeric elements, reinforcing the hypothesis that LLMs frequently rely on pattern matching rather than genuine reasoning.
Impact of Question Complexity
The authors investigate the influence of question complexity by evaluating LLMs' performance on GSM-Symbolic variants with different levels of difficulty. Variations in performance distributions consistently show a decrease in accuracy and increase in variance as complexity escalates by adding additional clauses to the questions.
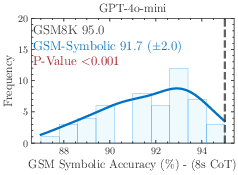
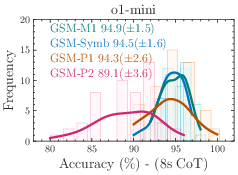
Figure 4: The impact of increasing the number of clauses on performance: As the difficulty increases from → → → , the distribution of performance shifts to the left (i.e., accuracy decreases), and the variance increases.
Analysis of Logical Reasoning
GSM-NoOp Dataset
The introduction of the GSM-NoOp dataset further tests LLMs' reasoning capabilities by including irrelevant but seemingly significant clauses within problems. The paper highlights substantial performance declines (up to 65%) when the models, constrained by pattern-matching strategies, fail to recognize the irrelevance of the extraneous information.
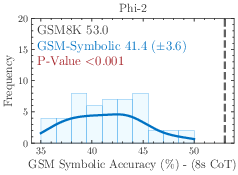
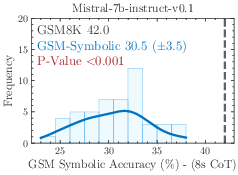
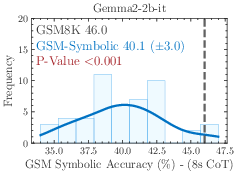
Figure 5: Additional results on performance variation on GSM-Symbolic.
Conclusion
This comprehensive study underscores significant LLM limitations in mathematical reasoning, suggesting a predominant reliance on training data patterns over true logical derivation. While GSM-Symbolic advances robust evaluation methodologies, the findings reveal inherent fragility in LLM reasoning, marked by susceptibility to minor input changes and amplified difficulty effects. These insights provide a roadmap for future exploration into developing models with authentic reasoning capabilities, highlighting a critical challenge in progressing towards AI systems capable of human-like cognitive operations and general intelligence.