- The paper presents a novel approach to client-side ML training by leveraging AMD's NPU and bare-metal programming tools.
- It achieves a 2.8x speedup in GEMM operations compared to CPU-only execution, showcasing significant performance improvements.
- The study employs AMD's XDNA architecture and IRON toolchain to optimize data routing and balance power efficiency with computational throughput.
Unlocking the AMD Neural Processing Unit for Client-side ML Training
This paper details the implementation of ML model training on the client side using the AMD Neural Processing Unit (NPU) and bare-metal programming tools. The study demonstrates the potential for customizing ML workloads on consumer devices while optimizing for throughput and power efficiency. Central to this investigation is the deployment of a LLM, GPT-2, on the NPU using a bare-metal toolchain (IRON), achieving notable improvements in speed and energy efficiency.
Introduction
Increasing demand for localized ML capabilities has driven hardware innovations such as AMD's Ryzen AI processors featuring dedicated NPUs. These specialize in efficient ML performance without compromising power efficiency. Unlike general-purpose GPUs, NPUs streamline computations by targeting specific ML tasks, benefiting from specialized architectures like AMD's XDNA.
AMD XDNA Architecture
The AMD NPU's XDNA architecture is a spatial computing setup comprised of AI Engines arranged in a grid, each capable of executing tasks independently.
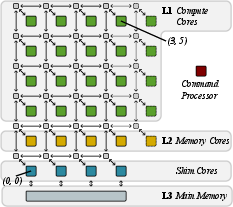
Figure 1: XDNA architecture showcasing compute, memory, and shim cores interconnected for optimal data routing.
XDNA facilitates AI Engine programmability through bare-metal access, empowering developers to customize implementations beyond what integrated libraries offer.
Methodology
AMD's IRON toolchain grants programmers direct control over the NPU's operations, utilizing MLIR and Python for low-level hardware management.
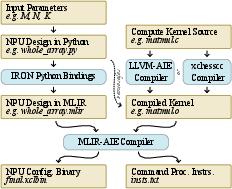
Figure 2: IRON tool-flow detailing tool components and intermediate output stages.
By creating specialized matrix multiplication (GEMM) kernels within GPT-2's framework, the researchers were able to offload intensive computations onto the NPU, reducing the computational burden on the CPU.
Implementation
CPU and NPU Design
A hybrid strategy was employed, segregating computations between the CPU for general processing and the NPU for intensive matrix multiplications. This division minimizes NPU reconfiguration overheads, optimizing overall performance.
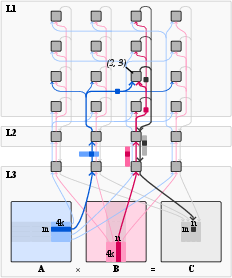
Figure 3: Data movement across memory levels, illustrating the interconnection of AI Engines.
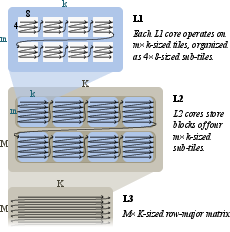
Figure 4: Detailed transformations of matrix data layout to optimize DMA and VMAC operations.
Tiling dimensions were selected to optimize load balance and memory use, ensuring efficient parallel processing across NPU cores.
Evaluation
The implementation exhibited a significant speedup in matrix multiplication performance, with the NPU variant outperforming the CPU-only execution by over 2.8×. The end-to-end application throughput achieved a 1.7× speedup on mains power and 1.2× on battery power, demonstrating both speed and energy efficiency.
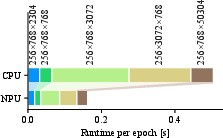
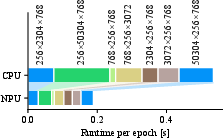
Figure 5: Comparison of GEMM runtimes based on matrix sizes, illustrating the NPU's efficiency with larger computations.

Figure 6: Runtime breakdown for GEMM operations, highlighting the primary contributions of NPU kernel performance.
Conclusion
This exploration underscores the benefits of programmatically exploiting NPUs for client-side ML tasks. By utilizing bare-metal programming, the study achieved substantial performance gains, paving the way for more sophisticated application of NPUs in consumer devices. Future work could focus on extending the NPU's role beyond isolated computations to entire ML workflows for further efficiency improvements.
The findings highlight the significance of hardware specialization in advancing ML capabilities at the edge, setting a precedent for future developments in AI computing efficiency and customization.

