- The paper demonstrates that large transformer-based models can synthesize Python code from textual descriptions with up to 59.6% accuracy in few-shot settings.
- The methodology employs few-shot learning and fine-tuning, showing a log-linear performance improvement as model size increases.
- Human-model collaboration using interactive feedback halves errors and refines code generation across benchmarks like MBPP and MathQA-Python.
Program Synthesis with LLMs
The paper "Program Synthesis with LLMs" (2108.07732) explores the capabilities of large transformer-based LLMs in synthesizing programs from textual descriptions within general-purpose programming languages such as Python.
Introduction
Program synthesis has been a longstanding goal in AI, facilitating automation in code generation from human-readable specifications. Historically, this has been dominated by knowledge-driven and symbolic approaches suitable for domain-specific languages, but recent advances allow for machine learning models to tackle general-purpose languages. The paper aims to evaluate LLMs across multiple benchmarks, focusing on their ability to generate, evaluate, and refine code based on few-shot learning and model fine-tuning.
Datasets
The authors introduce two datasets: Mostly Basic Programming Problems (MBPP) and MathQA-Python. MBPP is crafted to include problems solvable by entry-level programmers, encompassing 974 programming tasks. It tests models on their ability to synthesize Python functions from natural language descriptions, requiring the use of loops, conditionals, and numerical manipulations.
MathQA-Python, derived from the MathQA dataset by converting its domain-specific language solutions into Python code, challenges models on mathematical word problems. These benchmarks are designed to systematically probe the synthesis capabilities of models across diverse coding tasks.
Model and Methodology
The models employed are Transformer-based dense decoder-only architectures with parameter counts ranging from 244 million to 137 billion. They are pre-trained on a mixed corpus containing programming-related documents but not exclusively code files, allowing syntactical learning without preconceived grammatical constraints. The synthesis tasks evaluate few-shot learning, where models utilize problem-solving prompts that embody examples of prior tasks, and fine-tuning performance to increase accuracy.
Results on MBPP
Performance scaling with model size is observed, demonstrating a log-linear increase in synthesis ability (Figure 1). The largest models achieve up to 59.6% problem-solving accuracy in few-shot configurations, improving by roughly 10% upon fine-tuning. Errors primarily consist of runtime and syntactic discrepancies, but decline as model size expands (Figure 2).
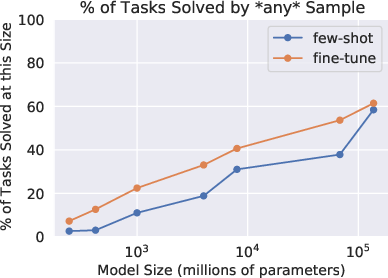
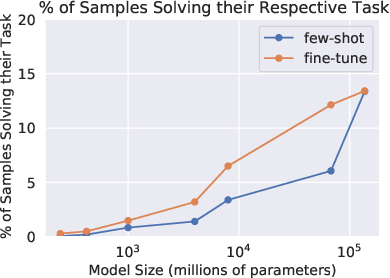
Figure 1: Performance vs model size, exhibiting predictable improvement in synthesis capability, particularly with increases in model size.
Human-Model Collaboration
An advanced facet of the research incorporates human feedback in a dialog system to refine program outputs. This interactive mechanism demonstrates that model errors can be halved and synthesis success improved when human corrections guide model responses over multiple dialog interactions (Figure 3).

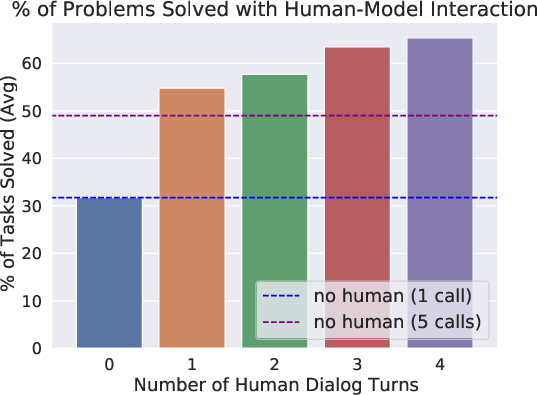
Figure 3: Overview of the human-model collaboration experiment flow, showing iterative dialog steps for program refinement.
MathQA Results
The MathQA-Python dataset tests the mathematical reasoning abilities of the models, with synthesis capabilities improving significantly upon fine-tuning. Large models achieve high accuracy levels with sufficient training data. Moreover, the interactive dialog system suggests potential in eliciting stepwise reasoning and problem-solving clarity within mathematical contexts (Figure 4).

Figure 4: Example demonstrating mathematical problem-solving and reasoning elucidation within model-generated solutions.
Conclusion
The study illustrates promising advancements in automatic program synthesis using LLMs, enhancing capabilities in coding tasks from textual descriptions. These models pave the way for future developments in AI-assisted programming, offering tools for interactive code generation, refinement, and learning. Future directions involve addressing semantic comprehension challenges and exploring more complex programming contexts. Overall, the ability to machine-check synthesized solution accuracy presents a valuable asset in integrating AI models into software development workflows.

