- The paper introduces ImplexConv, a large-scale dataset featuring multi-session dialogue with challenging implicit reasoning scenarios.
- The paper presents TaciTree, a hierarchical retrieval framework that improves accuracy by 30% using 40–60% fewer tokens compared to baselines.
- The study demonstrates that leveraging structured conversation history enhances the efficient extraction of implicit persona details in extended dialogues.
Toward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning
Introduction
The paper "Toward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning" presents a novel approach addressing the challenges of generating personalized conversational responses spanning multiple sessions via LLMs. Existing dialogue datasets often lack the ability to capture implicit reasoning where relevant information is embedded in syntactically or semantically distant connections. ImplexConv is introduced as a large-scale long-term dataset with unique scenarios for implicit reasoning. Additionally, a hierarchical tree framework, TaciTree, is proposed to efficiently structure and retrieve relevant details from conversation histories.
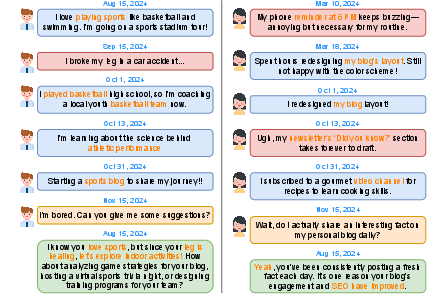
Figure 1: An example from ImplexConv illustrating opposed (left) and supportive (right) implicit reasoning. The orange block is the user query, the red blocks are implicit scenarios with low semantic similarity to the query, and the blue blocks are noisy but lexically related conversations that obscure the correct response.
ImplexConv Dataset
ImplexConv comprises 2,500 examples, each containing approximately 100 conversation sessions enriched by 600 thousand persona traits. Unlike conventional datasets, ImplexConv includes implicit reasoning scenarios where persona traits subtly reinforce or oppose other personalization details, making direct retrieval challenging due to low semantic similarity. The dataset's construction involves persona extraction, implicit reasoning generation, and conversation formulation. Implicit reasoning is characterized by integrating semantically distant connections, which hinders straightforward retrieval methods from traditional datasets.
TaciTree Framework
TaciTree is introduced as an efficient framework to combat retrieval inefficiencies in long-term conversations. This hierarchical tree-based framework structures conversation history by organizing information into multiple levels. At each level, TaciTree refines searches progressively and evaluates whether summaries should lead to exploring lower-level details. This method significantly reduces the computational complexity compared to brute-force retrieval while retaining high accuracy, leveraging LLM reasoning abilities to exploit the tree structure for efficient retrieval.
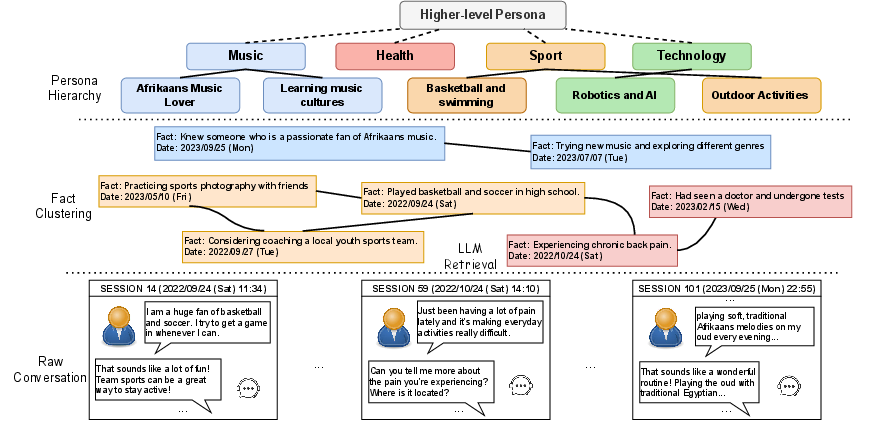
Figure 2: Overview of TaciTree framework, which organizes long-term conversational history into a hierarchical structure, clustering related facts for efficient retrieval of implicit reasoning.
Experimental Results
Experiments involving ImplexConv underscore its high implicitness compared to existing datasets. ImplexConv exhibits 20% lower semantic similarity between queries and answers, challenging models to rely on deeper reasoning beyond semantic proximity. TaciTree shows 30% higher retrieval accuracy with 40–60% fewer tokens against baseline methods such as RAG and MemoryBank, emphasizing its efficiency in extracting implicit reasoning.
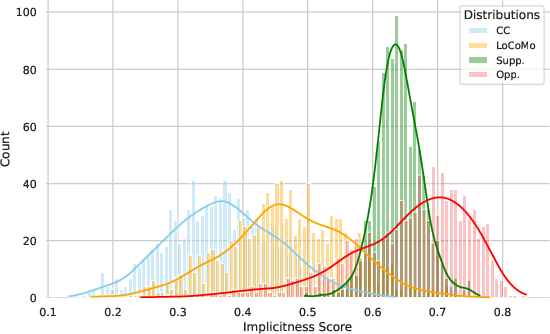
Figure 3: Distribution of implicitness scores across datasets, where Supp. and Opp. represent the supportive and opposed cases of ImplexConv, respectively.
Response Accuracy and Token Efficiency
The analyses demonstrate that increasing retrieved token sizes generally enhances accuracy, although TaciTree achieves a favorable trade-off between retrieval size and response accuracy, ensuring efficient token utilization without sacrificing precision. Opposed implicit reasoning scenarios are specifically analyzed, revealing that stronger LLMs with advanced reasoning capabilities significantly improve response accuracy.
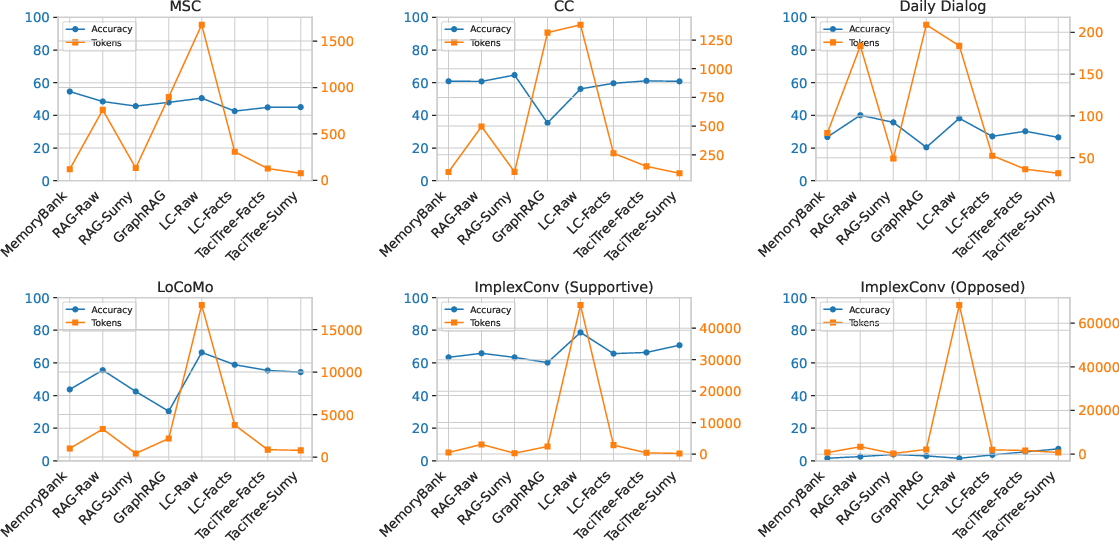
Figure 4: Response accuracy (blue) and retrieved token size (orange) across different frameworks and datasets.
Conclusion
This paper presents a concerted effort to enhance the efficacy of personalized conversations across sessions by introducing ImplexConv and TaciTree. The ImplexConv dataset challenges retrieval-based models with implicit reasoning scenarios, whereas TaciTree provides an efficient hierarchical method for reasoned retrieval in comprehensive dialogue contexts. Future work should focus on integrating adaptive retrieval mechanisms and exploring advanced LLM architectures to deepen AI's capabilities in complex, context-dependent reasoning within extended dialogues.