- The paper presents Demo-SCORE, a method that automates filtering of robot demonstration datasets using online self-curation to enhance imitation learning.
- It employs a four-step process including initial training, rollout evaluation, classifier development, and dataset filtering to identify optimal demonstrations.
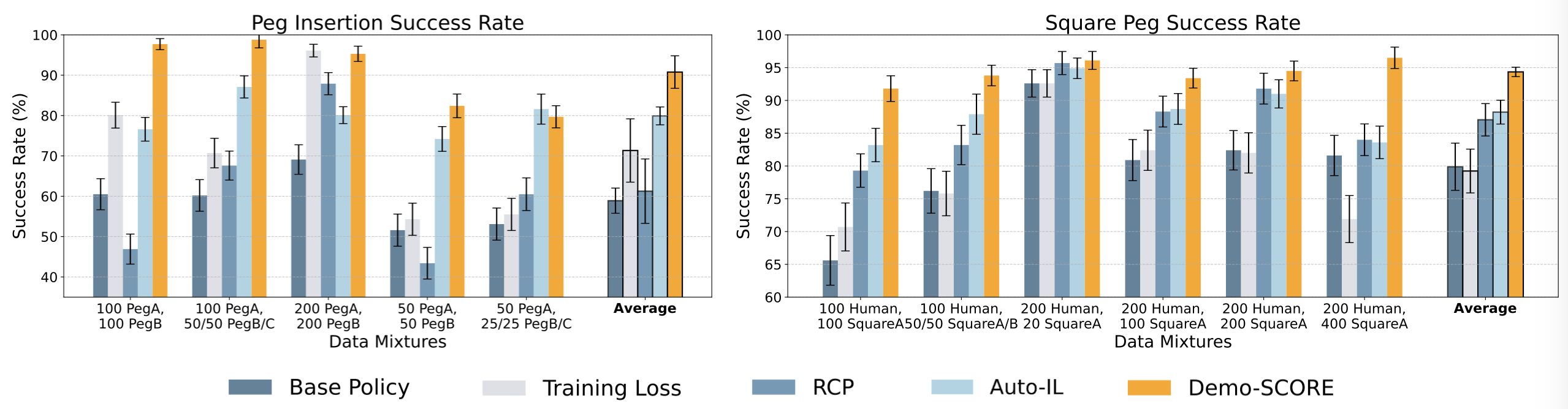
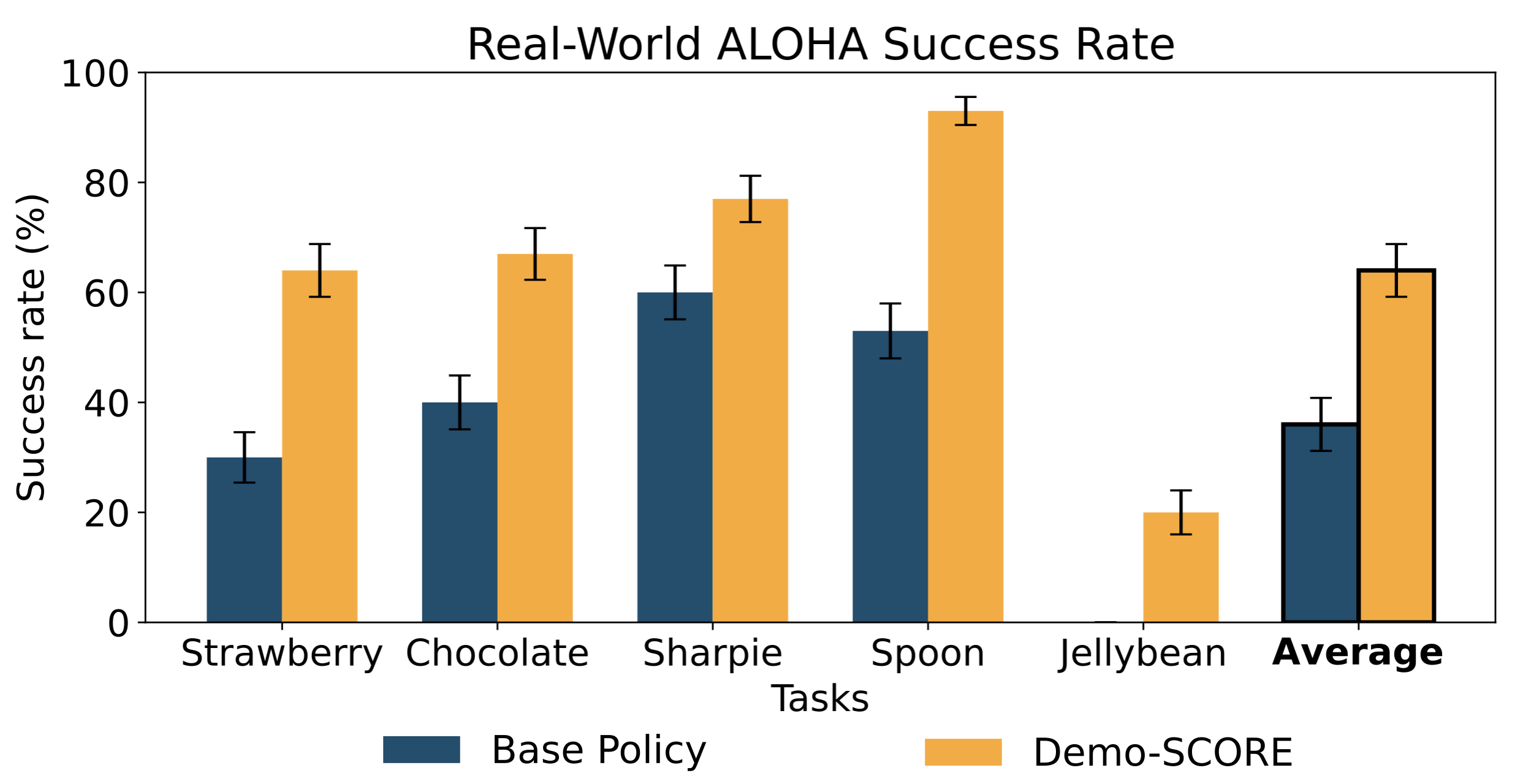
- Experimental results show improvement of 15-35% in simulated tasks and nearly 30% in real-world applications, highlighting its impact on policy success rates.
Curating Demonstrations Using Online Experience
The paper "Curating Demonstrations using Online Experience" presents Demo-SCORE, an approach to automate the filtering of robot demonstration datasets through online self-curation by the robot. This method aims to improve policy performance by identifying and discarding suboptimal demonstrations that are not beneficial for learning reliable imitation strategies.
Introduction
Demo-SCORE addresses the challenge of leveraging heterogeneous demonstration datasets that contain a mix of high and low-quality demonstrations. As robot learning environments become more complex, they necessitate diverse demonstration strategies that might not always be reliable for robots to imitate. Human demonstrations often include suboptimal strategies due to variance in human execution, leading to poor robot performance when uninterpreted.

Figure 1: Human demonstrations can involve unreliable strategies, such as picking up a spoon by its edge, which may not translate effectively to robotic execution.
Methodology
Demo-SCORE automates the curation of demonstration datasets in four key steps:
- Initial Policy Training: A policy is trained on the full set of demonstrations, capturing the variability in strategies.
- Policy Evaluation through Rollouts: Rollouts are conducted at various checkpoints to evaluate policy performance.
- Classifier Development: A classifier is trained using the rollout data to distinguish between successful and failed rollouts, identifying reliable strategies.
- Dataset Filtering: Using the classifier, unreliable demonstrations are filtered out to refine the dataset for further policy training.

Figure 2: Illustration of the Demo-SCORE workflow, including policy training, evaluation, classification, and demonstration filtering.
Experimental Evaluation
The effectiveness of Demo-SCORE was validated through experiments on both simulated and real-world tasks.
Simulated Experiments
Two tasks evaluated were the bimanual peg insertion in the ALOHA environment and the square peg task in Robosuite.
Real-World Tasks
The real-world evaluation was conducted using a multi-task ALOHA setup, which included tasks like spoon placement in a rack and strawberry picking from a cluttered scene.
Robustness and Generalization
In addressing off-distribution (OOD) initial conditions, Demo-SCORE maintains its robustness. Experiments revealed that even with significant changes in initial task setups or when challenged with OOD environments, the refined datasets preserved by Demo-SCORE allowed for effective policy generalization without loss of state coverage.
Conclusion
Demo-SCORE presents a scalable and effective method for enhancing the performance of robots learning from demonstrations by leveraging online experiences to curate datasets. It effectively discerns and eliminates unreliable strategies that human curation may overlook, thereby improving policy success rates across various tasks. Future work includes extending this approach to broader robotic scenarios and refining classifier techniques for more sophisticated demonstration datasets.