- The paper demonstrates that MPPI control can approximate optimal solutions in stochastic settings while addressing deterministic suboptimality.
- It details the categorization of control problems (CLS-OCP, OLS-OCP, DET-OCP) and adapts MPPI strategies accordingly for each case.
- Numerical experiments confirm that deterministic MPPI converges with a quadratic reduction in suboptimality as uncertainty is tuned.
Optimality and Suboptimality of MPPI Control in Stochastic and Deterministic Settings
Introduction
The paper "Optimality and Suboptimality of MPPI Control in Stochastic and Deterministic Settings" (2502.20953) explores Model Predictive Path Integral (MPPI) control and examines its efficacy across various optimal control problems (OCPs). MPPI has gained prominence in robotics and reinforcement learning due to its sample-based nature, which allows parallel execution. Despite its benefits, issues surrounding suboptimality in deterministic contexts remain largely unexplored. This paper aims to bridge MPPI with the optimal control community by presenting distinct problem classes and addressing the suboptimality inherent in deterministic nonlinear discrete-time systems.
Overview of Control Problem Classes
The paper categorizes optimal control problems into three primary classes: Closed-Loop Stochastic Optimal Control (CLS-OCP), Open-Loop Stochastic Optimal Control (OLS-OCP), and Deterministic Optimal Control (DET-OCP).
CLS-OCP
CLS-OCPs focus on minimizing expected costs for systems reacting dynamically to disturbances, optimizing over policies rather than singular input trajectories. This class is typically challenging due to its inherent need for real-time feedback mechanisms during optimization.
OLS-OCP
OLS-OCPs offer a feasible alternative by optimizing the expected costs for systems over finite trajectories without adjusting for real-time disturbances. Although computationally simpler, OLS-OCPs are inherently suboptimal for closed-loop settings.
DET-OCP
DET-OCPs represent the nominal control problem, devoid of stochasticity, often resulting in local solutions due to constraints and non-linearities. The paper investigates how MPPI performs in this deterministic setting, particularly focusing on suboptimality factors.
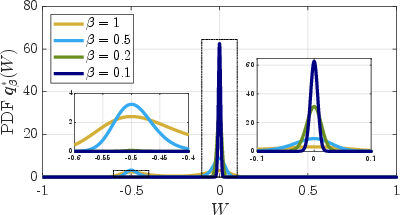
Figure 1: PDF of optimal distribution Qβ⋆(W) for different β. The two additional interior plots show zoomed sections of the same PDF.
MPPI Control Methods
The MPPI framework is adapted to address each of the control problem classes, showcasing its flexibility in both stochastic and deterministic environments.
Stochastic MPPI
For stochastic settings, the paper explores MPPI's origins within input-affine systems and cost structures conducive to path integral approaches. Under specific assumptions, MPPI can approximate solutions to CLS-OCPs by leveraging exponential transformations akin to solving PDEs. The framework achieves tractable computational models by aligning uncertainty within controlled trajectories.
Deterministic MPPI
In deterministic contexts, MPPI introduces intentional stochasticity for trajectory exploration. The paper demonstrates the convergence of deterministic MPPI to exact solutions of DET-OCPs, with suboptimality modulated by hyperparameter tuning. Through theoretical analysis, it asserts that suboptimality diminishes at a quadratic rate relative to injected uncertainty.
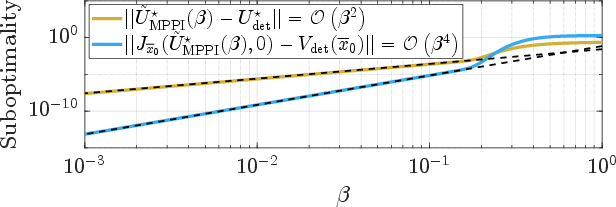
Figure 2: Suboptimality of the MPPI solution to the DET-OCP of the controls (gold) and the value function (blue).
Implications and Computational Effort
A critical observation pertains to the computational cost associated with MPPI and alternative optimization methods. MPPI's parallel sampling capabilities prove beneficial for real-time applications, despite potential increases in computational overhead compared to Newton-type optimization. The framework's performance, notably under deterministic settings, suggests potential applicability in real-world scenarios where efficiency balances scalability.
Numerical Experiments
Numerical experiments corroborate the theoretical framework by showcasing the efficacy of deterministic MPPI in simple and complex OCPs. Results highlight the framework's adaptability to distinct dynamics types, reaffirming the paper's claims regarding convergence and suboptimality control.
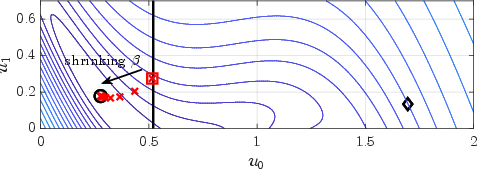
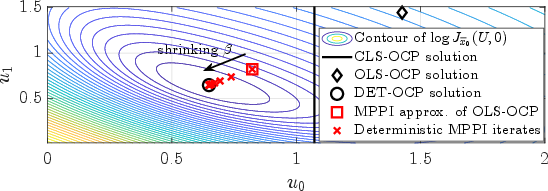
Figure 3: Numerical solutions to the three different problems DET-OCP, OLS-OCP, and CLS-OCP (black), all with overall cost function \eqref{eq_ex2} based on input-affine dynamics faf (top) and nonlinear dynamics fnl (bottom) alongside the iterates of deterministic MPPI.
Conclusion
The paper extends understanding of MPPI within optimal control, particularly its role in deterministic settings. By reconciling stochastic and deterministic approaches, it provides valuable insights into tuning MPPI for minimizing suboptimality. The findings advocate for MPPI's nuanced application in both theoretical analysis and practical deployment, fostering its integration within broader control methodologies.