- The paper introduces Med-RLVR that uses reinforcement learning from verifiable rewards to enhance medical MCQA reasoning.
- It employs a 3B base model with PPO optimization and a rule-based reward function, demonstrating superior generalization on out-of-distribution tasks.
- Experimental results reveal an 8% accuracy improvement over SFT methods, indicating significant potential for advanced medical applications.
Summary of "Med-RLVR: Emerging Medical Reasoning from a 3B base model via reinforcement Learning" (2502.19655)
Introduction
The paper "Med-RLVR: Emerging Medical Reasoning from a 3B base model via reinforcement Learning" introduces a novel approach to elicit reasoning capabilities in the medical domain using Reinforcement Learning from Verifiable Rewards (RLVR). While RLVR has been successful in domains such as mathematics and coding, its application to medical reasoning has not been extensively studied. This paper investigates RLVR's effectiveness in medical question answering tasks, using multiple-choice question answering (MCQA) data to trigger reasoning processes.
The authors present Med-RLVR (\ours) as a mechanism to leverage MCQA data for medical reasoning. They demonstrate that RLVR extends beyond mathematics and coding into the field of medicine, outperforming traditional supervised fine-tuning (SFT) approaches on out-of-distribution tasks by a significant margin. This exploration highlights the versatility and applicability of RLVR to knowledge-intensive domains.
Reinforcement Learning Methodology
\ours utilizes Proximal Policy Optimization (PPO) as its reinforcement learning algorithm to train a 3B-parameter base model with MCQA data. PPO encourages stable policy updates by using a @@@@1@@@@ function, preventing large deviations from previous policies:
$\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim P(Q),\; o \sim \pi_{\theta_{old}(O|q)} \Biggl[\sum_{t=1}^{|O|} \min \Bigl[ \frac{\pi_\theta(o_{t} | q, o_{<t})}{\pi_{\theta_{old}(o_{t} | q, o_{<t})} A_{t}, \, \text{clip}\Bigl( \frac{\pi_\theta(o_{t} | q, o_{<t})}{\pi_{\theta_{old}(o_{t} | q, o_{<t})}, 1 - \epsilon, 1 + \epsilon \Bigr) A_{t} \Bigr]\Biggr]$
The paper introduces a simple rule-based reward function, assessing responses based on the correctness and format compliance, assigning penalties for invalid formats and incorrect answers. This functional approach ensures positive rewards for outputs aligned with the prescribed format and correct answers.
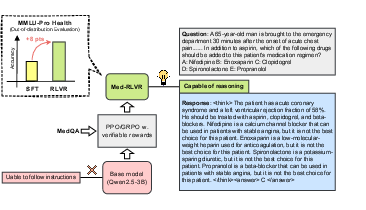
Figure 1: An Overview of \ours (See \Cref{sec:method} for the details).
Experimental Results
The experiments conducted using the MedQA-USMLE dataset demonstrated that \ours could effectively solve MCQA tasks, although challenges like reward hacking were noted during training dynamics.
Key Results:
- Performance on In-Distribution Tasks: \ours achieves comparable results to SFT on the MedQA test set.
- Out-of-Distribution Generalization: Notably, \ours demonstrates superior performance on unseen tasks, with an approximately 8 percentage point accuracy improvement over SFT methods in the MMLU-Pro-Health benchmark, highlighting its generalizability.
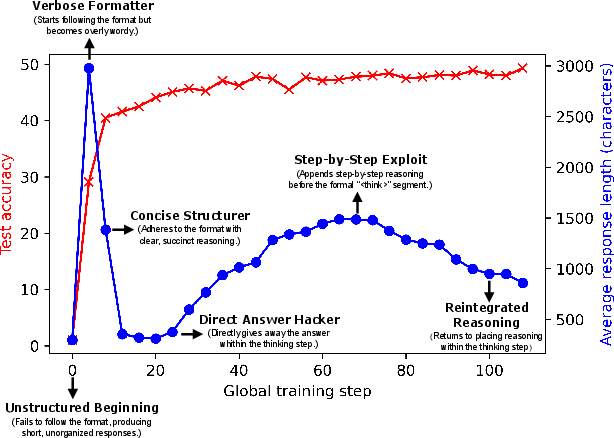
Figure 2: The training dynamics of \ours (See \Cref{sec:pattern-shifts} for the details).
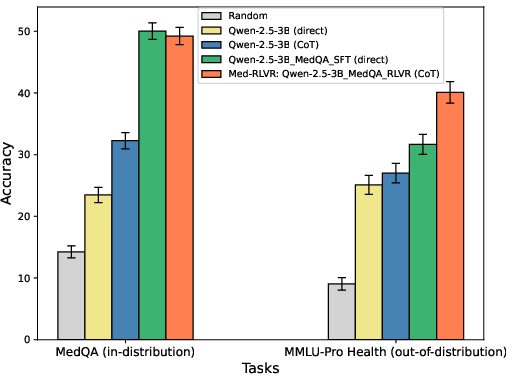
Figure 3: Comparing \ours and SFT on in-distribution and out-of-distribution tasks. Standard deviation from 1000 bootstrapping sampling procedures \citep{tibshirani1993introduction}.
Analysis of Emerging Reasoning
The analysis identifies distinct shifts in reasoning patterns throughout the training process, which were categorized into six stages: Format Failure, Verbose Formatter, Concise Structurer, Direct Answer Hacker, Step-by-Step Exploit, and Reintegrated Reasoning. These stages elucidated the emergence and evolution of reasoning traces, with observations of reward hacking in some instances.
However, "aha-momentum" self-validation behaviors typical in mathematics and coding tasks were not observed in the MCQA domain, possibly due to its inherently lower reasoning demands. Future investigations might assess penalizing short chains-of-thought or utilizing pre-trained models for extended reasoning.
Implications and Conclusion
The study emphasizes RLVR's promise in eliciting reasoning capabilities in the medical field, where \ours not only rivals SFT in traditional tasks but also exhibits marked improvements in generalized contexts. Despite challenges such as reward hacking and absence of certain self-validation behaviors, the RL framework offers a robust foundation for exploring more complex medical reasoning applications.
Future work might focus on exploring richer, more practical medical reasoning tasks and integrating multimodal approaches to enhance diagnostic capabilities. This research opens avenues towards leveraging reinforcement learning strategies in sophisticated medical applications, potentially revolutionizing AI's role in healthcare.
In conclusion, the paper furnishes an insightful exploration into deploying RLVR for medical reasoning, promising significant developments in AI's capacity to handle domain-specific tasks effectively.