- The paper introduces an RL agent that dynamically optimizes teacher weights to enhance the student network's performance.
- MTKD-RL balances varied teacher contributions using metrics like logits and feature divergence, significantly boosting classification accuracy.
- Experimental results on datasets like CIFAR-100 and ImageNet demonstrate superior performance over traditional static-weight knowledge distillation.
Overview of "Multi-Teacher Knowledge Distillation with Reinforcement Learning for Visual Recognition" (2502.18510)
This paper presents Multi-Teacher Knowledge Distillation with Reinforcement Learning (MTKD-RL), a framework designed to optimize teacher weights in a multi-teacher knowledge distillation (KD) context for visual recognition tasks. The core innovation lies in using reinforcement learning (RL) to dynamically adjust the influence of each teacher on the student model, thereby improving the overall performance of the student network beyond what single-teacher KD architectures can achieve.
Methodology
Multi-teacher KD aims to impart knowledge from multiple pre-trained teacher networks to a single student network. This necessitates a strategy to balance the contribution of each teacher, traditionally approached by assigning equal weights. However, this ignores the performance variance across different teachers and the adaptability of the student network to each teacher's guidance. MTKD-RL resolves this by framing the task as an RL problem, where an agent calculates weighted contributions dynamically.
MTKD-RL Framework
The MTKD-RL framework constructs state information based on teacher performance metrics (such as logits and features) and discrepancies (like teacher-student feature divergence). The agent, informed by this state, determines teacher weightings, optimizing them to maximize the reward—measured as the improved performance of the student network post-distillation.
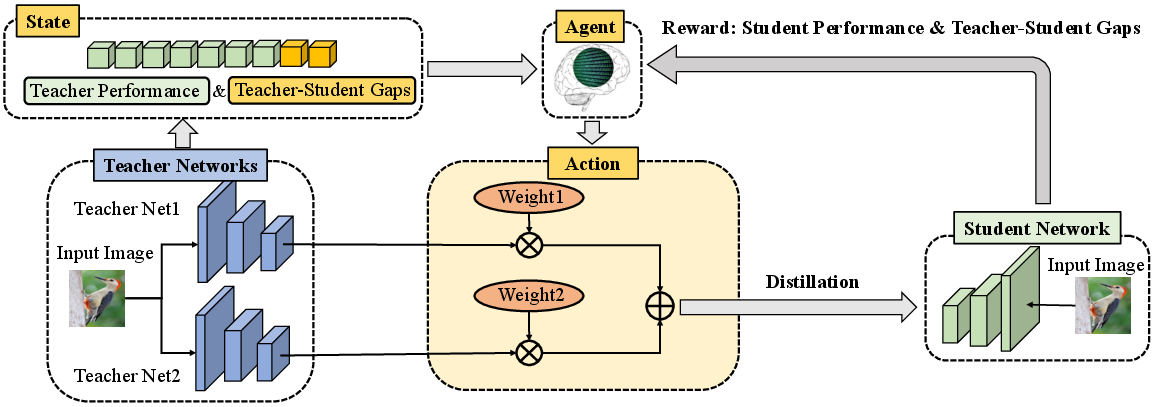
Figure 1: Overview of the basic idea about our proposed MTKD-RL.
Reinforcement Learning Approach
The agent in MTKD-RL is trained using the policy gradient method, which updates the agent's policy based on the reward obtained from the student's performance improvements. The input to the agent includes:
- Teacher feature representations
- Logit outputs
- Cross-entropy losses from teachers
- Feature similarity and logit divergence between each teacher and the student.
Reward Design and Optimization Strategy
The reward function primarily focuses on minimizing the classification error of the student while maximizing the alignment between the student's and teachers' outputs. This approach ensures that only beneficial knowledge is distilled from the teachers to the student.
Experimental Results
Image Classification
MTKD-RL was evaluated on datasets like CIFAR-100 and ImageNet, demonstrating superior performance over both traditional and contemporary multi-teacher KD methods. For instance, on CIFAR-100, MTKD-RL surpassed baseline KD methods with notable accuracy improvements.
Object Detection and Semantic Segmentation
Beyond image classification, MTKD-RL also enhanced models in object detection and semantic segmentation tasks, suggesting that distillation can enhance feature representation for dense predictions.
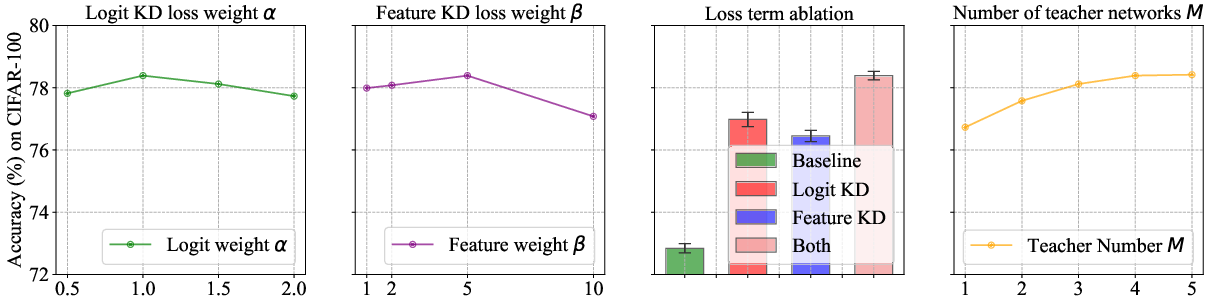
Figure 2: Parameter analyses and ablation study over ShuffleNetV2 on CIFAR-100.
Implementation Details
The implementation involves pre-training the student with equal teacher weights initially, then refining through RL where the agent optimizes weights iteratively based on state-reward feedback loops.
A comparative analysis of resource efficiency highlighted that while MTKD-RL incurs additional computational overhead compared to static-weight models, the improved accuracy justifies the trade-off for scenarios where precision is crucial.
Parametric Sensitivity
MTKD-RL's robustness across variations in teacher network configurations and hyperparameters was verified, demonstrating stable improvements across different settings.
Conclusion
The research provides a pragmatic approach to optimizing knowledge distillation from multiple teachers through an RL framework. By integrating dynamic weighting mechanisms via an RL agent, MTKD-RL offers a well-rounded tool for enhancing various visual recognition tasks. Future explorations might explore integrating even more sophisticated RL models or expanding to broader application areas.