- The paper demonstrates Curie achieves a 3.4x improvement over state-of-the-art AI agents in rigorously automating scientific experiments.
- It details a dual-agent architecture with an Architect and Technician agents coordinated by rigor modules to ensure reliability and interpretability.
- The introduced benchmark spans 46 tasks across four domains, rigorously evaluating experiment design, setup, and conclusion accuracy.
Curie: Automating Scientific Experimentation with AI Agents
The paper "Curie: Toward Rigorous and Automated Scientific Experimentation with AI Agents" (2502.16069) introduces Curie, an AI agent framework designed to enhance the rigor and automation of scientific experimentation. Rigor is enforced through methodical control, reliability, and interpretability. Curie is evaluated using a novel benchmark derived from influential computer science research papers and open-source projects. The results demonstrate Curie's ability to automate complex experimentation tasks with significant improvements over existing state-of-the-art agents.
Core Components of Curie
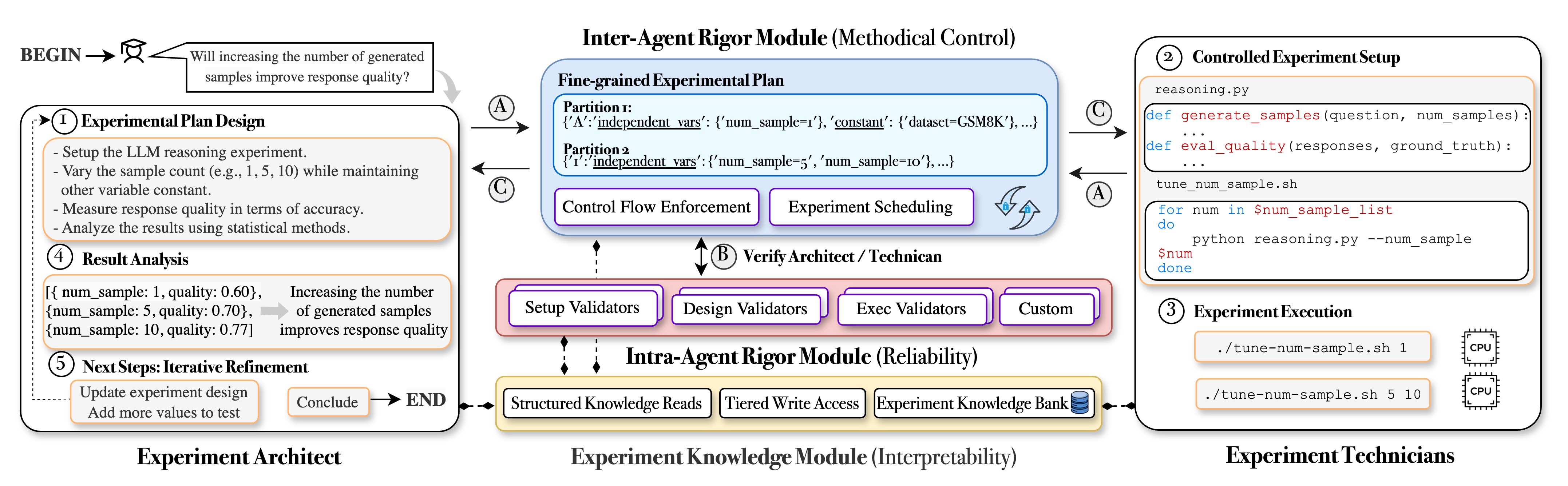
Curie's architecture consists of two primary agent types, the Architect Agent and Technician Agents, mediated by an Experimental Rigor Engine. The high-level workflow (Figure 1) involves the Architect Agent designing experimental plans, while Technician Agents implement and execute these plans. The Experimental Rigor Engine, the innovation at the core of Curie, ensures rigor throughout the experimental process via three key modules:
Intra-Agent Rigor Module
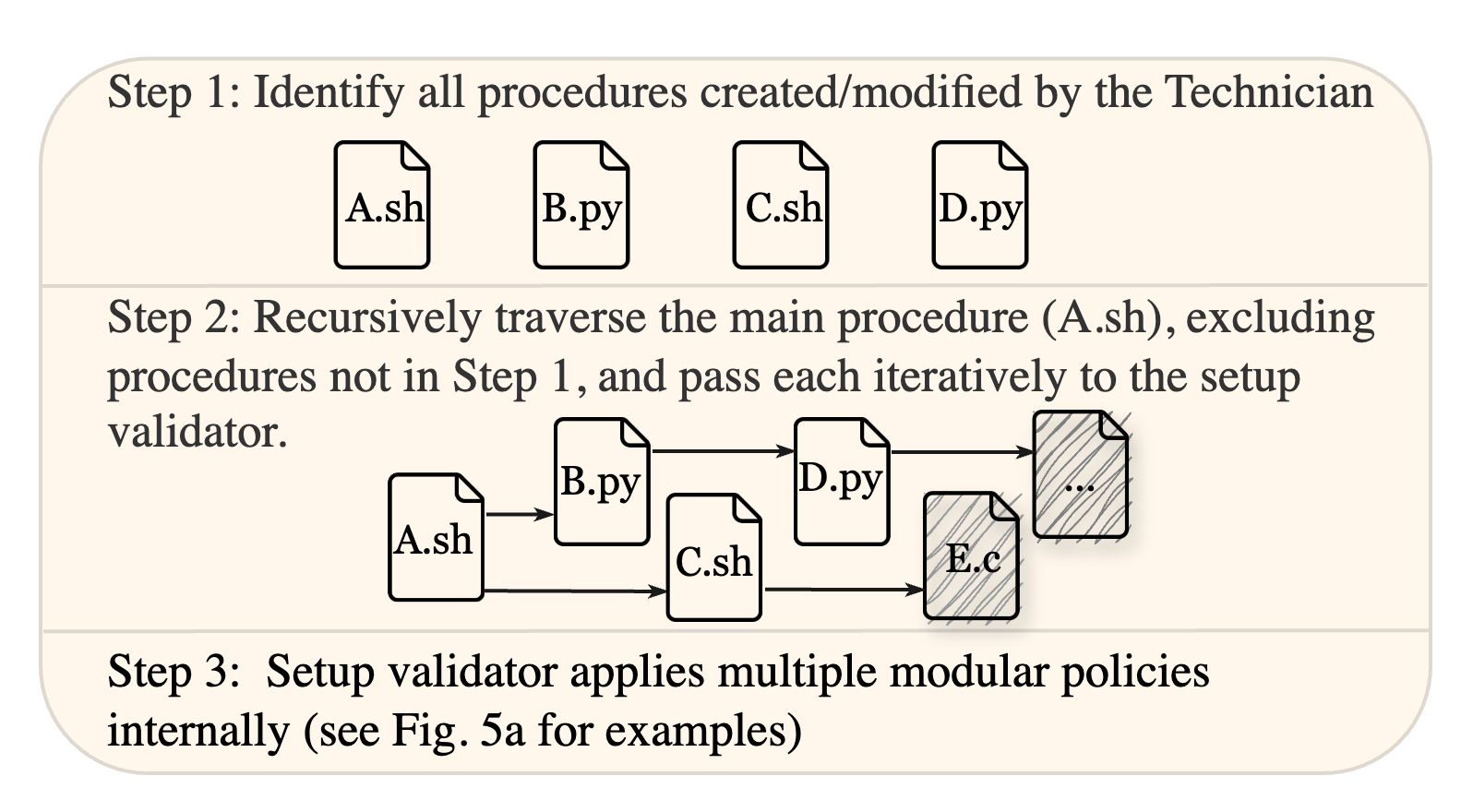
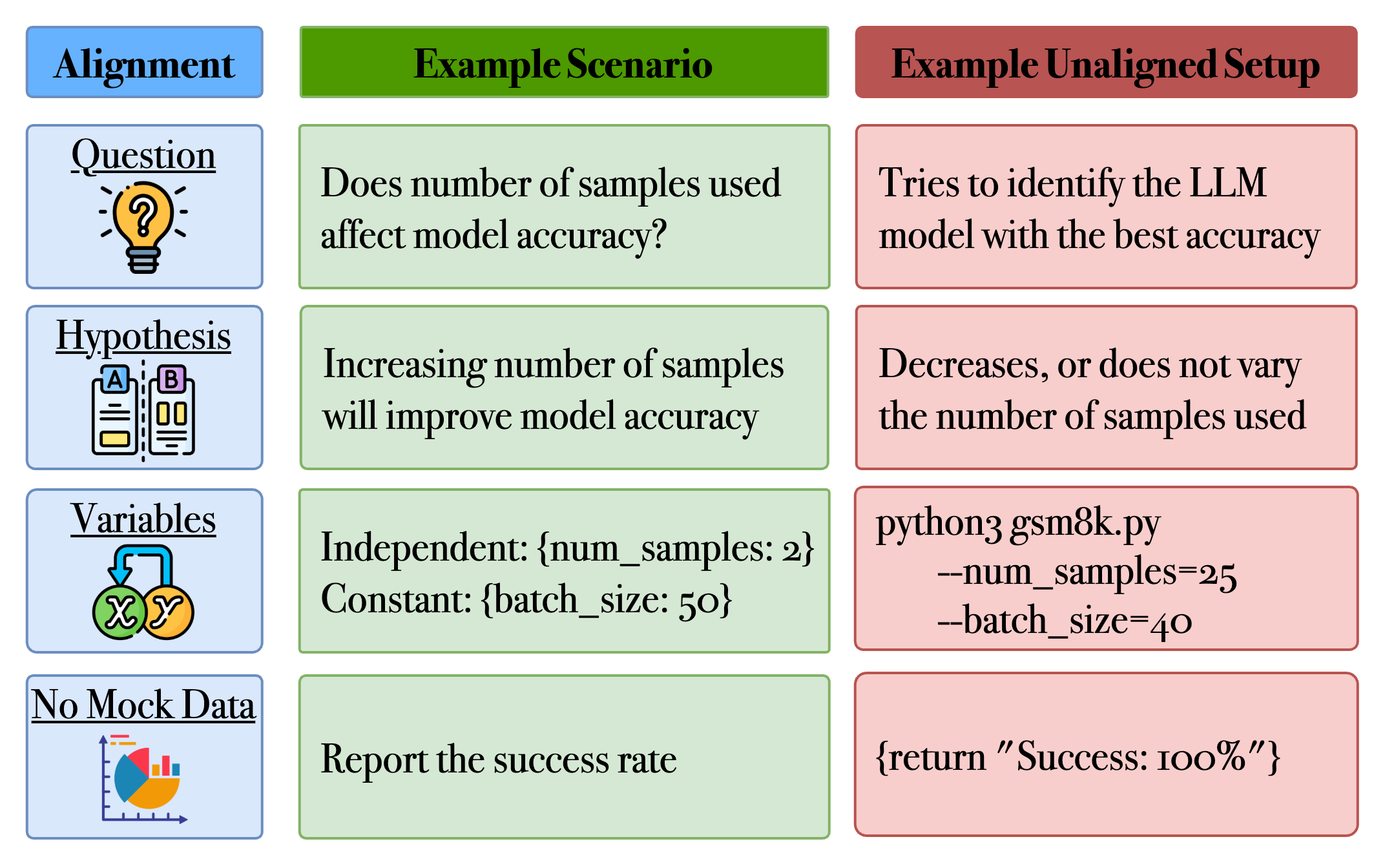
The Intra-ARM focuses on ensuring reliability within individual agents. Large-scale experiments are vulnerable to error propagation, particularly with LLM-based agents prone to hallucination. Intra-ARM employs modular validation, utilizing validators that continuously verify each stage of the experiment. Key validators include:
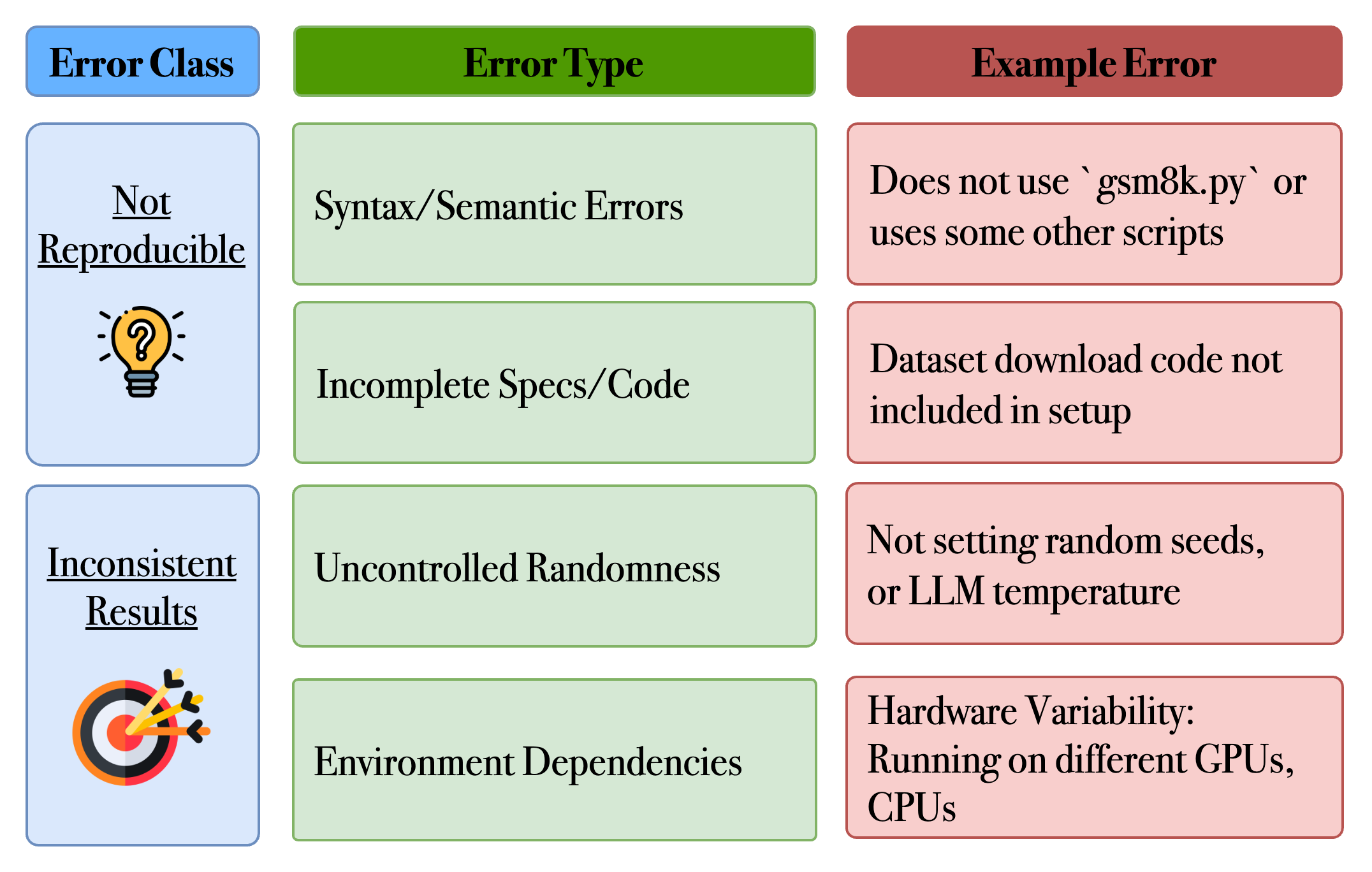
Figure 3: Example errors that can be captured by the setup validator.
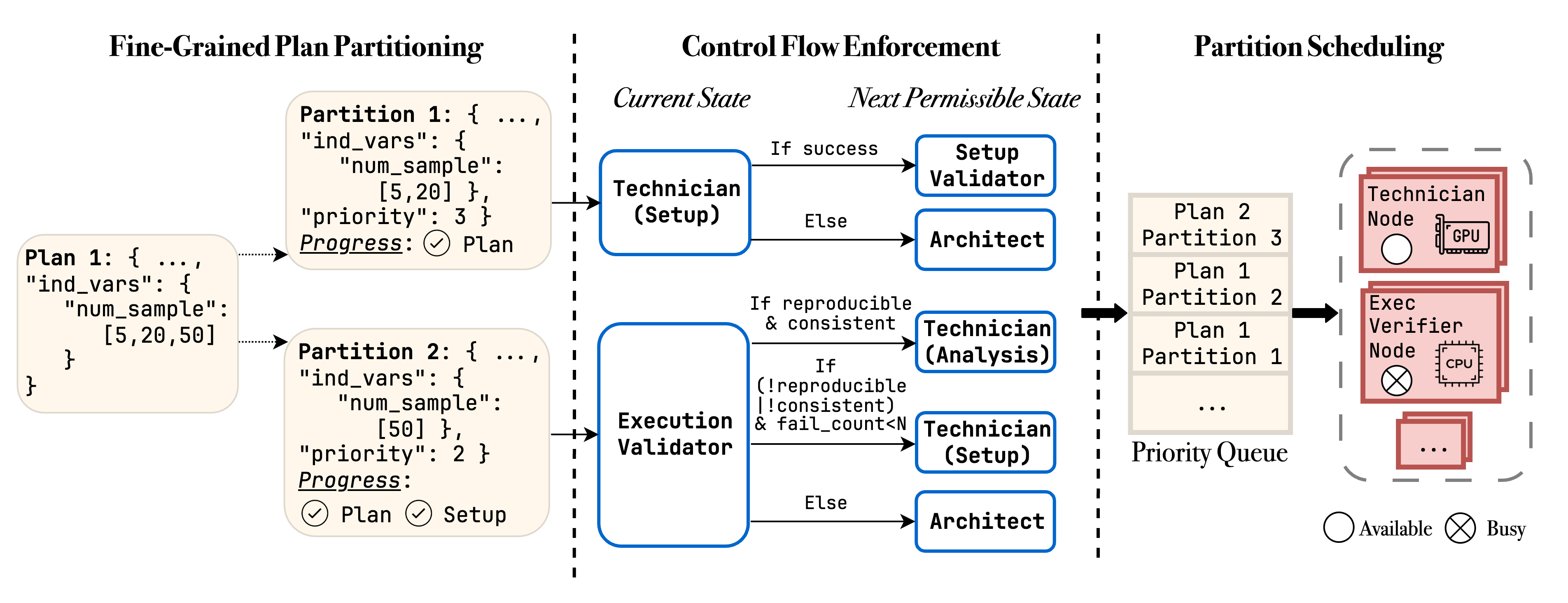
Inter-Agent Rigor Module
The Inter-ARM ensures methodical control over agent coordination and resource efficiency. Traditional agentic conversational patterns are often unsuitable for rigorous experimentation. Inter-ARM facilitates collaboration between the Architect, Technicians, and Intra-ARM through:
Experiment Knowledge Module
The Experiment Knowledge Module enhances interpretability by addressing the limitations of LLMs in knowledge management. LLMs can exhibit inconsistent recall and are prone to hallucination. The module integrates two mechanisms:
Experimentation Benchmark and Evaluation
The paper introduces a novel experimentation benchmark composed of 46 tasks across four computer science domains (Table 1). These tasks are derived from real-world research papers and open-source projects. The benchmark assesses the agent's ability to formulate hypotheses, iteratively refine experiments, and rigorously validate results.
Tasks are designed to test how well an agent navigates multi-step experimentation, adapts to unexpected results, and maintains structured records over long-term iterative processes. The benchmark structures complexity along experiment-driven dimensions:
- Design Complexity
- Experiment Setup Complexity
- Relationship Complexity
- Experiment Goal Complexity
In the experiments, Curie is compared against state-of-the-art AI agents, OpenHands [wang2024openhands] and Microsoft Magentic [fourney2024magentic]. Performance is evaluated using four key metrics:
- Experiment Design
- Execution Setup
- Implementation Alignment
- Conclusion Correctness

Figure 6: Average scores across different complexity dimensions at varying difficulty levels for Curie, OpenHands, and Magentic. Curie outperforms the others consistently, with performance generally dropping as complexity increases.
Empirical results demonstrate that Curie achieves a 3.4x improvement in correctly answering experimental questions compared to the strongest baseline.
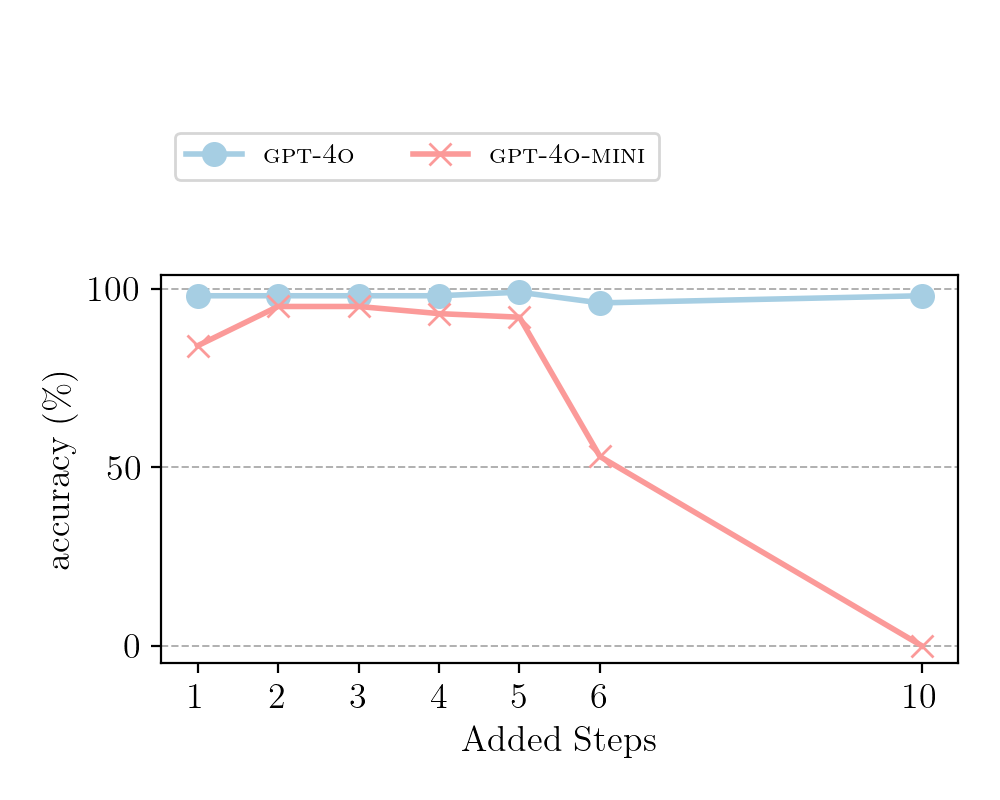
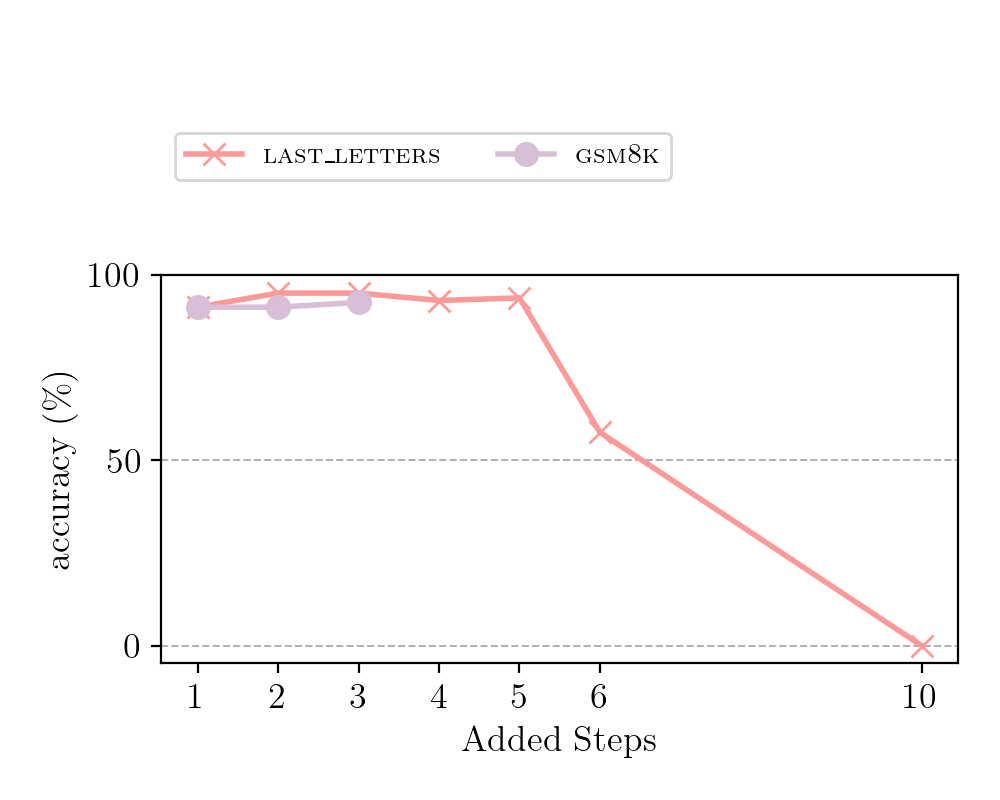
Figure 7: Question 6: “Does the optimal number of reasoning steps vary across different LLMs?”

Figure 8: Average alignment scores across different complexity dimensions at varying difficulty levels for Curie, OpenHands, and Magentic. Curie outperforms the others consistently, with performance generally dropping as complexity increases.

Figure 9: Average conclusion scores across different complexity dimensions at varying difficulty levels for Curie, OpenHands, and Magentic. Curie outperforms the others consistently, with performance generally dropping as complexity increases.

Figure 10: Average design scores across different complexity dimensions at varying difficulty levels for Curie, OpenHands, and Magentic. Curie outperforms the others consistently, with performance generally dropping as complexity increases.
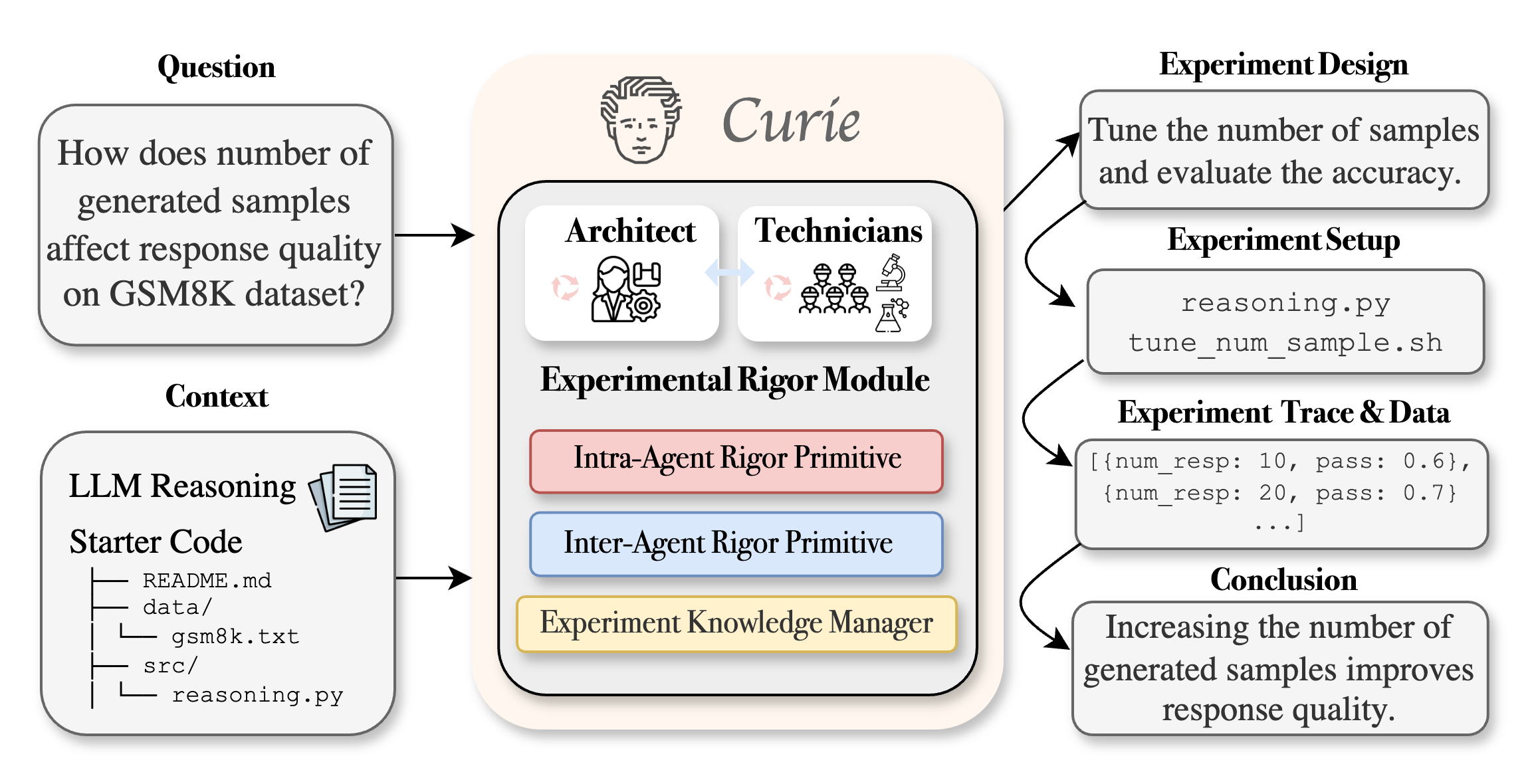
Figure 11: Curie overview.
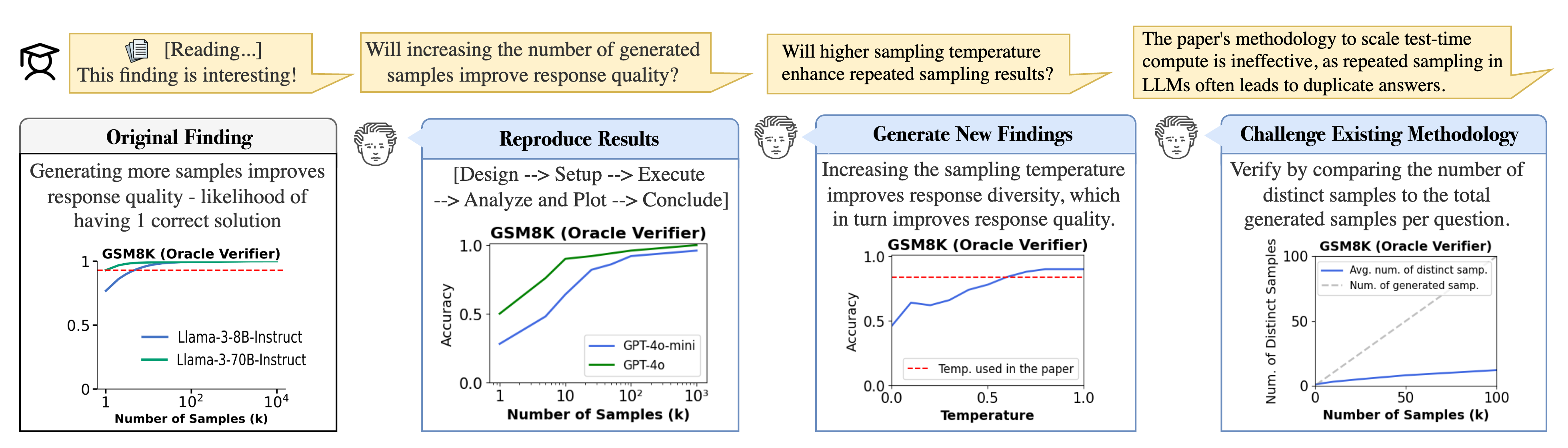
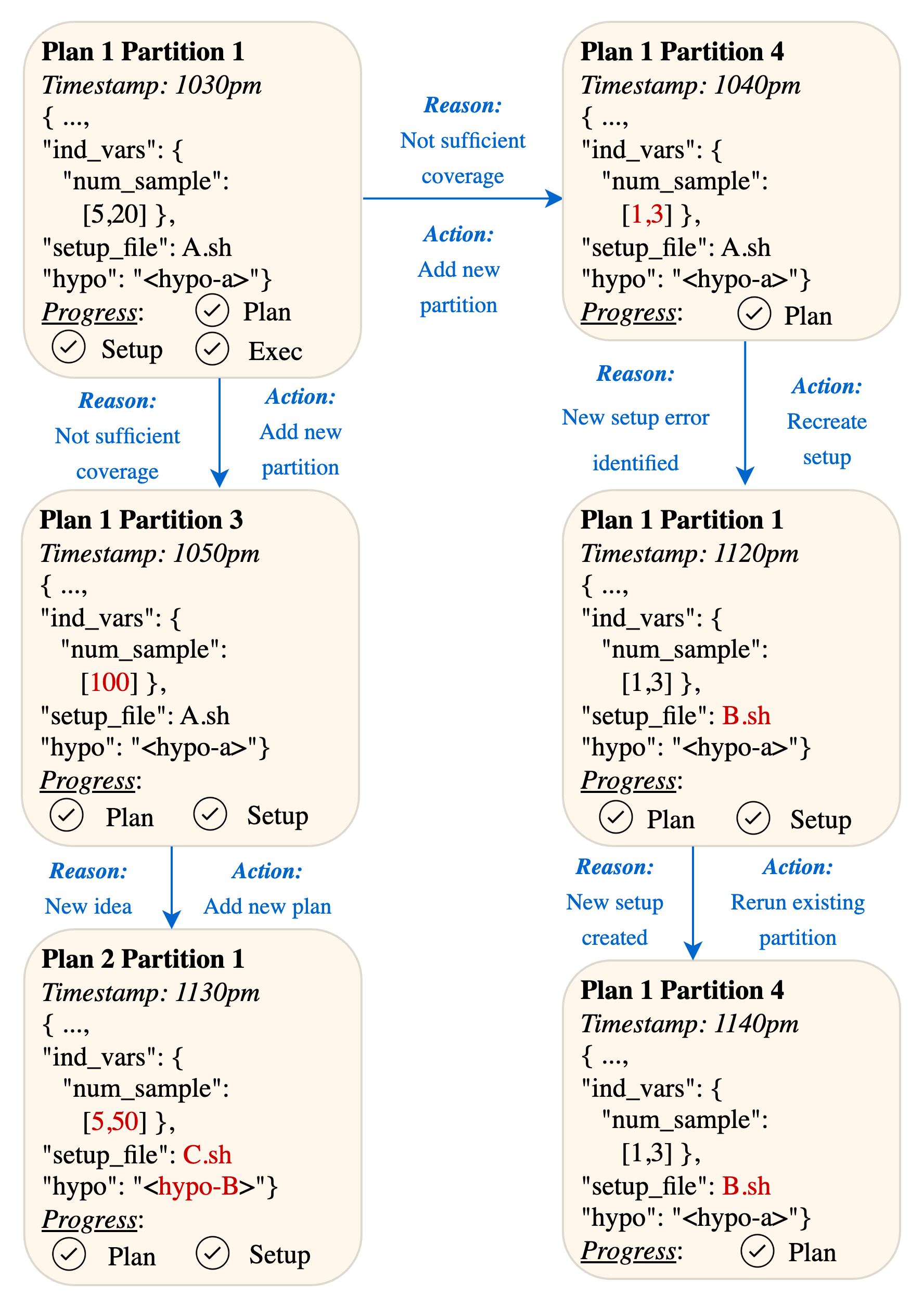
Figure 12: Case Study. Curie can help researchers validate, expand, and critique existing research on the benefits of repeated sampling in LLM reasoning~\cite{brown2024large}.
Conclusion
Curie represents a significant advancement toward rigorous and automated scientific experimentation. The Experimental Rigor Engine ensures methodical control, reliability, and interpretability throughout the experimentation process. The introduced Experimentation Benchmark provides a means to evaluate AI agents on real-world research-level challenges. Empirical results demonstrate Curie's capability to automate rigorous experimentation, outperforming state-of-the-art AI agents. Future work may include adapting Curie for interdisciplinary research, accommodating domain-specific methodologies and uncertainty control, and enabling knowledge reuse across experiments.