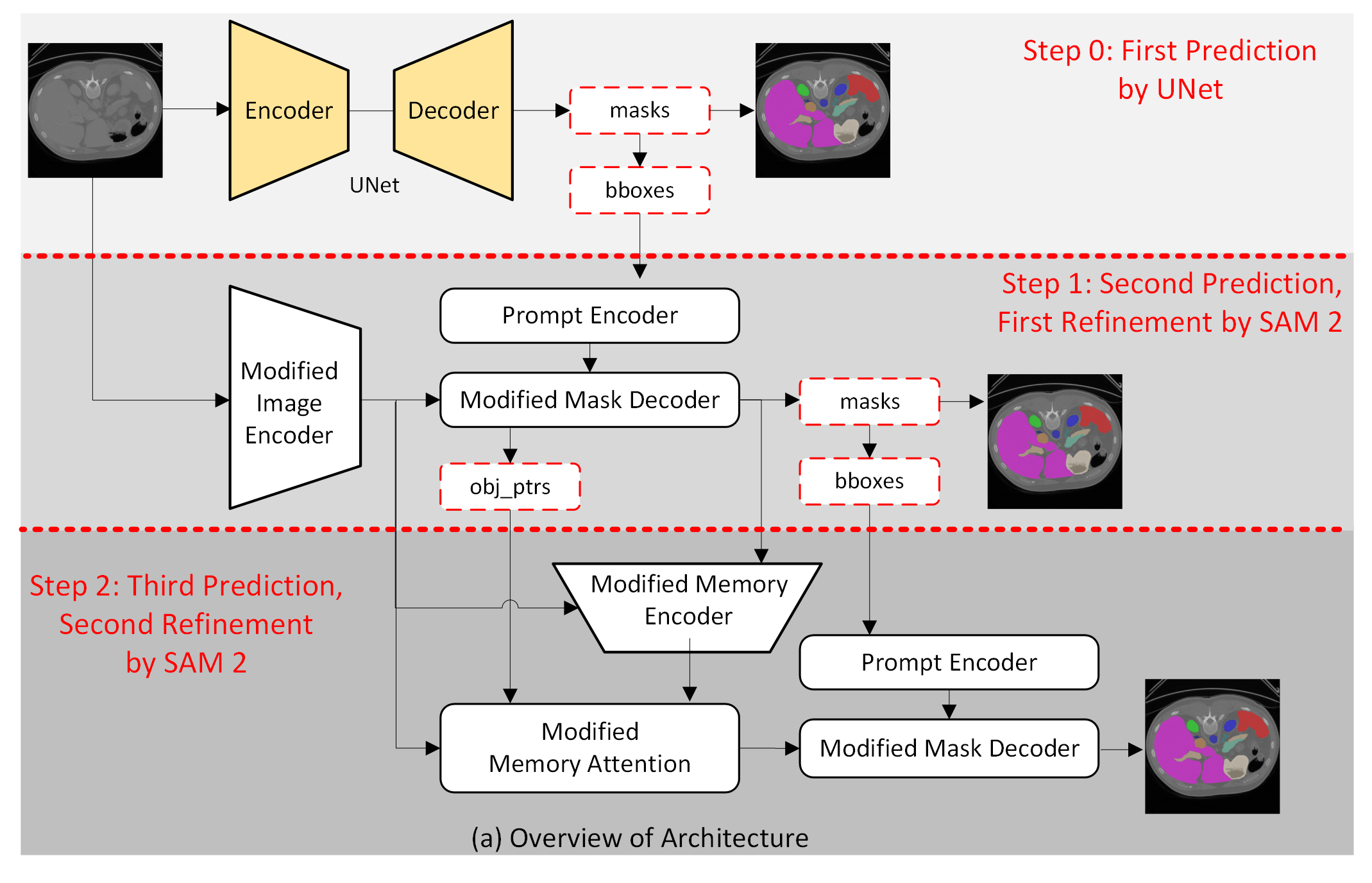
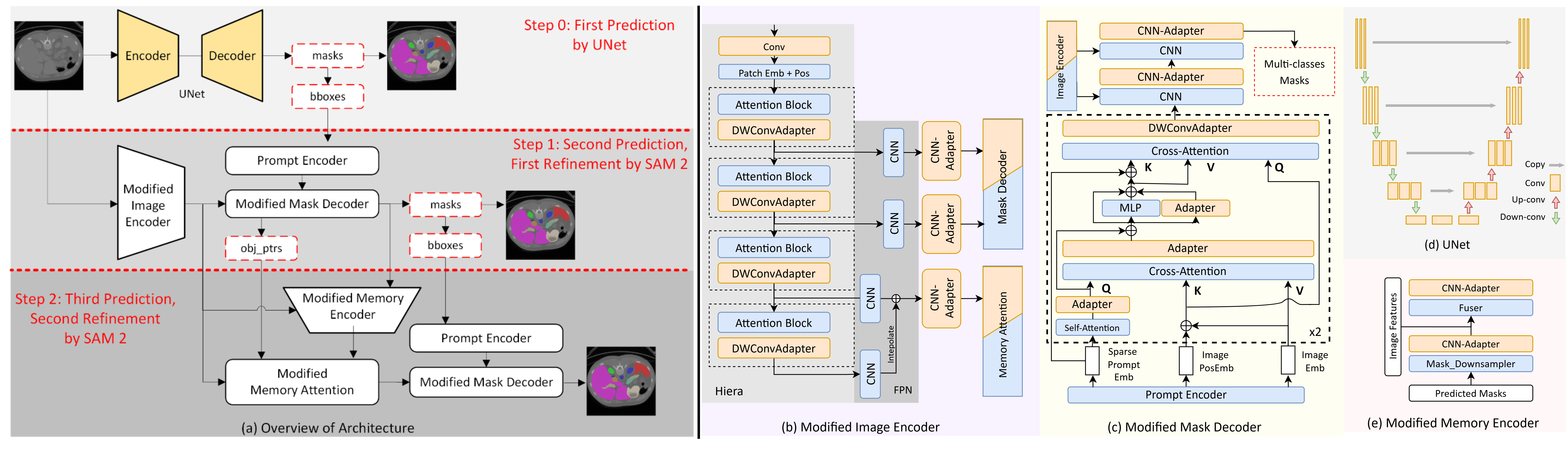
- The paper introduces RFMedSAM 2, a framework that refines SAM 2 prompts to enhance volumetric medical image segmentation with a dual-stage refinement process.
- It integrates a U-Net based initial prediction, novel adapter modules (DWConvAdapter and CNN-Adapter), and modified attention mechanisms to improve segmentation accuracy.
- Empirical evaluation on the BTCV dataset shows a Dice Similarity Coefficient of 92.30%, indicating significant performance gains over state-of-the-art models.
Overview of "RFMedSAM 2: Automatic Prompt Refinement for Enhanced Volumetric Medical Image Segmentation with SAM 2"
This essay explores the advancements presented in the paper "RFMedSAM 2: Automatic Prompt Refinement for Enhanced Volumetric Medical Image Segmentation with SAM 2". The paper addresses the challenges in medical image segmentation, particularly the limitations of the Segment Anything Model 2 (SAM 2) when applied directly to medical imaging contexts. It proposes RFMedSAM 2, a novel framework designed to refine the prompt requirements of SAM 2, thereby enhancing its performance in volumetric medical image segmentation tasks.
Background and Motivation
The need for precise and efficient medical image segmentation is paramount in medical diagnostics, treatment planning, and surgical preparation. Traditional models like SAM while adaptable to various segmentation tasks, face limitations in generating semantic labels and rely heavily on precise prompting, which affects their efficacy in complex domains such as medical imaging. SAM 2 improves upon its predecessor by extending functionality to video domains, yet it still suffers from similar pitfalls when applied out of the box to medical datasets.
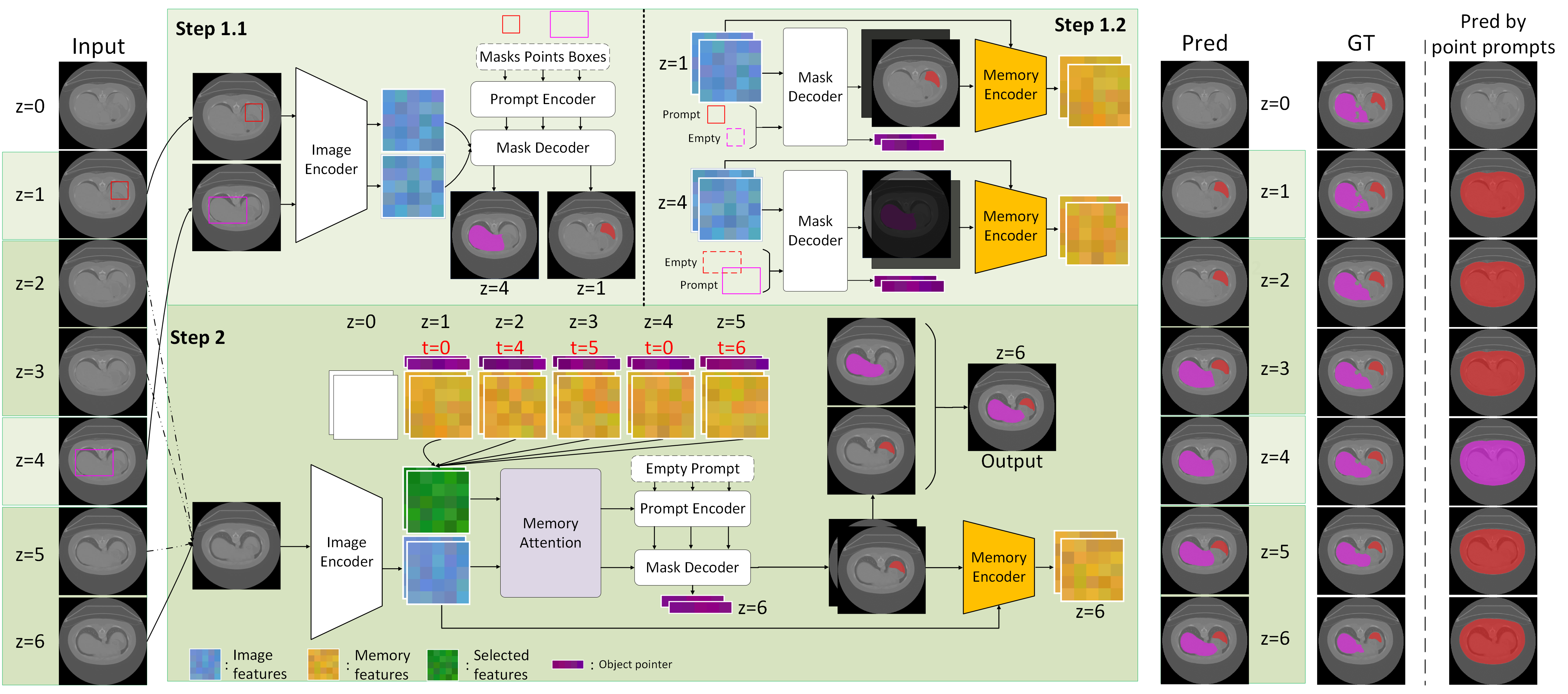
Figure 1: Overview of SAM 2. The pipeline includes steps for processing prompted and unprompted frames.
RFMedSAM 2 Architecture
RFMedSAM 2 presents a refined architecture that integrates additional components to mitigate the prompt dependency and enhance performance:
Technical Contributions
- Novel Adapter Modules:
- DWConvAdapter: Enhances attention blocks within the image encoder to better capture spatial information essential for volumetric data.
- CNN-Adapter: Adapts convolutional layers in SAM 2, facilitating efficient fine-tuning without exhaustive retraining requirements.
- Enhanced Prompt Generation:
Empirical Findings
RFMedSAM 2's efficacy is underscored by empirical evaluations on medical imaging datasets. On the BTCV dataset, it achieved a Dice Similarity Coefficient (DSC) of 92.30%, outperforming the previous state-of-the-art nnUNet by a notable margin. This performance leap is attributable to the architectural innovations and novel prompt generation strategies posited in the study.
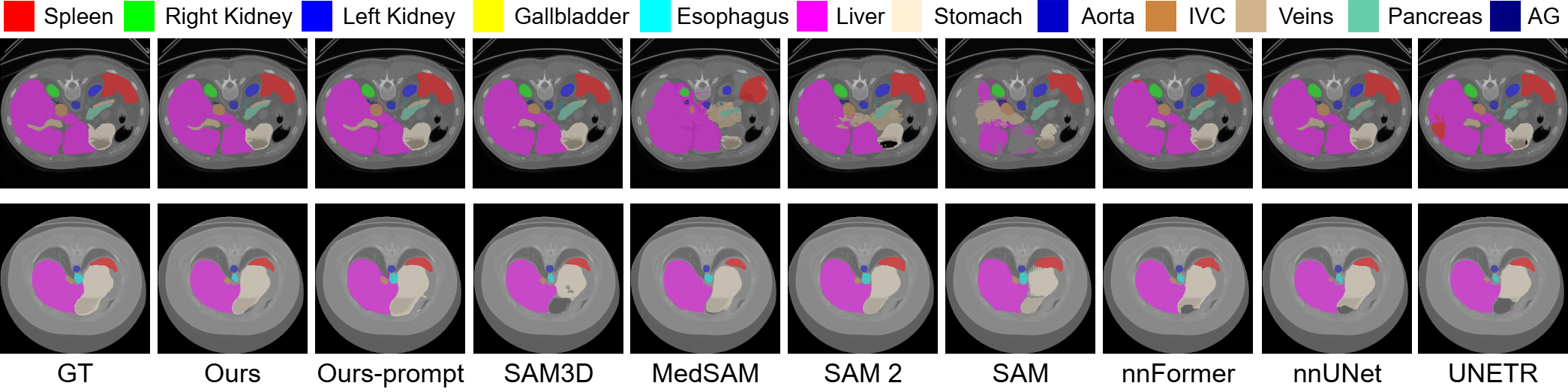
Figure 4: Qualitative comparison on BTCV dataset. RFMedSAM 2 is the most precise for each class and has fewer segmentation outliers.
Implications and Future Directions
The introduction of RFMedSAM 2 marks a significant stride in adapting generalized models to the specialized domain of medical imaging. Its ability to leverage SAM 2's foundational strengths, while integrating domain-specific adjustments, paves the path for more refined applications in other medical imaging modalities, such as MRI and ultrasound. Future research could explore its deployment in real-time clinical settings, potentially revolutionizing diagnostic processes through automated segmentation.
Conclusion
RFMedSAM 2 represents an advanced integration of segmentation techniques tailored to medical imaging challenges, offering significant improvements over existing models. By reducing dependency on precise prompts and incorporating sophisticated refinement mechanisms, it establishes a new benchmark for volumetric medical image segmentation. As AI continues to evolve, such frameworks will be essential in harnessing the full potential of deep learning in healthcare and medical diagnostics.