- The paper introduces Vid2Sim, a framework that converts monocular video into geometry-consistent 3D simulation environments to narrow the sim-to-real gap.
- It employs neural scene reconstruction with hybrid scene representations, combining Gaussian Splatting with mesh primitives for photo-realistic visuals and accurate collision detection.
- Experimental results demonstrate enhanced success rates and reduced collisions in urban navigation, validating its robust reinforcement learning applications.
Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation
Vid2Sim introduces a new paradigm for bridging the sim-to-real gap through the conversion of monocular video into realistic and interactive 3D simulation environments. This framework addresses fundamental limitations of traditional simulation methods by integrating neural scene reconstruction techniques to foster robust training environments for reinforcement learning (RL) agents in urban navigation scenarios.
Framework Overview
Vid2Sim comprises a comprehensive pipeline for transforming real-world video footage into high-quality simulation spaces optimized for agent training. This process can be divided into two principal stages: geometry-consistent scene reconstruction and interactive simulation environment construction.
Geometry-Consistent Scene Reconstruction
Given the input video, Vid2Sim utilizes a monocular geometry-consistent reconstruction approach to enhance 3D scene building precision. Leveraging depth estimation techniques, the framework introduces scale-invariant losses that stabilize scene depth and normals during reconstruction, ensuring finer geometric detailing.
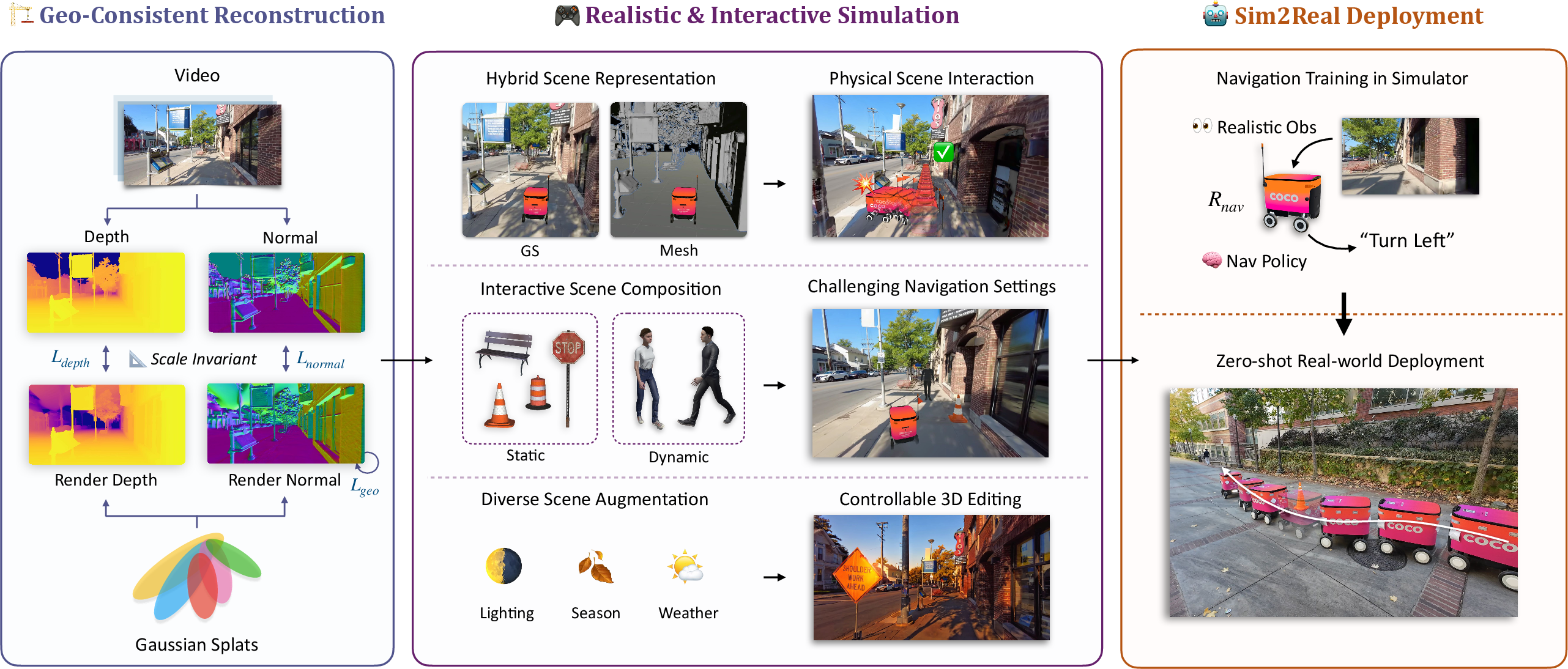
Figure 1: Vid2Sim framework consists of three key stages: (1) Geometry-consistent reconstruction for high-quality environment creation, (2) building a realistic and interactive simulation with hybrid scene representation and diverse obstacle and scene augmentation for visual navigation training, and (3) Sim2Real validation through real-world deployment.
The geometry-consistent loss applies smoothness constraints on contiguous surface normals, thereby preserving structural integrity even in regions of subtle depth change. These mechanisms collectively lead to superior reconstructions that can underpin dynamic interactions within the simulation.
Building Realistic and Interactive Simulations
Vid2Sim innovates by introducing hybrid scene representations. By amalgamating Gaussian Splatting (GS) with mesh primitives, the framework achieves photo-realistic visualizations alongside robust physical interactions essential for agent training. GS offers real-time, high-fidelity visual outputs, while mesh primitives facilitate accurate collision detection.

Figure 2: Interactive Scene Composition with Vid2Sim: Our method is able to combine reconstructed environments with 3D assets to create diverse simulation scenarios. Here we show the (a) original real2sim environment, (b) interactive scene composition with static and dynamic obstacles, (c) scene mesh for physical collision detection, (d) agent's RGB observations, and (e) depth rendering from our hybrid scene representation that could serve as an extra sensory modality.
To mimic real-world navigation complexities, Vid2Sim integrates static and dynamic obstacles within its simulation environments. Static objects, such as traffic cones and bins, and dynamically moving pedestrians create realistic challenges for navigating agents. Scene augmentation techniques further diversify these environments, simulating lighting variations and weather conditions.
Vid2Sim demonstrates significant improvements over traditional methods, achieving enhanced success rates and reduced collision instances in simulated and real-world tests. In controlled experiments, Vid2Sim agents outperformed mesh-based simulation counterparts, evidencing improved generality across diverse urban settings.

Figure 3: Scene augmentation with various overall stylization
Strong performance metrics including Success Rate (SR) and Success Rate weighted by Path Length (SPL) showcase Vid2Sim's proficiency in generating effective training environments conducive to sim-to-real transferability.
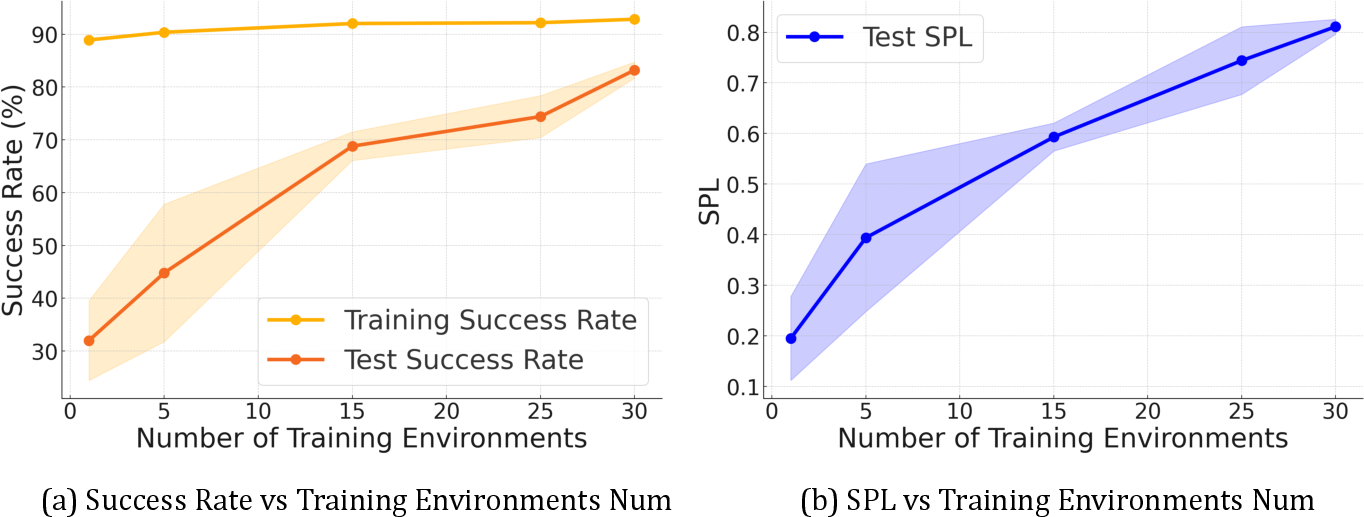
Figure 4: Generalization Results: This table compares (a) the success rate (SR) and (b) success rate weighted by path length (SPL) across varying numbers of training environments. Increasing the number of training environments leads to a higher test success rate and SPL, which indicates improved agents generalizability.
Sim-to-Real Transfer
Vid2Sim achieves remarkable sim-to-real transitions, maintaining robust agent performance across a variety of real-world scenarios. Without further tuning, agents trained in Vid2Sim environments exhibited competent navigation abilities when deployed in actual urban settings.

Figure 5: Real-world experiment settings
Conclusion
Vid2Sim stands as a significant advancement in AI-driven urban navigation, offering a scalable solution for simulating real-life environments from casual monocular videos. By reducing the sim-to-real gap, Vid2Sim provides pathways for developing generalizable navigation strategies applicable to diverse embodied agents. Future work could focus on scaling the Vid2Sim pipeline to accommodate more varied scenes to bolster agent robustness further.