- The paper presents a novel prompt-driven TTS framework that integrates emotion and intensity encoders into the FastSpeech 2 architecture.
- It employs LLM-based prompt control with HuBERT feature extraction to adjust prosody at both global and local levels, enhancing speech expressiveness.
- The framework outperforms competing models with improved emotion classification accuracy and minimal distortion, as confirmed by both objective metrics and human evaluations.
PROEMO: Prompt-Driven Text-to-Speech Synthesis Based on Emotion and Intensity Control
Introduction
The advancement in speech synthesis has transitioned from statistical techniques to deep learning methodologies, enabling the generation of text-to-speech systems that are increasingly realistic and humanlike. While these systems have achieved a high degree of naturalness, the replication of expressive qualities such as emotion, intonation, and speaking style remains a significant challenge. The paper "ProEmo: Prompt-Driven Text-to-Speech Synthesis Based on Emotion and Intensity Control" (2501.06276) addresses this challenge by proposing a framework for expressive speech synthesis using prompt-based methods to control emotions and intensity across multiple speakers. This synthesis approach leverages LLMs to manipulate speech prosody, integrating emotional and intensity cues via embeddings, resulting in enhanced expressiveness and variability in speech.
Methodology
The core of the proposed framework involves augmenting the FastSpeech 2 (FS2) architecture by incorporating emotion and intensity encoders. This enhances the naturalness and expressiveness of synthesized speech. The pipeline consists of several stages, including multispeaker TTS backbone pre-training, followed by the integration of emotion and intensity encoders during fine-tuning. The framework utilizes HuBERT for feature extraction, with distinct heads dedicated to emotion classification and intensity regression.
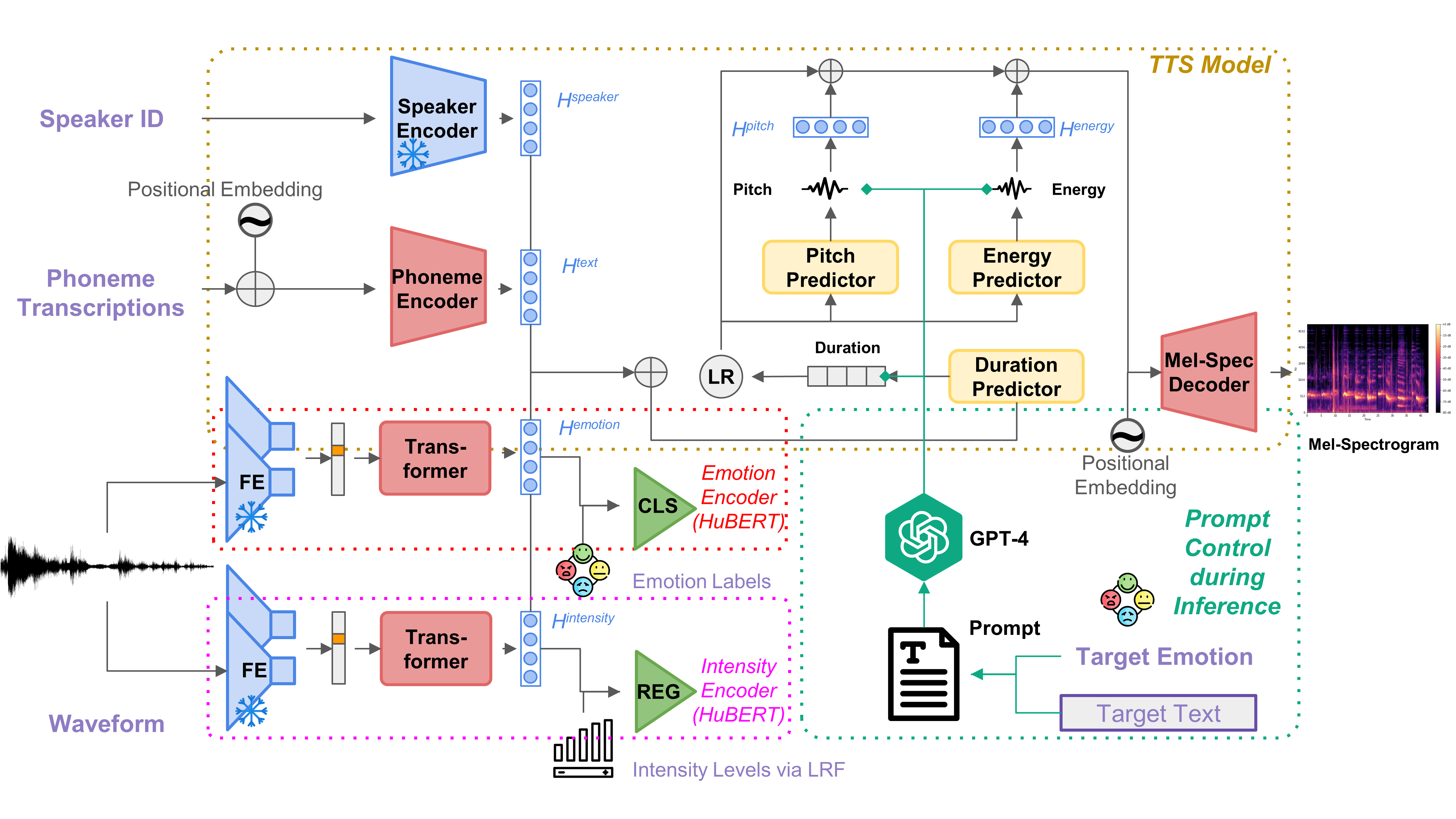
Figure 1: Overview of proposed expressive speech generation framework composed of 4 modules: TTS backbone based on FS2, HuBERT for Emotion Encoder, HuBERT for Intensity Encoder, GPT-4 Prompting for prosody control.
The introduction of prompt control, using LLM-based global and local modifications, allows fine-tuned control over prosody at both the utterance and word levels. These modifications ensure that the synthesized speech maintains a desired emotional tone while adjusting subtleties in pitch, duration, and energy for expressive effects.
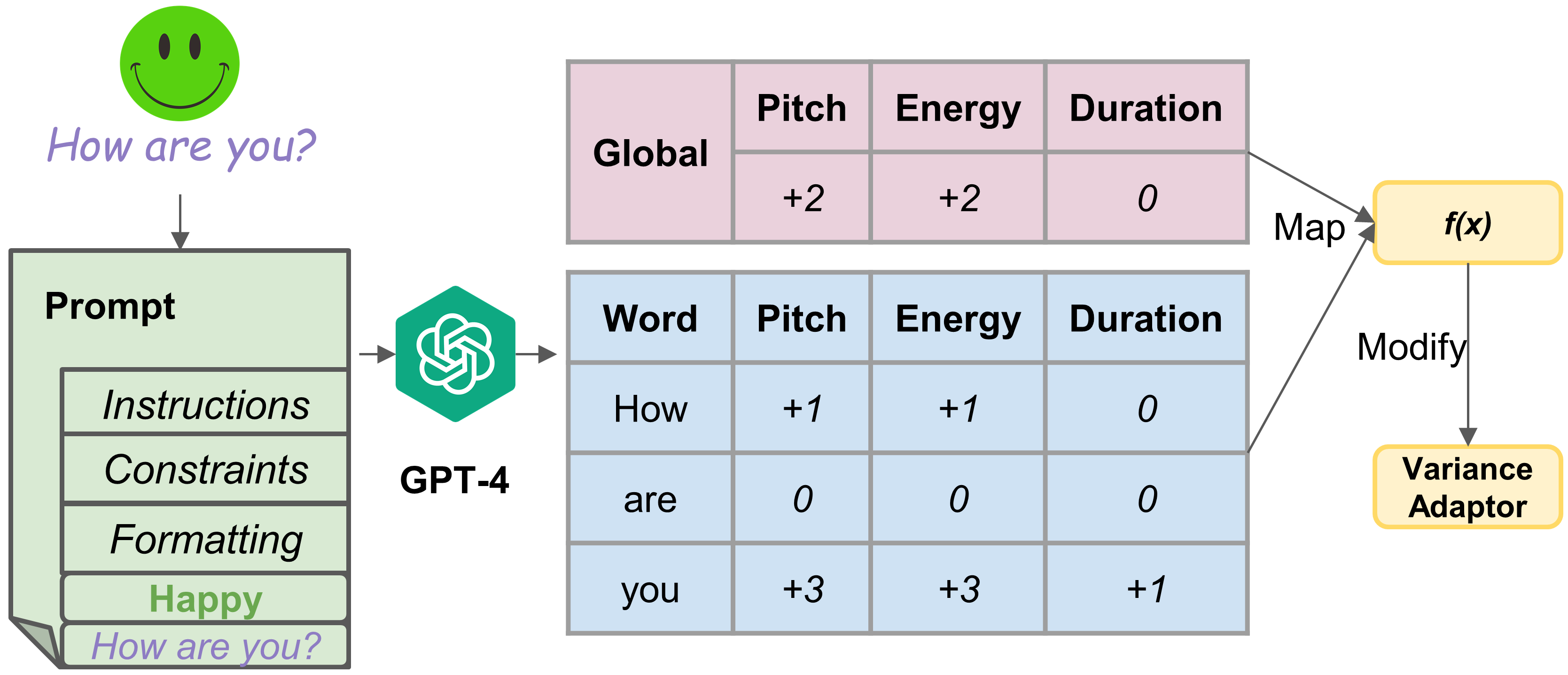
Figure 2: Introduction to Prompt Control: The scaling factors suggested by the LLM directly affect the Variance Adaptor.
Experimental Setup
The experiments leverage datasets such as LibriTTS and the Emotional Speech Database (ESD) to pre-train and fine-tune the FS2 model. The evaluation spans different configurations, testing the incorporation of emotion and intensity encoders as well as the implementation of prompt controls. Metrics such as Emotion Classification Accuracy (ECA), Mel Cepstral Distortion (MCD), Word Error Rate (WER), and Character Error Rate (CER) are used to objectively assess speech synthesis quality and expressiveness. Human subjective tests, including Mean Opinion Score (MOS) and Perceptual Intensity Ranking (PIR), corroborate the objective findings by assessing perceived expressiveness and intensity levels.
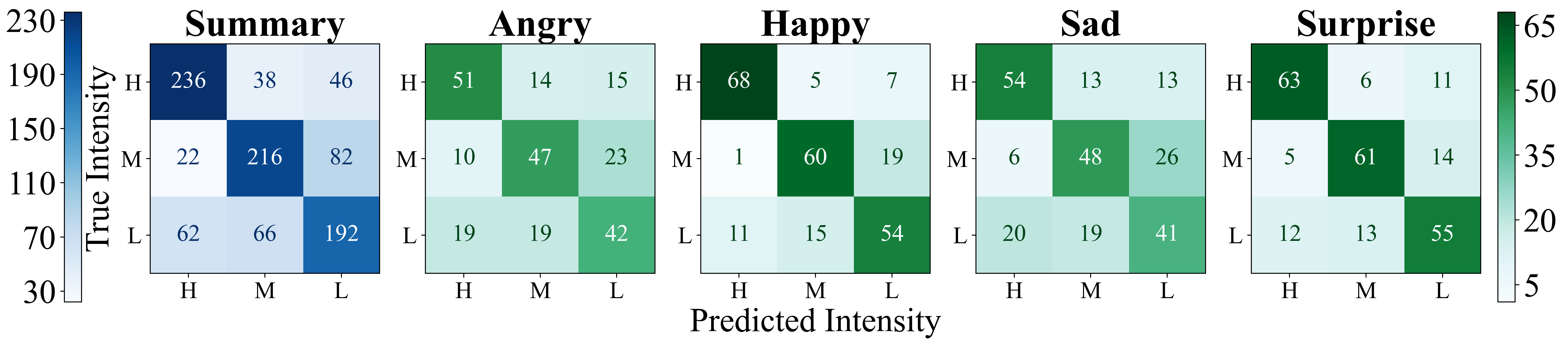
Figure 3: Perceptual Intensity Ranking. H,M,L: High, Medium and Low intensities.
Results
The incorporation of emotion and intensity embeddings notably enhances emotion classification accuracy in generated speech. FS2 models with added encoders consistently outperform simpler configurations and competing architectures like Daft-Exprt, showcasing superior expressiveness, particularly when employing local-level prompt control. Objective metrics reveal minimal impact on speech distortion, indicating efficient integration of additional encoders without degradation. Human evaluations support these findings, highlighting improvements in perceived expressiveness and coherence.
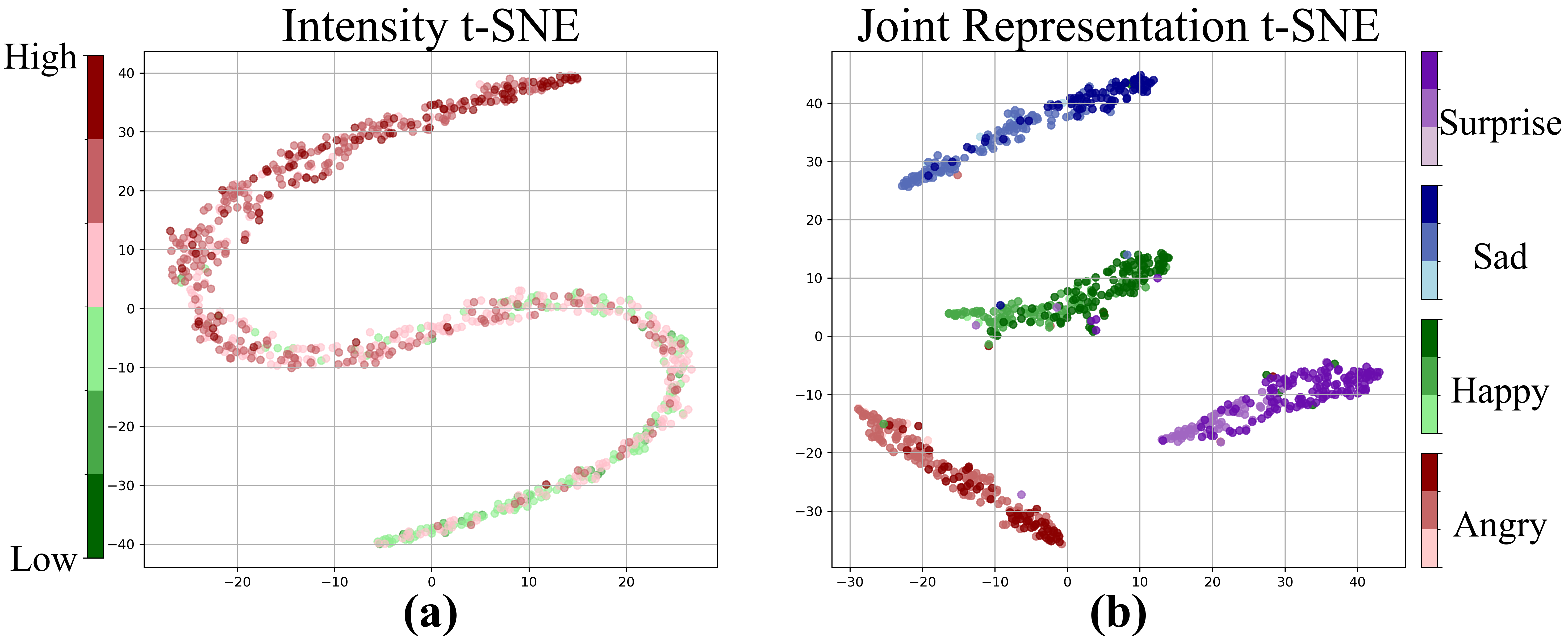
Figure 4: t-SNE of embeddings for the ESD validation set. (a) Intensity embeddings computed using the relative ranking function, r(.). (b) Joint emotion and intensity embeddings.
Conclusion
The presented architecture and methodology provide a substantive advancement in the field of expressive speech synthesis, demonstrating the potential for LLM-driven, prompt-based control to elevate the naturalness and variability of artificial speech. Through collaborative use of emotion and intensity encoders, along with refined prompt control mechanisms, the framework successfully models nuanced emotional expression in synthesized speech. Future research can extend these exploration pathways into multilingual contexts, real-time applications, and robustness across diverse emotional cue settings.